Az RDF Erőforrás Leíró Nyelv (Resource Description Framework) egy
adatleíró nyelv, amellyel erőforrásokról szóló információkat ábrázolhatunk a
weben. E bevezető tankönyv célja az, hogy ellássa az olvasót az RDF hatékony
alkalmazásához szükséges alapvető ismeretekkel. Ebből a célból bevezetést
nyújt az RDF alapfogalmaiba, és ismerteti ennek XML szintaxisát. Leírja, hogy
miként definiálhatunk RDF szókészleteket az RDF Szókészlet Leíró Nyelv
segítségével, és áttekintést ad néhány működő RDF alkalmazásról. Emellett
ismerteti az RDF specifikációjához tartozó többi dokumentum célját és
tartalmát is.
1. Bevezetés
Az RDF (Resource Description Framework) egy adatleíró nyelv, amellyel
erőforrásokról szóló információkat ábrázolhatunk a weben. Ezt elsősorban
erőforrásokkal összefüggő meta-adatok ábrázolása céljára fejlesztették ki,
mint pl. cím, szerző, a weblap utolsó módosításának időpontja, a
webdokumentum szerzői jogi- és licenc-információi, vagy a közös erőforrások
hozzáférhetőségi időrendje. Emellett, az "erőforrás" fogalmának
általánosítása útján, az RDF képes minden olyan dologról szóló információ
ábrázolására, mely azonosítható a weben, akkor is, ha az közvetlenül
nem elérhető. Ilyen információ lehet például az elektronikus
kereskedelemben forgalmazott áruk specifikációja, ára és hozzáférhetősége,
vagy ilyen információ lehet egy Web felhasználó információtovábbítási
preferenciáinak a leírása.
Az RDF-et olyan esetekre tervezték, amelyekben az efféle információkat nem
(csak) emberek számára kell megjeleníteni, hanem számítógép-programok
segítségével (is) fel kell dolgozni. Az RDF olyan egységes keretet biztosít
az ilyen adatok kifejezésére, amelyben azok információveszteség és
jelentéstorzulás nélkül átvihetők egyik alkalmazásból a másikba. Mivel ez a
keret általános, az alkalmazások fejlesztői kihasználhatják a közös RDF
szintaxiselemző és feldolgozó eszközök előnyeit. A különböző alkalmazások
közötti információcsere lehetősége pedig azt jelenti, hogy nemcsak azok az
alkalmazások használhatják az információt, amelyek számára azt eredetileg
ábrázolták, hanem a más célokra készült, későbbi alkalmazások is jól
hasznosíthatják.
Az RDF arra az elvre épül, hogy a dolgokat webes azonosítók, un.
egységes erőforrás-azonosítók (angolul: Uniform Resource Identifier,
vagy URI) segítségével azonosíthatjuk, és egyszerű tulajdonságokkal és
tulajdonságértékekkel leírhatjuk. Ez lehetővé teszi az RDF számára, hogy az
erőforrásokkal kapcsolatban egyszerű állításokat ábrázolhassunk gráf
formájában, ahol a csomópontok és az élek az erőforrásokat, ezek
tulajdonságait és a tulajdonságok értékeit reprezentálják.
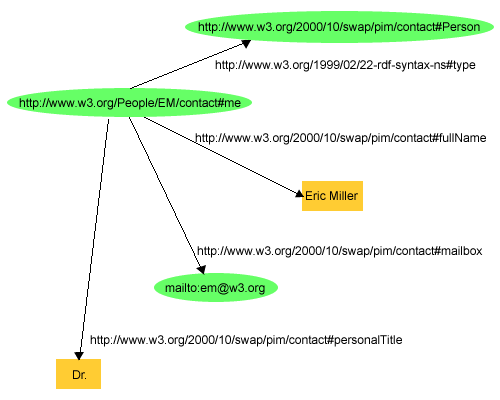
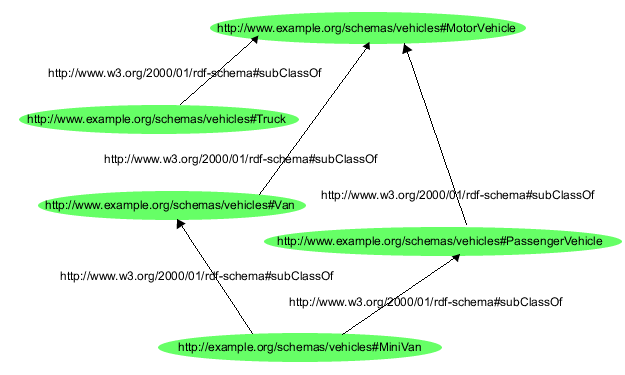
Hogy az eddig megismert elveket minél hamarabb konkretizálhassuk,
példaképpen vizsgáljuk meg, hogyan ábrázoljuk az alábbi kijelentéseket az 1. ábrán szereplő gráf segítségével:
"Adott egy alany, amelynek típusa: személy, az azonosítója
http://www.w3.org/People/EM/contact#me, a neve Eric
Miller, a postaláda-címe: em@w3.org, és a személyi címe
Dr.":
Az 1. ábra azt illusztrálja, hogy miként használja
az RDF az URI-ket az egyes dolgok azonosítására:
- Az egyedeket, itt konkrétan Eric Miller-t, pl. így azonosítja:
http://www.w3.org/People/EM/contact#me
- A dolgok fajtáit, itt konkrétan a személy kategóriát pedig
így:
http://www.w3.org/2000/10/swap/pim/contact#Person
- A dolgok tulajdonságait, itt konkrétan a postaláda-címe
tulajdonságot így:
http://www.w3.org/2000/10/swap/pim/contact#mailbox
- A dolgok tulajdonságértékeit, itt konkrétan a
mailto:em@w3.org címet pedig, mint a postaláda-címe
tulajdonság értékét, szöveg-adat formájában adtuk meg. (A tulajdonságok
értékeként az RDF megadhat karakterláncokat, mint pl. "Eric Miller", és
más adattípusok értékeit is, mint pl. egész számok vagy dátumok.)
Az RDF egy XML alapú szintaxissal írja le ezeket a gráfokat, és ugyanilyen
szintaxis formájában történik a gráfok átvitele is az alkalmazások között
(ezt RDF/XML szintaxisnak nevezzük). Az 1. példa egy
RDF kódrészletet tartalmaz, mely az 1. ábra
tartalmának felel meg:
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:contact="http://www.w3.org/2000/10/swap/pim/contact#">
<contact:Person rdf:about="http://www.w3.org/People/EM/contact#me">
<contact:fullName>Eric Miller</contact:fullName>
<contact:mailbox rdf:resource="mailto:em@w3.org"/>
<contact:personalTitle>Dr.</contact:personalTitle>
</contact:Person>
</rdf:RDF>
Figyeljük meg, hogy ez a kódrészlet tartalmaz komplett URI-ket, valamint
olyan tulajdonságokat, amelyeket rövidített formában azonosítottunk (pl.
mailbox és fullName), továbbá tartalmazza e két
tulajdonság megfelelő értékeit (em@w3.org, illetve Eric
Miller).
Ugyanúgy, mint a HTML, az RDF/XML is géppel feldolgozható, és URI-k
felhasználásával képes összekapcsolni az információkat a weben keresztül. De
eltérően a hagyományos hiperszövegtől, az RDF URI-jei minden azonosítható
dologra hivatkozhatnak, beleértve az olyanokat is, amelyek esetleg
közvetlenül nem visszakereshetők a weben (mint például az élő személy, akit
Eric Miller-nek hívnak). Ennek a haszna az, hogy amellett, hogy le tudunk
írni olyan dolgokat, mint a weblapok, az RDF-fel le tudunk írni autókat,
cégeket, embereket, híreseményeket, vagy bármi mást. Továbbá, az RDF-ben a
tulajdonságoknak maguknak is van URI-jük amellyel pontosan azonosítani lehet
azt a viszonyt, ami a tulajdonsággal összekapcsolt dolgok között fennáll.
Az alábbi dokumentumok mind fontos részei az RDF specifikációjának (az
indirekt hivatkozások linkjeit szögletes zárójelben szerepeltetjük):
A tankönyv célja az, hogy bevezetést nyújtson az RDF-be, és leírjon néhány
létező RDF alkalmazást, hogy ezzel is segítse a rendszertervezőket és az
alkalmazásfejlesztőket az RDF lehetőségeinek megértésében és alkalmazásában.
Ennek megfelelően, ennek a tankönyvnek meg kell válaszolnia az ilyen
kérdéseket:
- Miből is áll az RDF,
- Milyen információkat tud az RDF ábrázolni,
- Hogyan lehet RDF-ben az információt leírni, elérni és feldogozni,
- Hogyan lehet a meglévő információt az RDF adatokkal kombinálni
Ez a tankönyv egy "nem normatív" dokumentum, ami azt jelenti, hogy nem ad
egy definitív specifikációt az RDF-ről. A példák és más magyarázó anyagok
csupán arra szolgálnak, hogy megkönnyítsék az olvasó számára az RDF
megértését, de ezek nem mindig nyújtanak definitív, vagy teljesen komplett
megoldásokat. Ilyen esetekben az RDF specifikáció normatív részeit célszerű
elővenni. Hogy ehhez kellő segítséget adjon, a tankönyv ismerteti a többi
dokumentum szerepét a teljes specifikációban, továbbá olyan linkeket
tartalmaz a különböző témákat tárgyaló szövegrészekben, amelyek a normatív
specifikációk megfelelő helyeire mutatnak.
Azt is meg kell jegyezni, hogy ezek az RDF dokumentumok módosítják és
helyesbítik néhány korábban publikált RDF
specifikáció tartalmát; ilyenekét, mint a Resource
Description Framework (RDF) Model and Syntax Specification [RDF-MS] és a Resource Description
Framework (RDF) Schema Specification 1.0 [RDF-S]. Ennek eredményeként néhány változás történt a
terminológia, a szintaxis és a fogalmak területén. A tankönyv mindig az RDF
specifikációk újabb változatára hivatkozik (ezek felsorolását lásd a fenti
listában). Ezért azok az olvasók, akik ismerik a korábbi specifikációkat, és
az ezeken alapuló oktató és bevezető anyagokat, számítsanak arra, hogy
különbségek lehetnek a jelenlegi specifikációk és a korábbi dokumentumok
között. Az RDF témák nyomkövető dokumentuma (RDF Issue Tracking) [RDFISSUE] tartalmaz egy listát azokról a
problémákról, amelyek az előző RDF specifikációkkal kapcsolatban felmerültek,
megadva azt is, hogy ezek miként oldódtak meg a jelenlegi
specifikációkban.
2. Kijelentések megfogalmazása
erőforrásokról
Az RDF-et arra tervezték, hogy segítségével egyszerű módon fogalmazhassunk
meg kijelentéseket a Web erőforrásairól (röviden: webforrásokról), például
weblapokról. Ez a szekció ismerteti azokat az alapelveket, amelyek alapján az
RDF nyújtja ezeket a képességeket. (Az a normatív specifikáció, mely leírja
ezeket az alapelveket, Az RDF
alapfogalmai és absztrakt szintaxisa – [RDF-FOGALMAK] dokumentumban található) .
2.1 Alapfogalmak
Képzeljük el, hogy ki akarjuk jelenteni egy adott weblapról, hogy annak
szerzője egy bizonyos John Smith. A hagyományos formája ennek az, hogy
valamely természetes nyelven, pl. angolul, nyílt szöveggel megfogalmazzuk
ezt:
http://www.example.org/index.html
has a creator whose value is John
Smith
(Magyarul: A http://www.example.org/index.html URL-en
elérhető weblapnak van egy szerzője nevű tulajdonsága,
amelynek értéke John Smith.)
A kijelentés egyes részeit kövér szedéssel hangsúlyoztuk, hogy
illusztráljuk: ha le akarjuk írni valaminek a tulajdonságait, szükséges, hogy
megnevezzünk, vagy azonosítsunk néhány dolgot:
- azt a dolgot, amelyről a kijelentés szól (esetünkben ez a
weblap)
- annak a dolognak egy meghatározott tulajdonságát, amelyről a kijelentés
szól (esetünkben szerzője vagy kreátora)
- azt a dolgot, amely a kijelentés szerint a tulajdonság értéke (value),
vagyis esetünkben a weblapkészítő nevét.
Azt a weblapot, amelyről az állítás szól, a weblap URL-jével, azaz
egységes webforrás-címével azonosítottuk. A "szerzője" (creator) kifejezést
használtuk a tulajdonság azonosítására, a "John Smith" szövegadatot pedig
annak a dolognak az azonosítására, mely a "szerzője" tulajdonság értéke.
Ennek a weblapnak a többi tulajdonságait is leírhatnánk hasonló angol
nyelvű mondatokkal, ahol szintén az URL-lel azonosítanánk a weblapot, és
szavakkal vagy kifejezésekkel a tulajdonságokat, és ezek értékeit. Például
azt a dátumot, amikor a lapot készítették (creation-date), és azt a nyelvet
(language), amelyen íródott, az alábbi mondatokkal lehetne leírni:
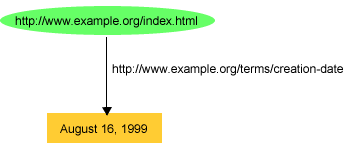
http://www.example.org/index.html
has a creation-date whose value is August 16,
1999
http://www.example.org/index.html has a
language whose value is English
Az RDF arra az elvre épül, hogy a leírásra kerülő dolognak több tulajdonsága, a
tulajdonságoknak pedig értéke van, és hogy az erőforrások leírhatók a
fentiekhez hasonló kijelentésekkel, amelyek specifikálják az erőforrások
tulajdonságait és a tulajdonságok értékeit. Az RDF egy meghatározott
terminológiát használ az ilyen kijelentő mondatok különböző részeinek a
megnevezésére. Például a mondatnak azt a részét, amelyik azt azonosítja,
akiről/amiről az állítás szól, alanynak nevezi (a
példánkban ez a weblap). Azt a részt, amelyik az alany tulajdonságait,
jellemzőit azonosítja (a példánkban creator, creation-date,
language), állítmánynak, és azt
a részt, amelyik e tulajdonságok értékeit azonosítja, tárgynak nevezi. Így
tehát az alábbi angol mondatban:
http://www.example.org/index.html
has a creator whose value is John
Smith
az RDF kifejezések, amelyek a mondat egyes részeit leírják, az
alábbiak:
- az alany (subject) a
http://www.example.org/index.html URL
- az állítmány (predicate) a "creator" szó
- a tárgy (object) a "John Smith" kifejezés
De amíg az Angol két (angolul tudó) ember közötti kommunikációra szolgál,
az RDF géppel feldolgozható állítások megfogalmazására készült.
Ahhoz, hogy az ilyen állításokat gépi feldolgozásra alkalmassá tegyük, két
dologra van szükségünk:
- olyan, géppel feldolgozható azonosítók rendszerére, amelyek alkalmasak
az alany, az állítmány és a tárgy azonosítására anélkül, hogy a gép
összetévesztené ezeket olyan, hasonló kinézésű azonosítókkal, amelyeket
esetleg mások használnak a weben
- olyan, géppel feldolgozható nyelvre, amelyen a kijelentések egzakt
módon ábrázolhatók és a gépek között kicserélhetők.
Szerencsére, a Web meglévő architektúrája mindkét szükséges eszközt
tartalmazza.
Mint korábban bemutattuk, a weben már rendelkezésre áll az azonosító egy
formája, az URL (az egységes webforrás-cím). Az első példában URL-t
használtunk annak a weblapnak az azonosítására, amelyet John Smith készített.
Az URL egy karakterlánc, mely oly módon azonosítja a webforrást, hogy
ábrázolja annak elsődleges hozzáférési mechanizmusát (lényegében a hálózati
címét). Ám az RDF-ben szükséges, hogy információkat adhassunk meg sok olyan
dologról is, amelynek nincs hálózati címe (URL-je).
A weben rendelkezésre áll az azonosításnak egy még általánosabb formája
ilyen célokra, amelyet Egységes Erőforrás-azonosítónak (Uniform Resource
Identifier-nek vagy URI-nek) nevezünk. Az URL az URI egy specifikus
fajtája. Minden URI rendelkezik azzal a tulajdonsággal, hogy különböző
személyek vagy szervezetek egymástól függetlenül kreálhatnak ilyeneket, és
ezeket bárminek az azonosítására használhatják. Az URI-k nincsenek arra
korlátozva, hogy csak olyan dolgokat azonosítsanak, amelyek hálózati címmel
rendelkeznek, vagy amelyek számítógépes hozzáférési mechanizmust
feltételeznek. Valójában kreálhatunk egy URI-t bárminek az azonosítására,
amelyre hivatkozni szeretnénk egy kijelentésben, beleértve:
- a hálózaton azonosítható dolgokat, mint pl. egy elektronikus
dokumentum, egy kép, egy szolgáltatás (pl ."A mai időjárás-előrejelzés
Los Angeles területére"), vagy erőforrások egy csoportja;
- az olyan dolgokat, amelyek hálózaton keresztül nem elérhetők, mint pl.
emberek, cégek, vagy a könyvtárak papír alapú könyvei;
- az elvont fogalmakat, amelyek fizikailag nem is léteznek, mint például
"szerző".
Ez a nagyobb általánosság indokolja, hogy az RDF URI-ket használ annak a
mechanizmusnak az alapjaként, amellyel az állítások alanyát, állítmányát és
tárgyát azonosítja. Szabatosabban fogalmazva: az RDF URI
hivatkozásokat ([URIS]) használ. Egy URI
hivatkozás (vagy URIref) egy URI egy opcionális
erőforrásrész-azonosítóval (fragment identifier-rel) a végén.
Például a http://www.example.org/index.html#section2 URI
hivatkozás URI-je: http://www.example.org/index.html,
erőforrásrész-azonosítója pedig a "#" karakterrel elválasztott
Section2 azonosító. Az RDF URI hivatkozásai [UNICODE] karakterekkel vannak leírva (lásd [RDF-FOGALMAK]), lehetővé téve ezáltal, hogy
több nyelven is lehessen ilyen hivatkozásokat kreálni. Az RDF úgy definiálja
az erőforrás fogalmát, hogy az bármi lehet, ami azonosítható egy URI
hivatkozással. Így az RDF gyakorlatilag bármilyen dolgokat meg tud nevezni,
és a köztük lévő viszonyokat is le tudja írni. Az URI hivatkozások és az
erőforrásrész-azonosítók további tárgyalása megtalálható az A. függelékben, valamint az [RDF-FOGALMAK] dokumentumában.
A mondatok géppel feldolgozható módon való ábrázolásához az RDF a
Bővíthető Jelölőnyelvet (Extensible Markup
Language – [XML]) használja. Az XML-t arra
tervezték, hogy segítségével bárki kialakíthassa a saját
dokumentumformátumát, és azután meg is írhassa a dokumentumait ebben a
formátumban. Az RDF egy specifikus XML jelölőnyelvet definiál, amelyet
RDF/XML-nek nevezünk, és amelyet RDF információk ábrázolására,
illetve gépek közötti cseréjére alkalmazunk. Az 1.
fejezetben, az 1. példa kapcsán már találkoztunk
RDF/XML ábrázolással. Ebben a példában szerepelt egy
<contact:fullName>, és egy
<contact:personalTitle> teg, amelyek az Eric
Miller, illetve a Dr. szövegtartalmat határolták. Ezek a
tegek lehetővé teszik, hogy az ábrázoláskor és a feldolgozáskor a programok
megértsék a tegek által közrefogott tartalom jelentését. Az XML adattartalom,
és (bizonyos kivételekkel) a tegek is tartalmazhatnak [UNICODE] kódolású karaktereket, hogy az RDF lehetővé
tegye a különböző nyelveken megfogalmazott információ közvetlen ábrázolását.
A B. függelék további háttér-információkkal szolgál
az XML-ről általában. A specifikus XML szintaxist, amelyet az RDF-hez
használunk (RDF/XML), részletesebben a 3. fejezet
tárgyalja, és ennek normatív definíciója az [RDF-SZINTAXIS] dokumentumban található.
2.2 Az RDF modell
A 2.1 szekció már bepillantást engedett az
RDF mondat alapfogalmaiba: egyrészt az URI hivatkozások lényegébe, amelyekkel
az RDF mondatokban hivatkozott dolgokat azonosítjuk, másrészt pedig az
RDF/XML szintaxisba, amelynek segítségével, géppel feldolgozható módon lehet
ábrázolni az RDF mondatait. Erre a háttér-ismeretre támaszkodva, ez a szekció
leírja, hogy az RDF-ben miként használjuk az URI hivatkozásokat az
erőforrásokkal kapcsolatos állítások megfogalmazására. Az előző fejezetben
láttuk, hogy az RDF arra az elvre épült, hogy olyan elemi állításokat
fogalmazhassunk meg az erőforrásokról, ahol minden mondat csupán egy alanyt,
egy állítmányt, és egy tárgyat tartalmaz. Az alábbi angol nyelvű mondat:
http://www.example.org/index.html
has a creator whose value is John
Smith
egy olyan RDF mondattal ábrázolható, mely az alábbi mondatrészeket
tartalmazza:
- alany:
http://www.example.org/index.html
- állítmány:
http://purl.org/dc/elements/1.1/creator
- tárgy:
http://www.example.org/staffid/85740
Figyeljük meg, hogy itt az eredeti mondatnak nemcsak az alanyát, de az
állítmányát és a tárgyát is egy-egy URI-vel ábrázoltuk ahelyett, hogy a
"creator", illetve a "John Smith" szavakat használtuk volna. (Az URI ilyen
használatának hatásait később tárgyaljuk ebben a szekcióban.)
Az RDF az állításokat egy gráf csomópontjaival és éleivel modellezi. Az
RDF gráfmodelljét az
[RDF-FOGALMAK] dokumentum ismerteti bővebben.
Ebben a modellben egy kijelentést az alábbi módon ábrázolunk:
- egy csomopont jelöli az alanyt
- egy másik csomópont a tárgyat
- egy él pedig az állítmányt (az él mindig az alany csomóponttól
a tárgy csomópont felé mutat).
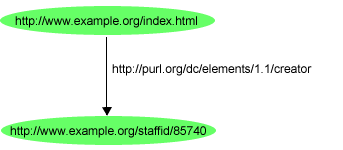
Ennek megfelelően, a fenti RDF mondatot a 2. ábrán
szereplő gráffal ábrázolhatjuk:
Ehhez hasonló állítások csoportját is ugyanígy, a nekik megfelelő
csomópontokkal és élekkel ábrázolhatjuk. A korábbi példákból ismert másik két
angol mondatot:
http://www.example.org/index.html
has a creation-date whose value is August 16,
1999
http://www.example.org/index.html has a
language whose value is English
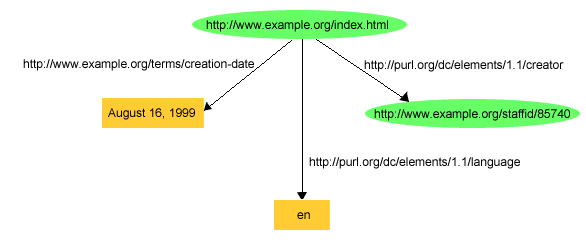
a 3. ábrán szereplő gráf-részlettel lehetne
ábrázolni, amelyben megfelelő URI hivatkozásokat használunk a "creation-date"
és a "language" tulajdonságok azonosítására:
A 3. ábra azt is illusztrálja, hogy az RDF
kijelentéseinek tárgyai egyaránt lehetnek URI hivatkozások és konstans
értékek (ún. literálok). Ez
utóbbiakat olyan karakterláncokkal ábrázoljuk, amelyek a tulajdonságok
értékeit reprezentálják. (A
http://purl.org/dc/elements/1.1/language tulajdonság esetében a
literál egy nemzetközi szabvány szerinti kétbetűs kód, mely egyezményesen az
Angolt jelenti. Literálokat azonban nem használhatunk az RDF állítások
alanyaként vagy állítmányaként. Az RDF gráfok megrajzolásakor azokat a
csomópontokat, amelyeket URI-vel azonosítunk, ellipszissel ábrázoljuk, míg az
olyan csomópontokat, amelyeket literállal adunk meg, szögletes dobozok
reprezentálják. (Azokat az egyszerű karakterlánc-literálokat, amelyeket ebben
a példában használtunk, típus nélküli
literáloknak (plain literals) nevezzük, megkülönböztetésül a tipizált
literáloktól (typed literals), amelyek ismertetésére majd a 2.4 szekcióban kerül sor. A különböző
literáltípusokat, amelyeket az RDF-ben használhatunk, az [RDF-FOGALMAK] dokumentuma definiálja. Mind a
tipizált, mind a típus nélküli literálok megadhatók [UNICODE] kódolású karakterekkel, hogy lehetővé
váljék a különböző nyelveken megfogalmazott információk közvetlen
ábrázolása.
Sokszor nem az a legalkalmasabb ábrázolás, hogy gráfokat rajzolunk, amikor
még vitatjuk a tartalmukat. Van egy alternatív módja is az állítások
leírásának: a tripletek módszere
(triples). A tripletekkel történő ábrázolás során a gráfban szereplő minden
kijelentést egy egyszerű alany-állítmány-tárgy hármassal írunk le, ebben a
sorrendben. Például a 3. ábrán szereplő három állítást
a tripletek módszerével így jegyeznénk le:
<http://www.example.org/index.html> <http://purl.org/dc/elements/1.1/creator> <http://www.example.org/staffid/85740> .
<http://www.example.org/index.html> <http://www.example.org/terms/creation-date> "August 16, 1999" .
<http://www.example.org/index.html> <http://purl.org/dc/elements/1.1/language> "en" .
Minden triplet egy-egy olyan él a gráfban, mely egy kezdő-, és egy
végcsomóponttal rendelkezik (ez a kijelentés alanya és tárgya). Szemben a
rajzolt gráffal, de hasonlóan az eredeti kijelentésekhez, a tripletes írásmód
megkívánja, hogy a megfelelő csomópontokat külön-külön azonosítsuk minden
kijelentésben, amelyben megjelennek. Így tehát, például, a
http://www.example.org/index.html azonosító háromszor is
megjelenik, ha tripletekkel ábrázoljuk a gráfot, míg a rajzolt gráf esetében
csak egyszer. Ennek ellenére a tripletek pontosan ugyanazt az információt
reprezentálják, mint a rajzolt gráf. És ez egy kulcskérdés. Ami ugyanis
alapvető az RDF-ben, az a kijelentések gráfmodellje. Az a konkrét
mód, azonban, ahogyan leírjuk, vagy lerajzoljuk a gráfmodellt, csupán
másodlagos.
A komplett tripletes írásmód azt igényli, hogy az URI hivatkozásokat
hegyes zárójelek között, teljes terjedelmükben kiírjuk, ám ez, mint a fenti
példa is mutatja, nagyon hosszú mondatokat eredményez a lapon. Ennek
elkerülése céljából (és kényelmi okokból is), ebben a tankönyvben a tripletek
URI hivatkozásainak egy rövidített formáját használjuk (ugyanezt a rövidített
formát alkalmazza a többi RDF dokumentum is). Itt a rövidítés egy XML
minősített név (qualified name, vagy Qname) használatát
jelenti, hegyes zárójelek nélkül, mely az URI hivatkozás egy rövidített
változatának felel meg. (A minősített neveket a B.
függelék tárgyalja részletesebben). A minősített név egy előtét-nevet
(ún. prefixet) tartalmaz, mely egy névtér URI-hez van rendelve. A
prefixet egy kettőspont, majd pedig egy helyi név követi. A teljes URI
hivatkozást a minősített névből úgy állítjuk vissza, hogy egy lokális nevet
toldunk ahhoz a névtér URI-hez, mely a prefixhez van rendelve. Így tehát, ha
pl. a foo prefix a http://example.org/somewhere/
névtér-URI-hez van rendelve, akkor a foo:bar minősített névre
rövidül le a http://example.org/somewhere/bar URI hivatkozás.
Tankönyvünk példái több "jól ismert" minősítettnév-prefixet használnak
anélkül, hogy ezeket minden egyes alkalommal explicit módon definiálnák. Az
ilyen prefixeket és az előre hozzájuk rendelt névtér-URI-ket az alábbi lista
tartalmazza:
prefix = rdf:, névtér-URI =
http://www.w3.org/1999/02/22-rdf-syntax-ns#
prefix = rdfs:, névtér-URI =
http://www.w3.org/2000/01/rdf-schema#
prefix = dc:, névtér-URI =
http://purl.org/dc/elements/1.1/
prefix = owl:, névtér-URI =
http://www.w3.org/2002/07/owl#
prefix = ex:, névtér-URI = http://www.example.org/
(vagy .com )
prefix = xsd:, névtér-URI =
http://www.w3.org/2001/XMLSchema#
A listában szereplő ex: prefixnek, mely az "example"
kifejezés rövidítése, és amelyet a példáinkban általánosan használunk, több
variánsa is meg fog jelenni a tankönyvünkben. Az adott példa jellege szerint
ezek általában ilyenek, mint:
prefix = exterms:, névtér-URI =
http://www.example.org/terms/ (olyan fogalmak
névtér-azonosítójaként, amelyeket egy példabeli szervezet használ),
prefix = exstaff:, névtér-URI =
http://www.example.org/staffid/ (olyan kifejezések
névtér-azonosítójaként, amelyek egy szervezet személyi azonosítói),
prefix = ex2:, névtér-URI =
http://www.domain2.example.org/ (egy második példabeli szervezet
fogalmainak névtér-azonosítójaként), és így tovább.
Ezzel a rövidítési mechanizmussal az előző három, hosszú tripletet így
írhatjuk:
ex:index.html dc:creator exstaff:85740 .
ex:index.html exterms:creation-date "August 16, 1999" .
ex:index.html dc:language "en" .
Láttuk, hogy az RDF, szavak helyett,
URI hivatkozásokat használ a kijelentésekben szereplő dolgok megnevezésére.
Az URI-k egy meghatározott halmazát – különösen, amelyik valamilyen
specifikus célra szolgál – az RDF szókészletnek (vocabulary)
nevezi. Az ilyen szókészletben szereplő URI hivatkozásokat gyakran úgy
szervezik, hogy ezek olyan minősített nevekkel legyenek ábrázolhatók, amelyek
egy közös prefixet (előtét-nevet) használnak. Vagyis, egy közös névtér-URI-t
választanak a szókészlet összes kifejezése számára, s ez tipikusan egy olyan
URI, mely annak a személynek vagy szervezetnek az ellenőrzése alatt áll,
aki/amely a szókészletet definiálta. A szókészletben szereplő URI-ket úgy
alakítják ki, hogy a közös névtér-URI végéhez egy lokális nevet toldanak. Az
ilyen URI-k azután egy olyan halmazt alkotnak, amelyek egy közös prefixszel
azonosíthatók. Például, ahogyan az előző példáknál is láttuk, egy szervezet,
mondjuk az example.org, definiálhat egy szókészletet olyan URI
hivatkozásokból, amelyek a http://www.example.org/terms/
karakterlánccal kezdődnek, s ez azoknak a kifejezéseknek a közös nevét
jelenti, amelyeket ez a szervezet saját üzleti körében használ (pl. "Gyártás
dátuma" vagy "Termék"). Ugyanez a szervezet definiálhat egy másik
szókészletet is, pl. az alkalmazottainak az azonosítóiból, amelyet a
http://www.example.org/staffid/ névtér-URI-hez kapcsol. Az RDF
ugyanezt a gyakorlatot követi, amikor egy saját szókészletet definiál olyan
kifejezésekből, amelyeknek az RDF-ben meghatározott jelentésük van. Az RDF
saját szókészletének URI-jei mind a
http://www.w3.org/1999/02/22-rdf-syntax-ns# teljes prefixszel
kezdődnek, amely konvencionálisan az rdf:
minősítettnév-prefixhez van rendelve. Az RDF Szókészlet Leíró Nyelv, amelyet
az 5. fejezet tárgyal részletesebben, definiál egy
további szókészletet is, amelynek névtér URI-je a
http://www.w3.org/2000/01/rdf-schema# , és ez hagyományosan az
rdfs: minősítettnév-prefixhez van rendelve. Egy
minősítettnév-prefixet tehát mindig egy bizonyos szókészlettel kapcsolatban
használunk, s így a prefixet gyakran az adott szókészlet nevének tekintjük
(így például az RDF Séma szókészletét úgy hívjuk, hogy "rdfs:
szókészlet".)
A közös URI prefixek használata tehát megfelelő módszer arra, hogy azokat
az URI hivatkozásokat, amelyek egy adott terminológiához kapcsolódnak, egy
közös halmazba szervezzük. Ez azonban csupán egy konvenció. Az RDF modell
csak teljes URI hivatkozásokat ismer fel; tehát nem lát bele az URI-kbe, és
nincs is tudomása ezek struktúrájáról. Még kevesebbet tud arról, hogy
valamiféle kapcsolat van ezek között azon az alapon, hogy azonos prefixet
használnak (lásd a téma további tárgyalását az A.
függelékben). Mi több, azt sem zárja ki semmi, hogy a különböző prefixű
URI hivatkozásokat egyazon szókészlet részének tekintsük. Egy adott
szervezet, folyamat, szoftvereszköz stb. definiálhat egy saját szókészletet
oly módon is, hogy felvesz a szókészletébe olyan URI hivatkozásokat, amelyek
idegen szókészletekben vannak definiálva.
Az sem ritka, hogy egy szervezet olyan webforrás URL-jeként is használja
valamelyik szókészlet névtér-URI-jét, mely további adatokat tartalmaz az
adott szókészletről. Például, mint korábban láttuk, a dc: prefix
a http://purl.org/dc/elements/1.1/ névtér-URI-hez van kapcsolva.
Ez ténylegesen a Dublin Core szókészletre hivatkozik, amelyet a 6.1 szekcióban részletezünk. Ha ezt az URI-t megadjuk
egy böngészőnek, akkor hozzáférhetünk a Dublin Core szókészlettel kapcsolatos
kiegészítő információkhoz (konkrétan egy RDF sémához). Azonban ez is csupán
egy konvenció. Az RDF nem feltételezi, hogy egy névtér-URI visszakereshető
webforrásra mutat (a B. függelékben megtalálható e
téma további diszkussziója).
Tankönyvünk további részében a szókészlet kifejezéssel mindig
olyan URI hivatkozások halmazára utalunk, amelyet valamilyen specifikus célra
definiáltak. Ilyenek pl. azok az URI hivatkozások, amelyeket az RDF a saját
használatára definiált, vagy azok, amelyeket a példákban gyakran szereplő
example.org definiált az alkalmazottai azonosítására. A
névtér kifejezést pedig a továbbiakban kizárólag akkor használjuk,
amikor specifikusan az XML névtér szintaktikai fogalmára gondolunk (vagy
amikor egy olyan URI-re hivatkozunk, amely egy minősített név prefixéhez van
rendelve).
A különböző szókészletekből származó URI hivatkozások szabadon keverhetők
az RDF gráfokban. Például a 3. ábrán szereplő gráf
három szókészletből (xterms:, exstaff: és
dc: ) használ URI hivatkozásokat. Ugyanígy, az RDF nem
korlátozza azt sem, hogy hány kijelentés
használhatja ugyanazt az URI hivatkozást állítmányként egy gráfban
ugyanannak az erőforrásnak a leírására. Például, ha az
ex:index.html weblapot John Smith-szel közösen, több szerző
készítette volna, akkor mondjuk az example.org így adhatná meg a
weblap szerzőinek a nevét:
ex:index.html dc:creator exstaff:85740 .
ex:index.html dc:creator exstaff:27354 .
ex:index.html dc:creator exstaff:00816 .
Ezek a példák talán már kezdik érzékeltetni annak az RDF elvnek néhány
előnyét, hogy alapvetően URI hivatkozásokat (röviden URIref-eket) használunk
a dolgok azonosítására. Például az első állításban, ahelyett, hogy a weblap
szerzőjének a nevét a "John Smith" karakterlánccal azonosítanánk,
hozzárendeltünk egy URI hivatkozást, mely ebben az esetben John Smith
alkalmazott-azonosítójára épül, és így néz ki:
http://www.example.org/staffid/85740. Az URIref használata ebben
az esetben például azzal az előnnyel jár, hogy a kijelentés alanyának
azonosítása pontosabb lehet. Vagyis, a szerző itt nem csupán a "John Smith"
karakterlánc, vagy bárki, a sok ezer John Smith közül, hanem egy
bizonyos John Smith, aki ehhez az URIref-hez van asszociálva (bárki
legyen is a szerző, az URIref definiálja a megfelelő asszociációt). Még
tovább menve: minthogy létezik egy URIref, amely John Smith-re hivatkozik, ő
most már egy teljes értékű erőforrás, és így további információkat is
megadhatunk róla oly módon, hogy újabb RDF kijelentéseket írunk, amelyekben
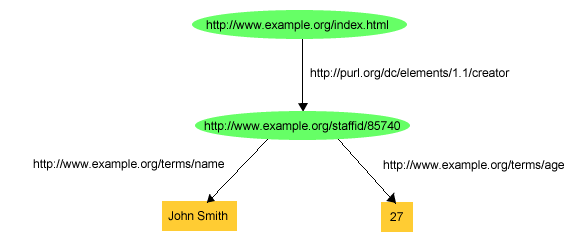
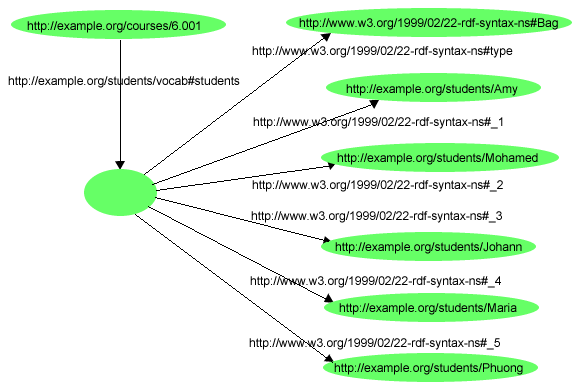
John Smith URIref-je lesz az alany. A 4. ábra további
adatokat ábrázol John Smith-ről, az index.html weblap
szerzőjéről: konkrétan a nevét (name) és az életkorát (age).
Ez a példa azt is illusztrálja, hogy az RDF kijelentésekben állítmányként
is használhatunk URI hivatkozásokat. Vagyis ahelyett, hogy ilyen szavakat,
vagy karakterláncokat használnánk itt a tulajdonságok azonosítására, mint a
"creator" és a "name", az RDF-ben inkább URI hivatkozásokat használunk ilyen
célra. Ennek a lehetősége több okból is fontos. Először is: ez egyértelműen
megkülönbözteti az egyik környezetben definiált tulajdonságot egy másik
környezetben definiálttól, amikor azonos karakterlánccal ábrázolnak
különféleképpen értelmezett tulajdonságokat. Például a 4.
ábrán bemutatott példában az example.org a "name" kifejezést használja
valakinek a teljes nevére gondolva, amelynek az értékét egy
karakterlánc-literállal írják ki (pl. "John Smith"), de valaki más a "name"
alatt esetleg egészen mást ért (pl. egy programban szereplő változó nevét).
Ha tehát egy program, amelyik több forrásból igyekszik adatokat egyesíteni, s
így több webforrásból is beolvassa a "name" karakterláncot, mint egy
tulajdonság azonosítóját, nem biztos, hogy képes lesz megkülönböztetni a két
"name" jelentését. Ha azonban az egyik szervezet, mondjuk a
http://www.example.org/terms/name URI -t használja, egy másik
pedig a http://www.domain2.example.org/genealogy/terms/name
URI-t, akkor világos, hogy itt két különböző "name" tulajdonságról van szó,
még akkor is, ha az adott program automatikusan nem tudná eldönteni a
különbözőség kérdését. Emellett a tulajdonságok URI hivatkozásokkal történő
azonosítása lehetővé teszi, hogy magukat a tulajdonságokat is erőforrásoknak
tekintsük, s így további információkat regisztrálhassunk róluk (pl. az angol
nyelvű leírását annak, hogy az example.org mit ért az alatt, hogy "name").
Ezt, a John Smith esetével analóg módon, olyan további RDF kijelentésekkel
adhatjuk meg, amelyeknek a közös alanya a "name" tulajdonság URIref-je
lesz.
Mindemellett, az URI hivatkozásoknak alanyként, állítmányként és tárgyként
történő használata az RDF kijelentésekben ösztönzi és támogatja a közös
szókészletek fejlesztését és közös használatát a weben. A fejlesztők ugyanis
így felfedezhetik, és elkezdhetik alkalmazni azokat a szókészleteket,
amelyeket mások már használnak a saját adatábrázolásaikhoz, és ez a közös
használat a fogalmak közös értelmezését is jelenti. Ha például az alábbi
triplet:
ex:index.html dc:creator exstaff:85740 .
dc:creator nevű állítmányát teljes URI hivatkozássá
terjesztjük ki, egy egyértelmű URI hivatkozást kapunk a "creator" nevű
attribútumra a Dublin Core meta-adatok halmazában. (Ez olyan attribútumok
széles körben használt gyűjteménye, amelyekkel sokféle információforrás
alapvető tulajdonságai leírhatók – ahogy azt a 6.1 szekcióban bővebben tárgyaljuk). A fenti triplet
írója lényegében azt jelenti ki, hogy a viszony a
(http://www.example.org/index.html URI-vel azonosított) weblap,
és annak meghatározott szerzője között (akit a
http://www.example.org/staffid/85740 URI azonosít), nem más,
mint az a fogalom, amelyet a
http://purl.org/dc/elements/1.1/creator URI azonosít. Ha mármost
egy másik
fejlesztő, aki ismeri a Dublin Core szókészletet, vagy aki rájön (pl. a weben
történő kereséssel), hogy mi a dc:creator pontos jelentése, az
megérti azt is, hogy mit jelent a fenti tripletben kijelentett viszony. És
támaszkodva erre a megértésre, ez a fejlesztő tud olyan programot írni, amely
e fogalom jelentésének megfelelően képes működni, amikor feldolgozza a
dc:creator állítmányt tartalmazó
tripletet.
Természetesen,
ez a kedvező hatás olyan arányban nő, amilyen arányban terjed az URI
hivatkozások használata a dolgok azonosítására a literálok helyett; pl. az
olyan URI hivatkozások használata, mint az exstaff:85740 és a
dc:creator az olyan karakterlánc-literálok helyett, mint
"John Smith" és "creator". Ám még egy ilyen kedvező
trend sem képes önmagában létrehozni a kívánt hatást, mert még így is
előfordulhat, hogy két különböző URI-vel hivatkozunk ugyanarra a fogalomra.
Ezért az a jó megoldás, hogy amikor csak lehet, próbáljuk meg létező
szókészletekből importálni a fogalmainkat, pl. olyanokból, mint a Dublin
Core, ahelyett, hogy újakat találnánk ki, amelyekkel esetleg átfednénk a már
létező, stabil és elterjedt szókészleteket. Ugyanis folyamatosan fejlesztenek
szókészleteket a weben specifikus alkalmazások céljaira, ahogyan azt a 6. fejezetben látni fogjuk. Azonban, ha keletkeznek
is olykor szinonimák, mégis az a tény, hogy ezek a különböző URI hivatkozások
a közösen használt "webtérben" kerülnek felhasználásra, kedvező lehetőséget
teremt mind az eltérő hivatkozások közötti lényegi azonosság felismerésére,
mind pedig a közös hivatkozások használatának elterjedésére.
Indokolt továbbá különbséget tenni a között a jelentés között, amelyet
maga az RDF asszociál azokhoz a kifejezésekhez, amelyeket az RDF
kijelentésekben használunk (mint pl. a dc:creator az előző
példában), valamint azok között az egyéb, kívülről definiált
jelentések között, amelyeket az emberek (vagy emberek által írt
programok) asszociálhatnak ezekhez a kifejezésekhez. Mint nyelv, az
RDF csupán három dolgot definiál közvetlenül: egyrészt az
alany-állítmány-tárgy tripletek gráf-szintaxisát, másrészt az
rdf: szókészletben szereplő URI hivatkozásokhoz kapcsolódó
bizonyos jelentéseket, és harmadrészt, néhány olyan fogalmat, amelyekkel
később foglalkozunk; ezeknek a dolgoknak a normatív definíciója az [RDF-SZEMANTIKA] és az [RDF-FOGALMAK] dokumentumban található. Az RDF
azonban nem definiálja az RDF állításokban használható olyan
kifejezések jelentését, amelyeket más szókészletek tartalmaznak (mint pl.
dc:creator). Várható, hogy további specifikus szókészleteket
fognak majd összeállítani, s ezek kifejezéseihez specifikus jelentéseket
fognak társítani, de ez már az RDF-en kívül történik. Azok az RDF
kijelentések, amelyek az ilyen szókészletekből használnak fel URI
hivatkozásokat, átvihetik az ezekhez társuló specifikus jelentéseket azokhoz
az emberekhez, akik ismerik az adott szókészleteket, és átvihetik az olyan
alkalmazásokhoz is, amelyek képesek ezeket a szókészleteket feldolgozni; nem
mondanak azonban semmit az olyan RDF alkalmazások számára, amelyeket nem
kifejezetten az ilyen szókészletek feldolgozására terveztek.
Például: az emberek meghatározott jelentést asszociálhatnak az alábbi
triplethez:
ex:index.html dc:creator exstaff:85740 .
azon az alapon, hogy értik, mit jelent a "creator" szó a
dc:creator URI hivatkozásban, vagy azon az alapon, hogy
megértették a Dublin Core szókészlet dc:creator attribútumának a
definícióját. Azonban, egy tetszőleges RDF alkalmazás szemszögéből nézve, a
fenti triplet akár valami efféle is lehetne:
fy:joefy.iunm ed:dsfbups fytubgg:85740 .
legalábbis, ami a triplet beépített jelentését illeti. Egy természetes
nyelvű szöveg, amelyik az interneten leírná a dc:creator
jelentését, szintén nem reprezentálna semmi olyan további jelentést, amelyet
egy tetszőleges alkalmazás közvetlenül használni tudna.
Természetesen, egy adott szókészletből származó URI hivatkozásokat akkor
is használhatnánk egy RDF kijelentésben, ha egy konkrét alkalmazás nem lenne
képes semmilyen jelentést társítani hozzájuk. Például egy RDF alapszoftver
felismeri ugyan, hogy ez egy RDF kijelentés, és hogy az
ed:dsfbups az állítmánya stb., de bizonyára nem társítana olyan
speciális jelentést a triplet ed:dsfbups URIref-jéhez, mint
amilyent a szókészlet fejlesztője társított hozzá. A fejlesztők viszont, azon
az alapon, hogy megértették egy adott szókészlet jelentését, írhatnak olyan
RDF alkalmazásokat, amelyek a szókészlet URI-jeihez kapcsolt jelentéseknek
megfelelő viselkedést mutatnak. Ez akkor is igaz, ha ezek a jelentések nem
hozzáférhetőek a többi alkalmazás számára, amelyeket nem ilyen alapon
készítettek.
E felismerések eredményként, az RDF lehetőséget biztosít arra, hogy olyan
kijelentéseket tegyünk, amelyeket az alkalmazások könnyebben fel tudnak
dolgozni. Egy alkalmazás ugyan valójában nem sokkal többet "ért" az RDF
kijelentésekből, mint amennyit mondjuk egy adatbázis-kezelő szoftver "ért" az
olyan fogalmakból, mint "alkalmazott", vagy "havi bére", amikor feldolgoz egy
ilyen lekérdezést, mint pl. SELECT Alkalmazott Neve WHERE Havi bére > 120
000. Ennek ellenére, ha az RDF alkalmazást megfelelően írtuk meg, az mégis
képes lesz olyan módon kezelni az RDF állításokat, hogy úgy tűnik, mintha
valóban értené őket (mint ahogy egy adatbázis-kezelő és az alkalmazásai is
értelmes munkát képesek végezni, amikor feldolgozzák az alkalmazotti és
bérszámfejtési adatokat, noha nem tudják, mit jelent az "alkalmazott" vagy a
"havi bére" kifejezés).
Tegyük fel, hogy egy alkalmazásfejlesztő szeretne egy olyan alkalmazást
írni, amelyik kikeresné a weben az összes minősített könyv összes olvasói
minősítését, és készítene ezek alapján, könyvenként, egy átlagolt minősítést,
amit azután egy dinamikus weblapon visszatenne a webre. Egy másik webhely
programja pedig később venné ezt a listát, és készítene ennek alapján egy
másik dinamikus weblapot, mondjuk, "A legmagasabbra értékelt könyvek 10-es
top-listája" címmel. Gondoljuk meg, hogy az ilyen alkalmazások szempontjából
milyen óriási segítséget jelentene egy általánosan hozzáférhető, közös
szókészlet a könyvek minősítési fogalmairól, és egy másik közös szókészlet
azokból az URI hivatkozásokból, amelyek a minősített könyveket azonosítják.
Az RDF alkalmazása lehetővé teszi az egyének számára az ilyen szókészletek
közös fejlesztését, és így fokozatosan kialakulhat egy kölcsönös érdeklődésre
számot tartó, és egyre növekvő képességű (mert egyre több közreműködőt
aktivizáló) információbázis a könyvekről a weben. Ugyanez az elv érvényes a
többi, hatalmas mennyiségű értékes információra is, amelyet az emberek nap
mint nap produkálnak témák ezreiről az interneten.
Az RDF állítások nagyon hasonlóak több más, ismert adatformátumhoz,
amelyet információk rögzítésére használnak, mint például:
- az egyszerű bejegyzések a katalógus-rekordokban, amelyek erőforrásokat
írnak le egy adatfeldolgozó rendszer számára,
- az egyszerű sorok egy relációs adatbázis táblázatában,
- az egyszerű kijelentések a formális logikában,
Az ilyen formátumú információk (egy minimális formátum-konverzióval) RDF
kijelentésekként is interpretálhatók, lehetővé téve ily módon, hogy az RDF
segítségével sokféle forrásból adatokat integrálhassunk.
2.3
Strukturált tulajdonságértékek és üres csomópontok
Nagyon könnyű lenne az élet, ha a dolgokról rögzítendő információk már
eleve a fentebb illusztrált, egyszerű RDF kijelentések formájában állnának
rendelkezésünkre. Sajnos azonban, a való világ legtöbb adata ennél jóval
összetettebb szerkezetű, legalábbis ami a külső megjelenését illeti. Például
a kedvenc példánkban azt az információt, mely a John Smith által kreált
weblap keletkezési dátumát rögzíti az exterms:creation-date
tulajdonság értékeként, egyetlen típus nélküli literál formájában ábrázoltuk.
De mi lenne, ha ezt a tulajdonságot három, külön is kezelhető információként,
mondjuk év, hónap és nap formában kellene rögzíteni? Vagy, ha John Smith
személyi adatait, mondjuk a lakcímét kellene regisztrálni? Természetesen,
kiírhatnánk a teljes címet akár egyetlen típus nélküli literál formájában is,
mint ahogy ebben a tripletben tesszük:
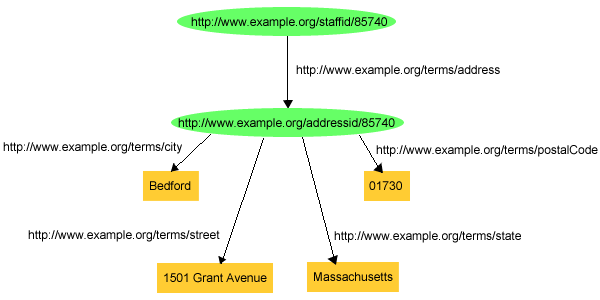
exstaff:85740 exterms:address "1501 Grant Avenue, Bedford, Massachusetts 01730" .
De hogyan járnánk el akkor, ha a címet egy olyan struktúra
formájában kellene rögzíteni, mely külön is kezelhető adatként ábrázolja az
utca, a város, az állam és az irányítószám (street, city, state, és postal
code) értékeit? Hogyan lehetne ezt leírni RDF-ben?
Az efféle strukturált információt úgy ábrázoljuk az RDF-ben, hogy az olyan
összetett adatot, mint pl. John Smith lakcíme, egy önálló erőforrásnak
tekintjük, és azután elemi kijelentéseket fogalmazunk meg erről az új
erőforrásról. Mivel ehhez az RDF gráfban előbb komponenseire kell bontanunk
John Smith címét, ezért a címfogalom számára készítünk egy új csomópontot,
amelyet egy új URI hivatkozással azonosítunk. (Ez lehet pl.
http://www.example.org/addressid/85740, amelyet
exaddressid:85740 formában rövidítünk). Ezután már további élek
és csomópontok segítségével ábrázolhatjuk az elemi információk rögzítéséhez
szükséges RDF kijelentéseket, amelyek mindegyikében az új csomópont lesz az
alany, amíg végül ki nem alakul az 5. ábrán látható
gráf:
Ugyanez triplet formában írva:
exstaff:85740 exterms:address exaddressid:85740 .
exaddressid:85740 exterms:street "1501 Grant Avenue" .
exaddressid:85740 exterms:city "Bedford" .
exaddressid:85740 exterms:state "Massachusetts" .
exaddressid:85740 exterms:postalCode "01730" .
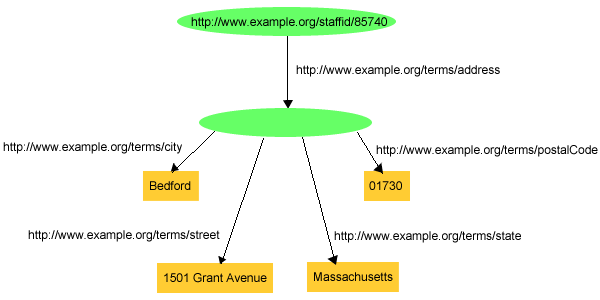
Az RDF-ben a strukturált információk ábrázolása számos ilyen "közbülső"
URIref előállítását igényelheti, mint az exaddressid:85740, ha
sok olyan összetett fogalmat kell ábrázolnunk, mint John Smith lakcíme. Mivel
azonban az ilyen segédfogalmakra általában nem kell az adott gráfon kívülről
hivatkozni, ezért általában nincs is szükség globális azonosítókra az
elérésükhöz. Amikor tehát gráffal ábrázoltuk az 5.
ábrán szereplő RDF kijelentéseket, a John Smith címéhez rendelt URIref
előállítására és feltüntetésére nem is lett volna szükség, hiszen a gráfot
úgy is megrajzolhattuk volna, ahogy az a 6. ábrán
látható:
A 6. ábrán szereplő gráf, mely egy teljesen
szabályos RDF gráf, egy URIref nélküli csomóponttal ábrázolja a John Smith
címének megfelelő fogalmat. Ez az üres csomópont
betölti a célját a rajzon anélkül, hogy szükség volna egy URIref-re, hiszen
ez a csomópont önmagában is jól mutatja a kapcsolatokat a gráf különböző
részei között. (Nem véletlen, hogy az üres csomópontokat az [RDF-MS]-ben anonimous resources, azaz
névtelen erőforrások néven emlegették). Amikor azonban tripletek
formájában kívánjuk leírni a gráfot, mégiscsak szükségünk lesz valamilyen
explicit azonosítóra, hogy hivatkozni tudjunk erre az üres csomópontra. Hogy
belássuk ezt, próbáljuk meg RDF mondatokkal leírni a 6.
ábrán látható gráfot! Valami effélét kapnánk:
exstaff:85740 exterms:address ??? .
??? exterms:street "1501 Grant Avenue" .
??? exterms:city "Bedford" .
??? exterms:state "Massachusetts" .
??? exterms:postalCode "01730" .
ahol a "???" az üres csomópontot próbálja jelezni. Mivel azonban egy
összetettebb gráf több üres csomópontot is kénytelen előállítani, ezért
szükség van egy olyan módszerre, amellyel megkülönböztethetjük ezeket, amikor
RDF kijelentésekben hivatkozunk rájuk. Ezért a tripletekben ún. ürescsomópont-azonosítókat
használunk, amelyeket _:name formában írunk. A fenti példában, mondjuk, a
_:johnaddress azonosítóval hivatkozhatnánk az üres csomópontra,
mely esetben az alábbi tripleteket kapnánk:
exstaff:85740 exterms:address _:johnaddress .
_:johnaddress exterms:street "1501 Grant Avenue" .
_:johnaddress exterms:city "Bedford" .
_:johnaddress exterms:state "Massachusetts" .
_:johnaddress exterms:postalCode "01730" .
Egy gráf tripletes ábrázolása során minden üres csomópont saját azonosítót
kap. De, eltérően az URI azonosítóktól és a literáloktól, az
ürescsomópont-azonosítókat nem tekintjük a gráf tényleges részének (ez jól
látható a 6. ábrán megrajzolt gráfon, ahol nincs is
feltüntetve az azonosító). Az ilyen azonosítók csupán arra szolgálnak, hogy
amikor a gráfot tripletek formájában írjuk le, meg tudjuk különböztetni, hogy
melyik üres csomópontra hivatkozik egy adott kijelentés. Az ilyen
azonosítóknak csak azokban a tripletekben van megkülönböztető érvényük,
amelyek egyetlen gráfhoz tartoznak. Két különböző gráfban az üres
csomópontok azonosítására nyugodtan használhatjuk ugyanazokat az
azonosítókat, hiszen nem kell attól tartanunk, hogy ugyanarra a csomópontra
hivatkoznak, mivel ezek lokális hatókörű azonosítók. Persze, ha várható, hogy
egy csomópontra az adott gráfon kívülről is történik majd hivatkozás, akkor
egy URI-t kell hozzárendelnünk. És végül, mivel az ilyen azonosítók mindig
(üres) csomópontokat, és nem éleket azonosítanak, ezért csak a tripletek
alanya vagy tárgya helyén alkalmazhatjuk őket; sohasem használhatók tehát az
állítmány azonosítására.
Ennek a szekciónak az elején láttuk, hogy az olyan strukturált adatokat,
mint pl. John Smith címe, úgy ábrázolhatjuk, hogy egy külön erőforrásnak
tekintjük, és erre (mint alanyra) vonatkozólag különböző állításokat teszünk.
Ez a példa az RDF egyik fontos aspektusát mutatja meg: azt, hogy az RDF
kijelentései, közvetlenül, csak bináris relációkat képesek
ábrázolni. Például azt a viszonyt, amely John Smith és a teljes címét
ábrázoló egyetlen literál között fennáll. Amikor azonban John Smith, és a
címét alkotó elemi komponensek közötti viszonyt kell ábrázolnunk, akkor már
n-áris (n-ágú) relációról beszélünk, ahol történetesen
n = 5, hiszen ezt az alanyt 4 tárgyhoz (utca, város, állam,
irányítószám) kell kapcsolnunk. Ahhoz tehát, hogy az ilyen struktúrákat
közvetlenül RDF-ben ábrázolhassuk, ezt az n-ágú viszonyt fel kell
bontani több bináris viszonyra. Az üres csomópontok használata az egyik
lehetőség erre. Minden n-áris relációban az egyik résztvevő elemet
kinevezzük a reláció alanyának (esetünkben ez John Smith), és egy üres
csomópontot kreálunk a reláció többi elemének a csatlakoztatása számára
(esetünkben ez John Smith címe lesz). A reláció többi résztvevőjét
(esetünkben az utca, város, állam, irányítószám komponenseket) az új
erőforrás, vagyis az üres csomópont (mint alany) különböző tulajdonságaiként
ábrázoljuk.
Az üres csomópontok alkalmazása azt is lehetővé teszi, hogy pontosabban
fogalmazhassuk meg állításainkat az olyan erőforrásokról, amelyeknek esetleg
nincs URI-jük, de amelyek leírhatók más, olyan erőforrásokhoz való viszonyuk
alapján, amelyeknek van URI-jük. Például, amikor kijelentéseket
teszünk egy személyről (ezúttal mondjuk Jane Smith-ről), akkor
kézenfekvőnek tűnhet egy olyan URI használata az azonosításához, mint pl. az
e-mail címe (mondjuk: mailto:jane@example.org ). Ez a megoldás
azonban problémákat okozhat. Ilyenkor ugyanis információt kell regisztrálnunk
mind az elektronikus postaládájáról (pl. a szerver címéről, amelyen ez
tárolva van), mind pedig magáról, Jane Smith-ről (pl. a jelenlegi címéről,
ahol fizikailag elérhető). Ha tehát egy olyan URI-t használunk Jane
azonosítására, mely az e-mail címén alapszik, akkor nehéz lesz megállapítani,
hogy maga Jane-e az alany, vagy csak az e-postaládája, amelyről a
kijelentéseinket megfogalmazzuk. Ugyanez a probléma áll elő, amikor egy cég
weblapjának URL-jét, mondjuk, a http://www.example.com/ URL-t
magának a cégnek az URI-jeként használjuk. Itt is ugyanaz a helyzet áll elő,
mint Jane esetében: információkat kellene rögzítenünk a weblapról, magáról,
(hogy pl. ki készítette, és mikor), és külön a cégről is. Ha mármost a
http://www.example.com/ URI-t használnánk mindkettőnek az
azonosítására, nehéz lenne kívülről megállapítani, hogy ezek közül melyik a
tényleges alany.
Az alapvető probléma az, hogy ha Jane e-mail címét használnánk Jane
helyett, ez nem lenne pontos: Jane, és az e-mail címe nem ugyanaz a dolog, s
ezért ezeket különbözőképpen kellene azonosítani. Ha Jane-nek nincs saját
URI-je, egy üres csomópont sokkal alkalmasabb ennek a helyzetnek a
modellezésére. Jane-t tehát egy üres csomóponttal ábrázoljuk, és ehhez az
alanyhoz, állítmányként, megadjuk az exterms:mailbox azonosítót,
amelynek tárgyára (a mailbox tulajdonság értékére) a
mailto:jane@example.org azonosítóval hivatkozunk. Az üres
csomópontot egyébként leírhatnánk az rdf:type tulajdonsággal is,
amelynek az értéke, mondjuk, az exterms:Person (Személy)
minősített név lehetne. (A típusokat a következő szekcióban tárgyaljuk
bővebben). Így tehát, van egy olyan üres csomópontunk, amelyről most már
minden jellemző információt megadhatunk. A nevét pl. az
exterms:name tulajdonság értékeként, mely "Jane Smith", az
alábbi tripletek segítségével adhatjuk meg:
_:jane exterms:mailbox <mailto:jane@example.org> .
_:jane rdf:type exterms:Person .
_:jane exterms:name "Jane Smith" .
_:jane exterms:empID "23748" .
_:jane exterms:age "26" .
(Figyeljük meg, hogy az első tripletben a
mailto:jane@example.org hegyes zárójelek között van megadva. Ez
azért van így, mert a mailto:jane@example.org egy teljes URI
séma, és nem egy rövidítés, azaz nem minősített név, tehát hegyes zárójelek
közé kell tennünk a tripletek leírásánál.)
Ezek a tripletek lényegében ezt mondják: "adott egy Személy típusú
erőforrás, amelynek az e-postaládája: mailto:jane@example.org, a
neve: Jane Smith stb." Az üres csomópontot tehát így olvassuk: "adott egy
erőforrás". Azok a kijelentések tehát, amelyek az üres csomóponttal megadott
erőforrásra mint alanyra hivatkoznak, megadhatják az összes fontos
információt erről az erőforrásról.
A gyakorlatban az üres csomópontok használata (ezekben az esetekben URI
hivatkozások helyett) nem érinti lényegesen az ilyen típusú információk
kezelését. Ha pl. tudjuk, hogy egy e-mail cím egyedileg azonosít egy
személyt, mondjuk az example.org cégnél (különösen, ha a cég garantálja, hogy
a címeket nem használják fel kétszer), ez mégiscsak alkalmas lehet arra, hogy
többféle forrásból információkat kapcsoljunk ehhez a személyhez akkor is, ha
az e-mail cím URI-je nem a személy URI-je. Ilyenkor, pl., ha
valamilyen RDF-ben regisztrált adatot találunk a weben, amelyik leír egy
könyvet, ahol a szerző azonosítójaként csupán az e-mail címe (itt:
mailto:jane@example.org) van megadva, akkor célszerű, ha
kombináljuk ezt az új információt a fenti tripletekben megadottakkal, hiszen
így nemcsak azt tudhatjuk meg, hogy a szerző neve Jane Smith, hanem több más
személyi adatához is hozzájuthatunk. A mondanivaló itt az, hogy ha valami
ilyesmit közlünk, hogy "a könyv szerzője:
mailto:jane@example.org", akkor ez lényegében annak a
kijelentésnek a rövidített formája, hogy "a könyv szerzője olyan
valaki, akinek az e-mail címe mailto:jane@example.org". Az
üres csomópont használata ennek a "valakinek" az ábrázolására csupán egy
precízebb módja a való világ egy adott szituációjának a modellezésére.
(Egyébként, egyes RDF alapú sémanyelvek lehetővé teszik annak a
specifikálását, hogy bizonyos tulajdonságok egyedi azonosítói azoknak az
erőforrásoknak, amelyeket leírnak. Ezt az 5.5
szekció tárgyalja részletesebben.)
Az üres csomópontok ilyen alkalmazása elkerülhetővé teszi a literálok
alkalmazását olyan esetekben, amikor ez nem a legjobb megoldás lenne. Ha pl.
Jane könyvének leírásakor a kiadója a szerző URIref-jének hiányában esetleg
ilyen adatokat adna meg (a kiadó saját, ex2terms: nevű belső
szókészlete segítségével) mint:
ex2terms:book78354 rdf:type ex2terms:Book .
ex2terms:book78354 ex2terms:author "Jane Smith" .
akkor ez nem lenne a legjobb megoldás, hiszen a könyv szerzője
(ex2terms:author) valójában nem a "Jane Smith" karakterlánc, hanem egy olyan
személy, akinek csak a neve Jane Smith. Ez az információ sokkal
pontosabban megadható lenne, ha a kiadó egy üres csomóponttal azonosítaná a
szerzőt, pl. így:
ex2terms:book78354 rdf:type ex2terms:Book .
ex2terms:book78354 ex2terms:author _:author78354 .
_:author78354 rdf:type ex2terms:Person .
_:author78354 ex2terms:name "Jane Smith" .
Ez lényegében azt mondja (a kiadó saját szókészletével): "a book78354 egy
Könyv (Book) típusú erőforrás, amelynek a szerzője (author) egy Személy
(Person) típusú erőforrás, amelynek a név (name) tulajdonsága: Jane Smith".
Természetesen, a szerzők adatainak megadásakor a kiadó saját URI
hivatkozásokat is hozzárendelhetne a szerzőkhöz ahelyett, hogy üres
csomópontokat alkalmaz az azonosításukra, mert ezzel lehetővé tenné, hogy a
szerzőire kívülről is hivatkozhassanak (pl. a recenzensek, olvasók stb.).
És végül: az egyik fenti példa, amelyben úgy adtuk meg Jane életkorát,
hogy _:jane exterms:age "26", jól illusztrálja azt a tényt, hogy
bár egy tulajdonság értéke egyszerűnek tűnik, a valóságban ez sokkal
bonyolultabb valami. Ebben az esetben pl. Jane életkora ténylegesen 26
év, de a tulajdonság mértékegysége (az év) nincs explicit módon
megadva. Az efféle információt gyakran kihagyják az olyan környezetben, ahol
biztonságos módon feltételezhető, hogy aki felkeresi ezt az adatot, az tudja,
hogy milyen mértékegységben van megadva. Viszont a Web szélesebb
kontextusában általában nem biztonságos ilyen feltételezéssel élni.
Például az USA-ban, vagy az Egyesült Királyságban egy webhely megadhat egy
súlyértéket Fontban, egy más országbeli szörföző pedig azt hiheti, hogy ez a
súly Kilogrammban van megadva. Általában komolyan meg kell fontolnunk, hogy
nem helyesebb-e explicit módon megadni a mértékegységeket is az ilyen adatok
ábrázolásánál. Ezzel a kérdéssel részletesebben a 4.4.
szekció foglalkozik, mely ismertet egy RDF opciót az ilyen információ
megadására, strukturált adatérték formájában, de bemutat más technikákat is a
probléma kezelésére.
2.4 Tipizált literálok
Az előző szekció bemutatta, hogyan kezelhetjük azokat a szituációkat,
amikor a típus nélküli literálokkal ábrázolt tulajdonságértékeket fel kell
bontanunk strukturált értékekre, hogy ezeket egyenként ábrázolhassuk és
visszakereshessük. Ezt a módszert alkalmazva, pl. ahelyett, hogy egy weblap
keletkezési dátumát egy exterms:creation-date tulajdonság
értékeként, egyetlen típus nélküli literállal ábrázolnánk, inkább egy olyan
struktúrával ábrázoljuk, mely három önálló, típus nélküli literálból áll,
amelyek értékei rendre: az év, a hónap és a nap. Eddig azonban minden
konstans érték, amelyet RDF kijelentések tárgyaként használtunk, kizárólag
ilyen típus nélküli (angolul: plain) literál volt, akkor is, amikor
lényegében számértékeket kívántunk megadni (mint pl egy évszám, vagy
egy életkor), vagy pedig egy másfajta, még specializáltabb értéket.
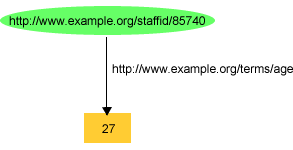
A 4. ábra például egy olyan RDF gráfot ábrázolt,
mely John Smith-ről rögzített információkat. Az a gráf pl. John Smith
exterms:age (életkora) tulajdonságának értékét a "27" típus
nélküli literállal ábrázolta, ahogyan az a 7. ábrán is
megjelenik:
Itt a hipotetikus example.org cég nyilván számként kívánta
értelmezni a "27" kifejezést, és nem egy olyan karakterláncként, mely a "2"
és a "7" karakterekből áll (hiszen ez egy "életkor" számértéke akar lenni).
Azonban a 7. ábra gráfjában nincs olyan információ, mely explicit módon
jelezné, hogy a "27" kifejezést számként kell értelmezni. Ugyanígy,
ez a cég nyilván azt szeretné, ha ezt a "27"-et decimális számként
értelmeznék, amelynek értéke 27, és nem pl. oktális számként, amelynek értéke
23. De, szögezzük le ismét, nincs olyan információ a 7. ábra gráfjában, amely
explicit módon jelezné ezt. Persze, egyes alkalmazásokat lehetne úgy
tervezni, hogy az exterms:age tulajdonság értékét automatikusan
decimális számnak értelmezzék. Ám ez azt jelentené, hogy az adott RDF kód
helyes értelmezése olyan információtól függene, ami nincs megadva az RDF
gráfban, vagyis olyan információtól, ami nem feltétlenül áll rendelkezésre a
többi alkalmazás számára, amelyik szintén szeretné feldolgozni ezt az RDF
kódot.
A programozási nyelvek és az adatbázis-rendszerek területén elterjedt
gyakorlat az, hogy adattípust kapcsolnak a literálokhoz (pl.
integer, decimal stb.), amelyből egyértelműen kiderül, hogy
miként kell értelmezni az adott literált. Az olyan alkalmazás, amelyik ismeri
ezt az adattípust, az meg tudja állapítani, hogy a "10" literál, a
tíz vagy a kettő számértéket, vagy egy olyan karakterláncot
ábrázol-e, amelyik az "1" és a "0" karakterekből áll, attól függően, hogy az
adattípus integer, binary, vagy pedig
string. (További specializált adattípusokat is használhatnánk,
hogy egyértelműen azonosíthassuk az olyan mértékegységeket, mint pl. a
"Font" vagy a "Kilogramm", ahogy az már, a 2.3 szekció végén is felmerült, habár ebben
a könyvben nem dolgoztuk ki ezeket a típusokat). Az RDF-ben tipizált (vagyis
típussal rendelkező) literálokat használunk az ilyen információk
megadására.
Az RDF tipizált literáljait egy karakterláncból, és egy URI hivatkozásból
alakítjuk ki, ahol az előbbi a literál lexikai megjelenését reprezentálja, az
utóbbi pedig a típusát azonosítja. Az RDF gráfban ezt egy
literál-csomóponttal ábrázoljuk, amelyben megjelenik ez a páros. A tipizált
literál értéke az az érték, amit a megadott adattípus társít a megadott
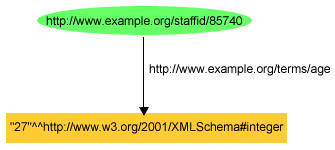
karakterlánchoz. Például, egy tipizált literál használatával John Smith
életkorát (ami 27 év) triplet formájában így adhatnánk meg:
<http://www.example.org/staffid/85740> <http://www.example.org/terms/age> "27"^^<http://www.w3.org/2001/XMLSchema#integer> .
vagy, ha alkalmazzuk a minősített névvel történő rövidítést, akkor így:
exstaff:85740 exterms:age "27"^^xsd:integer .
ha pedig gráffal kívánjuk megadni, akkor 8. ábrán
látható módon rajzoljuk le:
Hasonlóképpen, a 3. ábrán szereplő gráfban, amelyik
információkat közöl egy weblapról, az exterms:creation-date (a
készítés dátuma) tulajdonság értékét ezzel a típus nélküli literállal adtuk
meg: "August 16, 1999". Egy tipizált literál használatával azonban a weblap
készítésének dátumát egy "dátum" (date) típusú literállal explicit formában
is megadhatnánk, ahogy az alábbi triplet mutatja:
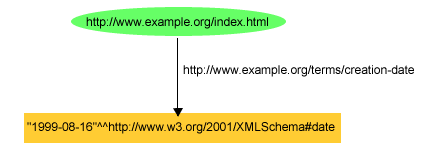
ex:index.html exterms:creation-date "1999-08-16"^^xsd:date .
Gráf segítségével pedig úgy adhatnánk meg, ahogyan a 9.
ábra mutatja:
Szemben a tipikus programozási nyelvekkel és adatbázis-rendszerekkel, az
RDF-nek nincsenek saját, beépített adattípusai, mint pl. egész számok,
lebegőpontos számok, karakterláncok vagy dátumok. Ehelyett az RDF tipizált
literálja inkább egy egyszerű módot biztosít annak explicit megjelölésére,
hogy milyen adattípust kell használni az adott literál értelmezéséhez. Azokat
az adattípusokat, amelyeket a tipizált literálokhoz használhatunk, az RDF-en
kívül definiálták, és ún. adattípus URI-kkel
azonosították. (Ez alól van egy kivétel: az RDF definiál egyetlen beépített
adattípust, amelyet az rdf:XMLLiteral névvel azonosít, és
amellyel XML tartalmat lehet ábrázolni literális érték formájában. Ezt az
adattípust az [RDF-FOGALMAK] dokumentum
definiálja, használatát pedig könyvünk 4.5
szekciója ismerteti.) A 8.ábrán és a 9.ábrán bemutatott példáknál már használtuk az
integer (egész szám) és a date (dátum)
adattípusokat az XML Séma adattípusai közül, amelyeket az XML Schema Part 2: Datatypes
dokumentum ismertet (a referenciája: [XML-SCHEMA2]). Az adattípusok ilyen
megvalósításának egyik előnye az a flexibilitás, hogy az RDF így közvetlenül
ábrázolhat különböző forrásokból származó információkat anélkül, hogy
típuskonverziót kellene végeznie e források adattípusai, és saját, belső
adattípusai között. (Bizonyos konverzió azért mégis szükséges, amikor olyan
rendszerek között kell adatokat átvinni, amelyek eltérő adattípus-halmazokkal
dolgoznak, de az RDF ilyenkor sem végez extra konverziót a szabványos RDF
típusokon, sem oda, sem vissza.)
Az RDF adattípus-koncepciója az XML Séma
adattípusok [XML-SCHEMA2] konceptuális
keretére épül, ahogyan azt Az RDF
alapfogalmai és absztrakt szintaxisa leírja ([RDF-FOGALMAK]). Ez a konceptuális keret úgy
definiálja az adattípust, hogy az a következő elemeket tartalmazza:
- Egy értékhalmazt, amelyet értéktér-nek nevez, és amit az
adattípus literálja ábrázolni kíván. Például Az XML Séma
xsd:date adattípusa esetén ez az értékhalmaz a dátumok
halmaza.
- Karakterláncok egy halmazát, amelyet lexikális tér-nek nevez,
és amit az adattípus az érték leírására használ. Ez a halmaz azt
határozza meg, hogy mely karakterláncok használhatók legálisan az adott
típusú literál lexikális ábrázolására. (Például az
xsd:date
adattípust úgy definiálja, hogy a dátum ábrázolásának legális
literál-formája 1999-08-16, és nem August 16,
1999. Lásd: [RDF-FOGALMAK]). Egy
adattípus lexikális tere csakis a [UNICODE]
kódolású karakterláncok halmazán belül lehet, azért hogy több nyelven is
megvalósulhasson az információ közvetlen ábrázolása.
- Egy
lexikális-->érték
típusú leképezést, mely az adat lexikális terét, annak értékterére képezi
le. Vagyis, azt határozza meg, hogy a lexikális tér egy adott
karakterlánca milyen konkrét adatértéket ábrázol egy meghatározott
adattípus esetén. Például az xsd:date adattípus
lexikális-->érték leképezése azt határozza meg,
hogy ennél az adattípusnál az 1999-08-16 karakterlánc az
1999. augusztus 16. dátumot jelenti. A lexikálisról
értékre történő leképezés egy fontos tényező, mert ugyanez a karakterlánc
más-más értéket jelenthet a különböző adattípusok számára.
Nem minden adattípus alkalmas az RDF-ben történő használatra. Ahhoz, hogy
egy adattípus alkalmas legyen az RDF céljaira, bele kell illeszkednie a fenti
konceptuális keretbe. Ez lényegében azt jelenti, hogy ha adott egy
karakterlánc, az adattípusnak egyértelműen definiálnia kell, hogy ez az
adattípus a lexikális terén belül van-e, és hogy annak értékterében milyen
értéket reprezentál. Például az alapvető XML Séma adattípusok, mint
xsd:string, xsd:boolean, xsd:date stb.
alkalmasak az RDF-ben történő használatra. Néhány XML Séma adattípus azonban
nem tartozik ebbe a körbe. Például az xsd:duration nem
rendelkezik egy jól definiált értéktérrel, az xsd:QName pedig
csak XML kontextusba ágyazva használható. Azt a listát, amelyik felsorolja,
hogy az XML Séma adattípusai közül melyek alkalmasak az RDF-ben történő
alkalmazásra, és melyek nem, az [RDF-SZEMANTIKA] tartalmazza.
Mivel egy adott tipizált literál jelentését annak adattípusa definiálja,
és mivel az rdf:XMLLiteral kivételével az RDF nem definiál saját
adattípusokat, ezért az RDF gráfban megjelenő tipizált literálok tényleges
interpretációját (vagyis annak az értéknek a meghatározását, amelyet ezek a
literálok ábrázolnak), egy szoftvernek kell elvégeznie, amelyet úgy írtak
meg, hogy ne csupán az RDF kódot, hanem a literálok adattípusait is korrekt
módon fel tudja dolgozni. Valójában tehát ennek a szoftvernek egy
kiterjesztett nyelvet kell feldolgoznia, mely az RDF-en kívül az
adattípusokat is tartalmazza, mintha ezek az RDF beépített szókészletéhez
tartoznának. Ez felveti azt a kérdést, hogy mely adattípusok általánosan
hozzáférhetők az RDF szoftverben. Általában az XML Séma adattípusok azok,
amelyeket ide sorol az [RDF-SZEMANTIKA].
Ezeknek amolyan "elsők az egyenlők között" státusuk van az RDF-ben. Mint már
említettük, a 8. és 9. ábra
példái már használtak néhányat ezekből az XML Séma adattípusokból, de a
könyvünk további részében bemutatandó példáink legtöbbjében is használunk
ilyen tipizált literálokat. (Az XML Séma adattípusokhoz már eleve hozzá
vannak rendelve a megfelelő URI hivatkozások, ezekre tehát bármikor
hivatkozhatunk, lásd az [XML-SCHEMA2]-nél)
Ezeket az adattípusokat egyébként ugyanúgy kezeljük, mint bármilyen más
adattípust; az elsőbbségüket csupán az indokolja, hogy várhatólag szélesebb
körben elterjednek, és így "hordozhatóak" lesznek a különböző szoftverek
között. Ennek eredményeként pedig egyre több olyan szoftvert írnak majd,
amelyek fel tudják dolgozni ezeket az adattípusokat. Persze, írhatunk olyan
RDF szoftvert is, amely más adattípusokat is fel tud dolgozni, feltéve, hogy
azok beleillenek az RDF keretbe (ennek kritériumait fentebb már ismertettük).
Előfordulhat, hogy egy RDF szoftvertől azt kérik, hogy dolgozzon fel olyan
RDF adattípusokat, amelyek kezelésére nem készítették fel. Ilyenkor lesz
néhány olyan feladat, amit a szoftver nem tud elvégezni. Például: minthogy az
rdf:XMLLiteral kivételével az RDF nem definiálja azokat az URI
hivatkozásokat, amelyek az adattípusokat azonosítják, így egy RDF szoftver,
hacsak nem úgy írták meg, hogy meghatározott URI hivatkozásokat felismerjen,
azt sem tudja megállapítani, hogy egy tipizált literálban szereplő URI
hivatkozás létező adattípusra mutat-e egyáltalán. Továbbá: még akkor is, ha
egy URI hivatkozás létező adattípust azonosít, az RDF maga nem definiálja az
adott literál és az adott adattípus összepárosításának az érvényességét. Ezt
az érvényességet csak a szoftverünk tudja megállapítani, ha úgy programoztuk,
hogy fel tudja dolgozni ezt a bizonyos adattípust.
Tekintsük például azt a tipizált literált, mely az alábbi tripletben
szerepel:
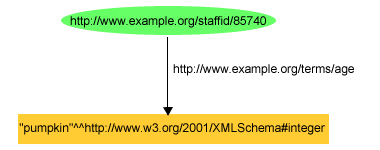
exstaff:85740 exterms:age "pumpkin"^^xsd:integer .
vagy pillantsunk az alábbi gráfra a 10. ábrán:
Láthatjuk, hogy noha mindkét esetben (formailag) érvényes RDF ábrázolással
van dolgunk, az mégis nyilvánvalóan hibás, hiszen az xsd:integer
adattípushoz párosított "pumpkin" literál nincs benne az egész szám
(integer) adattípus lexikális terében. Az olyan RDF szoftver, tehát, amelyet
nem úgy írtak meg, hogy fel tudja dolgozni az xsd:integer
adattípust, nem lenne képes felismerni ezt a hibát.
Ha azonban az RDF tipizált literálokat megfelelően
kezeljük, akkor több információ áll rendelkezésünkre a literális értékek
helyes interpretációjához, ami alkalmasabbá teszi az RDF kijelentéseket az
alkalmazások közötti információcserére.
Egészében véve, az RDF lényegében egyszerű: csomópont-él-csomópont
diagramok, amelyeket URI hivatkozásokkal azonosított dolgokról szóló
kijelentésekként értelmezünk. Ez a szekció egy bevezetést adott ezekhez a
fogalmakhoz. Mint korábban már megjegyeztük, ezeknek a fogalmaknak a normatív
(azaz a definitív) specifikációja Az
RDF alapfogalmai és absztrakt szintaxisa dokumentumban, e dokumentum
referenciája pedig az[RDF-FOGALMAK] linken
keresztül érhető el. További információkért célszerű ehhez a dokumentumhoz
fordulni. Ezeknek a fogalmaknak a formális szemantikáját, azaz a pontos
jelentését Az RDF Szemantikája című
(normatív) dokumentum írja le.
Azonban azt is világosan kell látnunk, hogy az itt tárgyalt alapvető
technikák mellett, amelyekkel RDF kijelentések formájában leírhatjuk a
dolgokat, az embereknek vagy szervezeteknek szükségük van egy olyan módszerre
is, amellyel le tudják írni azt a szókészletet (azt a specifikus
terminológiát), amelyet az ilyen kijelentések szókincseként használni
kívánnak, és ezen belül is, különösen az olyan kifejezéseket, amelyekkel:
- leírhatók a dolgok típusai (mint pl.
exterms:Person)
- leírhatók a tulajdonságok (mint pl.
exterms:age és
exterms:creation-date), valamint
- leírhatók azon dolgok típusai, amelyeket a kijelentéseinkben szereplő
tulajdonságok (állítmányok) alanyaiként és tárgyaiként kívánunk használni
(például annak specifikálása céljából, hogy egy
exterms:age
tulajdonság értékének mindig xsd:integer típusúnak kell
lennie).
Az ilyen szókészletek RDF-ben történő leírásának elemei Az RDF Szókészlet Leíró Nyelv 1.0: RDF
Séma ([RDF-SZÓKÉSZLET]) dokumentumban
találhatók, amelyek gyakorlati alkalmazását könyvünk 5.
fejezete ismerteti.
A [WEBDATA] dokumentumban további
háttér-információk találhatók az RDF alapelveiről, valamint az RDF-nek arról
a szerepéről, hogy általános nyelvet biztosít a webes információk leírásához.
Az RDF felhasznál elveket és megoldásokat a tudásábrázolás, a mesterséges
intelligencia és az adatmenedzsment területéről, beleértve a konceptuális
gráfokat, a logikai alapú tudásábrázolást, a keretrendszereket és a relációs
adatbázisokat. Az ilyen témákkal kapcsolatos háttér-információk esetleges
forrásaiként jól használhatók pl. ezek az anyagok: [SOWA], [CG], [KIF], [HAYES], [LUGER], [GRAY].
3. Egy XML szintaxis az RDF számára:
RDF/XML
Mint már a 2. fejezetben említettük, az RDF konceptuális modellje egy
gráf. Az RDF rendelkezik egy XML szintaxissal, amelyet az RDF gráfok
leírására és alkalmazások közötti cseréjére használ; ennek a neve: RDF/XML. A
tripletekkel szemben, amelyek egy rövidített írásmódot használnak, az RDF/XML
az RDF írásának normatív szintaxisa. Ezt Az RDF/XML szintaxis
specifikációja [RDF-SZINTAXIS] definiálja.
A jelen szekció erről a szintaxisról szól.
Azok az alapelvek, amelyeken az RDF nyugszik, jól illusztrálhatók néhány
olyan példával, amelyet korábban már bemutattunk. Vegyük elsőnek az alábbi,
nyílt szövegű angol mondatot, mely magyarul kb. így hangzik "az
...index.html weblapnak van egy keletkezési
dátuma, amelynek értéke 1999. augusztus 16."
http://www.example.org/index.html
has a creation-date whose value is August 16,
1999
Ha feltesszük, hogy már hozzárendeltünk egy URI hivatkozást a
creation-date (keletkezési dátuma) tulajdonsághoz, akkor az az
RDF gráf, amely ezt az egyetlen mondatot leírja, úgy jelenne meg, ahogy az a
11. ábrán látható:
Ugyanez tripletes ábrázolásban:
ex:index.html exterms:creation-date "August 16, 1999" .
(Figyeljük meg, hogy ebben a példában a dátum értékének
ábrázolására nem tipizált literált használtunk. Az ilyen literálok
RDF/XML-ben történő ábrázolására ebben a fejezetben még visszatérünk.)
A 2. példa bemutatja a 11.
ábrának megfelelő RDF/XML szintaxist:
1. <?xml version="1.0"?>
2. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
3. xmlns:exterms="http://www.example.org/terms/">
4. <rdf:Description rdf:about="http://www.example.org/index.html">
5. <exterms:creation-date>August 16, 1999</exterms:creation-date>
6. </rdf:Description>
7. </rdf:RDF>
(A sorok számozása csak a példa magyarázatának a könnyítését
szolgálja.)
Ez a leírás túlságosan bőbeszédűnek tűnhet, ezért könnyebb lesz megérteni,
hogy miről is van szó, ha egyenként megvizsgáljuk az XML szöveg sorait (a B. függelék egyébként tartalmaz egy rövid bevezetést az
XML-hez).
Az 1. sor <?xml version="1.0"?> tegje az XML
deklarációt tartalmazza, mely azt adja meg, hogy a következő tartalom
XML-ben, és hogy milyen verziójú XML-ben van ábrázolva.
A 2. sorban szereplő rdf:RDF teggel megnyitunk egy elemet,
mely azt jelzi, hogy a következő XML tartalom, mely a 7. sorban az
</rdf:RDF> záróteggel ér véget, RDF adatokat ábrázol. Az
rdf:RDF nyitóteget követően, ugyanebben a sorban láthatunk egy
XML névtér-deklarációt, amelyet az RDF elem xmlns
attribútumaként adunk meg. Ez a
deklaráció azt mondja ki, hogy minden olyan név ebben a kontextusban,
amely az rdf: prefixet viseli, annak a névtérnek a része,
amelyet az attribútum értékeként megadott
http://www.w3.org/1999/02/22-rdf-syntax-ns# névtér-URIref azonosít. Így tehát azok az URIref-ek, amelyek ezzel
a hosszú karakterlánccal kezdődnek, az RDF szókészlet kifejezéseit jelölik
meg.
A 3. sorban egy második XML névtér-deklaráció látható, ezúttal az
exterms: prefix számára. Ezt a deklarációt az
rdf:RDF elem második xmlns attribútuma adja meg, és
azt specifikálja, hogy a http://www.example.org/terms/ teljes
névtér-URIref prefixet az exterms: minősítettnév-prefixhez
asszociáljuk. Így tehát azok az URIref-ek, amelyek
ezzel a karakterlánccal kezdődnek, ahhoz a szókészlethez tartoznak, amelyet a
példabeli cég: az example.org definiált. A ">" karakter, a 3. sor
végén, a nyitó rdf:RDF teg végét jelöli. Az 1-3 sorok tehát
általános információkat tartalmaznak az RDF/XML tartalom "kezeléséről",
valamint deklarálják az RDF/XML tartalmon belül használt névtereket.
A 4-6. sorok azt az RDF/XML kódot tartalmazzák, amely leírja 11. ábrán szereplő specifikus kijelentést. Kézenfekvő
dolog tehát úgy beszélni egy RDF kijelentésről, hogy az egy leírás
(description), mely az alanyról szól. Esetünkben az alanyt a
http://www.example.org/index.html URI azonosítja. Az RDF/XML-ben
a kijelentések ábrázolásának szokásos módja a következő: A 4. sorban látható
rdf:Description nyitóteg jelzi az erőforrás leírásának a
kezdetét, amelyet szorosan követ annak az erőforrásnak (a kijelentés
alanyának) az azonosítása amelyről (about) a kijelentés szól. Ez az
rdf:about attribútum segítségével történik, amelynek értéke az
erőforrást (alanyt) azonosító URIref. Az 5. sor a tulajdonság-elemet ábrázolja, amit az
exterms:creation-date minősített név (mint nyitóteg) jelöl meg,
és amely a kijelentés állítmányát azonosítja. Az
exterms:creation-date minősített nevet úgy választottuk ki, hogy
amikor a lokális creation-date nevet az exterms:
prefixhez asszociált névtér-URIref
(http://www.example.org/terms/) végéhez illesztjük, akkor
megkapjuk az állítmány teljes azonosítóját, ami ily módon
http://www.example.org/terms/creation-date lesz. Ennek a tulajdonság-elemnek a tartalma a kijelentés tárgya, amit az
"August 19, 1999" tipizált literál ábrázol (és ami nem más, mint
az erőforrás/alany "creation-date" tulajdonságának az
értéke). A tulajdonság-elem bele van ágyazva az
rdf:Description elembe, ami azt jelzi, hogy ez a tulajdonság
arra az erőforrásra vonatkozik, amelyet az rdf:Description elem
rdf:about attribútumával adunk meg. A 6. sorban látható ennek a
specifikus rdf:Description elemnek a zárótegje.
És végül: a 7. sorban láthatjuk a 2. sorban megnyitott
rdf:RDF elem zárótegjét. Az rdf:RDF elem használata
az RDF/XML tartalom közrefogására azonban opcionális az olyan esetekben, ahol
a kontextusból kiderül, hogy RDF/XML tartalomról van szó. Ezt az [RDF-SZINTAXIS] tárgyalja bővebben. Sohasem árthat
azonban, ha megadjuk az RDF elemet; a tankönyvünkben is többnyire így járunk
el.
A 2. példa bemutatta azokat az alapvető
megoldásokat, amelyeket az RDF/XML használ egy RDF gráf kódolására: az XML
elemeket, az attribútumokat, az elem tartalmát és az attribútum értékét. Az
állítmányok URI hivatkozásait (ugyanúgy, mint néhány csomópontét) XML
minősített nevekkel jelöltük meg, amelyek egy rövid prefixet (előtét-nevet)
tartalmaznak, ami a névtér-URI-t helyettesíti, és amelyhez utónévként egy
lokális név járul, amelyek így együtt egy névtérrel minősített
elemet vagy attribútumot alkotnak, ahogyan azt a B.
függelék leírja. Ez a névpár (vagyis a névtér-URIref és a lokális név)
reprezentálja a megjelölendő gráfcsomópont vagy él (állítmány) teljes URI
hivatkozását. Az alanyt ábrázoló csomópontok URI hivatkozásait XML
attribútum-értékként adtuk meg, és néha ugyanígy adjuk meg a tárgyat
ábrázoló csomópont URI hivatkozását is. A literális csomópontok, amelyek
mindig tárgyat jelölő csomópontok, a tulajdonság-elemek szövegtartalmaként
vagy attribútum-értékeként jelennek meg. (Tankönyvünk további részében még
többet bemutatunk ezek közül a lehetőségek közül, de az összes ilyen opciót
csak az [RDF-SZINTAXIS] sorolja fel.)
Egy több kijelentést ábrázoló RDF gráf egyes kijelentéseit a 2. példa 4-6. sorában bemutatotthoz hasonló módszerrel
ábrázoljuk RDF/XML-ben. Például az alábbi két kijelentést, amelyet korábbi
példákból már ismerünk:
ex:index.html exterms:creation-date "August 16, 1999" .
ex:index.html dc:language "en" .
RDF/XML-ben a 3. példában bemutatott módon
írhatjuk le:
1. <?xml version="1.0"?>
2. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
3. xmlns:dc="http://purl.org/dc/elements/1.1/"
4. xmlns:exterms="http://www.example.org/terms/">
5. <rdf:Description rdf:about="http://www.example.org/index.html">
6. <exterms:creation-date>August 16, 1999</exterms:creation-date>
7. </rdf:Description>
8. <rdf:Description rdf:about="http://www.example.org/index.html">
9. <dc:language>en</dc:language>
10. </rdf:Description>
11. </rdf:RDF>
A 3. példa ugyanolyan, mint a 2. példa, azzal a különbséggel, hogy ebben megadtunk egy
második rdf:Description elemet is (a 8-10. sorokban), hogy ezzel
leírjuk a második kijelentést. (Egy további névtér-deklarációt is megadtunk a
3. sorban, hogy ez által azonosítsuk a második kijelentés állítmányának a
dc névterét.) Tetszőleges számú további kijelentést írhatnánk
ugyanilyen módon, egy-egy rdf:Description elem hatálya alatt.
Amint azt a 3. példa is mutatja, ha egyszer már
megadtuk az XML deklarációt, valamint a használt névterek deklarációját,
minden további RDF kijelentés hozzáadása már rutinszerűen megy, és
szerkezetük sem túl bonyolult.
Az RDF/XML szintaxis egyéb rövidítési lehetőségeket is biztosít, hogy a
gyakrabban előforduló dolgokat egyszerűbben leírhassuk. Például, amikor egy
adott erőforrást egyszerre több tulajdonsággal, illetve értékkel kell
jellemeznünk (ahogyan az a 3. példában is előfordult,
ahol az ex:index.html erőforrás több kijelentés alanya), akkor
ezeket tipikusan egyetlen rdf:Description elembe ágyazva adjuk
meg, amelyik ilyenkor az összes állítmány alanyát reprezentálja. Példaképpen
ábrázoljuk a következő három kijelentést a
http://www.example.org/index.html alanyról:
ex:index.html dc:creator exstaff:85740 .
ex:index.html exterms:creation-date "August 16, 1999" .
ex:index.html dc:language "en" .
Ennek a gráfja (mely ugyanaz, mint a 3. ábráé) a 12. ábrán látható:
Ennek a gráfnak az RDF/XML leírását pl. a 4. ábrán
látható módon adhatnánk meg:
1. <?xml version="1.0"?>
2. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
3. xmlns:dc="http://purl.org/dc/elements/1.1/"
4. xmlns:exterms="http://www.example.org/terms/">
5. <rdf:Description rdf:about="http://www.example.org/index.html">
6. <exterms:creation-date>August 16, 1999</exterms:creation-date>
7. <dc:language>en</dc:language>
8. <dc:creator rdf:resource="http://www.example.org/staffid/85740"/>
9. </rdf:Description>
10. </rdf:RDF>
Az előző két példához képest, a 4. példa egy
további tulajdonságot (dc:creator) ad meg, mely a 8. sorban
látható. Továbbá, a három tulajdonság-elem, amelynek az alanyát a
http://www.example.org/index.html URI azonosítja, egyetlen
rdf:Description elembe van beágyazva ahelyett, hogy három ilyen
elem keretében adnánk meg a három tulajdonságot.
Emellett, a 8. sorban, bevezettük a tulajdonság-elemek megadásának egy új
formáját is. Figyeljük meg, hogy a 7. sorban szereplő
dc:language elem leírása hasonló a 6. sorban látható
exterms:creation-date elem leírásához, amelyet már használtunk a
2. példában. E két elem mindegyikében a tulajdonság
értékét típus nélküli literállal ábrázoltuk, és mint ilyent, a megfelelő
tulajdonság-elem nyitó- és zárótegje közé kellett írnunk. A 8. sorban lévő
dc:creator elem azonban egy olyan tulajdonságot reprezentál,
amelynek az értéke egy külön erőforrás, tehát nem egy literál. Ha tehát ennek
az erőforrásnak az URI-jét a dc:creator elem tegpárja közé
írnánk, akkor ezzel azt mondanánk, hogy a "creator" (szerzője) tulajdonság
értéke a "http://www.example.org/staffid/85740" karakterlánc, és nem egy
olyan URIref, mely az értéket azonosítja. Hogy jelölhessük ezt az alapvető
különbséget, egy olyan valamit kell használnunk, amelyet az XML üres elem
teg-nek (empty-element tag) nevez, és amelyről tudnunk kell, hogy nincs
külön zárótegje. Ebben az üres dc:creator elemben a tulajdonság
értékét ábrázoló URI hivatkozást az elem rdf:resource
attribútumának értékeként adjuk meg. Az rdf:resource attribútum
azt jelzi, hogy az elem értéke egy külön erőforrás, amelyet az URI
hivatkozása azonosít. Minthogy ezt az URI hivatkozást itt egy attribútum
értékeként kell megadni, az RDF/XML elvárja, hogy ezt abszolút vagy relatív
formában, de mindig teljesen kiírjuk. Vagyis, ezt nem rövidíthetjük le egy
minősített névre, ahogyan azt megtehettük az elemek és az attribútumok
nevei esetében. (Az abszolút és relatív URI hivatkozások témáját az
A. függelék tárgyalja.)
Fontos, hogy megértsük: a 4. példa RDF/XML kódja
egy rövidített változat. Az 5. példában
szereplő RDF/XML kódban minden kijelentést külön írtunk, és ez pontosan
ugyanazt az RDF gráfot írja le, mint a 4. példa (azaz a 12. ábrán látható gráfot):
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:exterms="http://www.example.org/terms/">
<rdf:Description rdf:about="http://www.example.org/index.html">
<exterms:creation-date>August 16, 1999</exterms:creation-date>
</rdf:Description>
<rdf:Description rdf:about="http://www.example.org/index.html">
<dc:language>en</dc:language>
</rdf:Description>
<rdf:Description rdf:about="http://www.example.org/index.html">
<dc:creator rdf:resource="http://www.example.org/staffid/85740"/>
</rdf:Description>
</rdf:RDF>
A további szekciókban még leírunk néhány más RDF/XML rövidítési
lehetőséget is. (Az [RDF-SZINTAXIS] dokumentum
tartalmazza az összes olyan rövidítést, amely alkalmazható RDF/XML-ben.)
Az RDF/XML-ben ábrázolhatunk olyan gráfokat is, amelyekben üres
csomópontok vannak. (Mint már a 2.3
szekcióban leírtuk, ezek olyan csomópontok, amelyekhez nem tartozik
URIref). Például, a 13. ábra, amelyet az [RDF-SZINTAXIS] dokumentumból vettünk át, egy
olyan gráfot jelenít meg, mely azt mondja: "A
'http://www.w3.org/TR/rdf-syntax-grammar' URL-lel azonosított dokumentum
címe: 'RDF/XML Syntax Specification (Revised)', ennek van egy szerkesztője,
és a szerkesztőnek a neve: 'Dave Beckett', a honlapja pedig:
'http://purl.org/net/dajobe/' ".
Ez a gráf egy olyan alapelvet illusztrál, amelyet a 2.3 szekcióban már tárgyaltunk: az üres
csomópont használatát olyan valaminek az ábrázolására, aminek nincs URI-je de
leírható más információk megadásával. Esetünkben az üres csomópont egy
személyt ábrázol, a dokumentum szerkesztőjét, akit a nevével és a honlapjával
írunk le.
Az RDF/XML-ben több módszer is van az olyan gráfok ábrázolására, amelyek
üres csomópontokat tartalmaznak (az [RDF-SZINTAXIS] dokumentumban ez mind
megtalálható). Az a módszer, amit itt illusztrálunk (és ami a legközvetlenebb
módszer), abból áll, hogy egy ürescsomópont-azonosítót rendelünk minden üres
csomóponthoz. Az ilyen azonosító csak egyetlen adott RDF/XML dokumentumon
belül képes egy üres csomópontot azonosítani: abban, amelyben allokálták,
tehát szemben az URI hivatkozásokkal, az adott dokumentumon kívül ez
ismeretlen. Az üres csomópontra az RDF-ben az rdf:nodeID
attribútum segítségével hivatkozunk, amelynek az értéke egy
ürescsomópont-azonosító. Ez az azonosító az RDF/XML kód olyan helyein
használható, ahol egyébként egy erőforrás URIref-je is megjelenhetne.
Specifikusan, az olyan kijelentéseket, amelyeknek az alanya egy üres
csomópont, az RDF/XML-ben egy olyan rdf:Description elemmel is
leírhatjuk, amelyben az rdf:about helyett egy
rdf:nodeID attribútumot használunk az alany azonosítására.
Hasonlóképpen, az olyan kijelentéseket, amelyeknek a tárgya egy üres
csomópont, egy olyan tulajdonság-elemmel írhatjuk le, amelyben a tárgy
azonosítóját az rdf:resource helyett egy rdf:nodeID
attribútummal adjuk meg. A 6. példa azt mutatja be,
hogy az rdf:nodeID segítségével hogyan lehet RDF/XML-ben leírni
a 13. ábrán szereplő gráfot:
1. <?xml version="1.0"?>
2. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
3. xmlns:dc="http://purl.org/dc/elements/1.1/"
4. xmlns:exterms="http://example.org/stuff/1.0/">
5. <rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar">
6. <dc:title>RDF/XML Syntax Specification (Revised)</dc:title>
7. <exterms:editor rdf:nodeID="abc"/>
8. </rdf:Description>
9. <rdf:Description rdf:nodeID="abc">
10. <exterms:fullName>Dave Beckett</exterms:fullName>
11. <exterms:homePage rdf:resource="http://purl.org/net/dajobe/"/>
12. </rdf:Description>
13. </rdf:RDF>
A 6. példa 9. sorában, az abc
ürescsomópont-azonosítót használtuk a több kijelentés alanyát jelképező üres
csomópont azonosítására. Ugyanezt az azonosítót használtuk a 7. sorban annak
megjelölésére is, hogy ez az üres csomópont az alany (azaz a weblap)
exterms:editor (szerkesztője) tulajdonságának az értéke. Az
ürescsomópont-azonosító használatának az az előnye a többi módszerrel
szemben, amelyet az [RDF-SZINTAXIS] leír, hogy
ennek segítségével egy RDF/XML dokumentum több helyéről is hivatkozhatunk
ugyanarra az üres csomópontra.
És végül, az RDF/XML-ben a 2.4 szekcióban
megismert tipizált literálok is használhatók tulajdonságok
értékeként, azok helyett a típus nélküli literálok helyett, amelyeket az
eddigi példáinkban használtunk. Egy tipizált literált úgy ábrázolunk, hogy a
tulajdonság-elemhez, mely közrefogja a literált, egy
rdf:datatype attribútumot adunk, amelynek értéke egy, a literál
adattípusát azonosító URIref.
Ha például meg akarnánk változtatni a 2. példában
szereplő kijelentést úgy, hogy tipizált literált használjon típus nélküli
helyett, az exterms:creation-date tulajdonság értékeként, akkor
annak tripletes ábrázolása így nézne ki:
ex:index.html exterms:creation-date "1999-08-16"^^xsd:date .
Ugyanez a kijelentés RDF/XML szintaxissal leírva a 7.
példában szemlélhető:
1. <?xml version="1.0"?>
2. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
3. xmlns:exterms="http://www.example.org/terms/">
4. <rdf:Description rdf:about="http://www.example.org/index.html">
5. <exterms:creation-date rdf:datatype=
"http://www.w3.org/2001/XMLSchema#date">1999-08-16
</exterms:creation-date>
6. </rdf:Description>
7. </rdf:RDF>
A 7. példa 5. sorában egy tipizált literál van
megadva az exterms:creation-date ("keletkezési dátuma")
tulajdonság-elemben oly módon, hogy annak nyitótegjében egy
rdf:datatype attribútum jelzi a literál adattípusát. Ennek az
attribútumnak az értéke egy adattípus URIref-je, ami esetünkben a
date (dátum) XML Séma adattípusra mutat. Minthogy ez az URIref
itt most egy attribútum értéke, ezért teljes terjedelmében ki kell írnunk
ahelyett, hogy megpróbálnánk xsd:date minősített névre
lerövidíteni, ahogy megtettük ezt a tripletes változatban. A literál
"1999-08-16" karakterláncát pedig, amely megfelel a date
adattípusnak, a tulajdonság-elem tartalmaként ábrázoltuk.
A tankönyvünk további részében szereplő
példákban típus nélküli literálok helyett az ábrázolandó adat típusának
megfelelő tipizált literálokat használunk, hogy ezzel is hangsúlyozzuk az
ilyen literáloknak azt az előnyét, hogy ezek jóval több információt nyújtanak
az értékük korrekt meghatározásához. (Itt kivételt teszünk azokkal a típus
nélküli literált használó példákkal, amelyeket olyan alkalmazásokból vettünk
át, ahol jelenleg nem használnak tipizált literálokat, mivel szeretnénk
pontosan bemutatni az ilyen alkalmazásoknál használt gyakorlatot. Ezekben az
esetekben tehát kivételesen megtartjuk a típus nélküli literálokat.) Az
RDF/XML-ben mind a tipizált, mind a típus nélküli literálokban (és bizonyos
kivételekkel a tegekben is) használhatunk [UNICODE] karaktereket, hogy az információkat több
nyelven is közvetlenül ábrázolhassuk.
A 7. példa azt illusztrálja, hogy a tipizált
literálok használata megköveteli: minden elemben, amelynek értéke egy
tipizált literál, szerepeljen egy rdf:datatype attribútum egy
URIref értékkel, mely a literál adattípusát azonosítja. Mint korábban már
megjegyeztük, az RDF/XML elvárja, hogy az olyan URI hivatkozásokat, amelyeket
valamilyen XML attribútum értékeként adunk meg, teljesen kiírjuk, ahelyett,
hogy egy minősített névvel lerövidítenénk. Az XML entitások
deklarációs mechanizmusát azonban ilyenkor is használhatjuk rövidítési
célokra a könnyebb írhatóság és olvashatóság érdekében. Egy XML
entitásdeklaráció lényegében egy entitásnevet rendel egy karakterlánchoz (ami
lehet akár egy URIref is). Amikor egy entitásnevet használunk bárhol az XML
dokumentumban, az XML-t feldolgozó programok behelyettesítik ezt a megfelelő
karakterlánccal. Például az alábbi ENTITY (entitás) deklaráció, amelyet
általában az RDF/XML dokumentum elején, egy DOCTYPE (dokumentumtípus)
deklaráción belül használunk:
<!DOCTYPE rdf:RDF [<!ENTITY xsd "http://www.w3.org/2001/XMLSchema#">]>
azt definiálja, hogy az xsd entitás legyen egy olyan
karakterlánc, mely az XML Séma adattípusok névterét azonosító URI hivatkozást
ábrázolja. Ez a deklaráció lehetővé teszi, hogy a teljes névtér-URI
hivatkozást a dokumentumban mindenütt az &xsd;
entitáshivatkozással helyettesítsük. Ennek a rövidítésnek a
használatával a 7. példa RDF/XML kódját úgy is
írhatnánk, ahogy azt a 8. példa mutatja:
1. <?xml version="1.0"?>
2. <!DOCTYPE rdf:RDF [<!ENTITY xsd "http://www.w3.org/2001/XMLSchema#">]>
3. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
4. xmlns:exterms="http://www.example.org/terms/">
5. <rdf:Description rdf:about="http://www.example.org/index.html">
6. <exterms:creation-date rdf:datatype="&xsd;date">1999-08-16
</exterms:creation-date>
7. </rdf:Description>
8. </rdf:RDF>
A 2. sorban látható DOCTYPE deklaráció definiálja azt az
xsd entitást, amelyet majd a 6. sorban használunk fel egy
adattípus azonosítására.
Az XML entitások rövidítő mechanizmusként történő használata opcionális az
RDF/XML-ben, és így opcionális az XML DOCTYPE deklarációjának a
használata is. (Azon olvasók számára, akik már régebbről ismerik az XML-t: az
RDF/XML-nek csupán "jól formáltnak" (well-formed), vagyis
szintaktikailag korrekt XML-nek kell lennie. Az RDF/XML-t
nem tervezték arra, hogy egy XML érvényességellenőrző (validation processor)
segítségével valamilyen DTD-vel (dokumentumtípus-definícióval) vessék egybe.
Ezt a kérdést a B. függelék tárgyalja, mely további
információkat közöl az XML-ről.)
A könnyebb olvashatóság érdekében, a tankönyvünk további részében az
xsd XML entitást oly módon fogjuk használni, ahogy azt az imént
leírtuk. Az XML entitásokat bővebben a B. függelék
ismerteti. Ez a függelék leírja, hogy más URI hivatkozások (sőt
általánosítva: más karakterláncok) is rövidíthetők XML entitásokkal.
Tankönyvünk további példáiban azonban csak az XML Séma adattípusainak URI
hivatkozásait rövidítjük ezen a módon.
Bár az RDF/XML adatok írásának több rövidített formája is létezik, az
eddig ismertetett példáinkban mégis a rövidítő módszereknek csak az
egyszerűbb, de általánosabb változatát használtuk a gráfok leírására.
Összefoglalásul megismételjük, hogy ezek alkalmazásával hogyan írunk le egy
RDF gráfot RDF/XML-ben:
- Minden üres csomóponthoz hozzárendelünk egy
ürescsomópont-azonosítót.
- Azokat a csomópontokat, amelyeket le akarunk írni, egy nem beágyazott
rdf:Description elem alanyaként adjuk meg. Ez történhet vagy
egy rdf:about attribútum segítségével (ha a csomópontot
URIref azonosítja), vagy egy rdf:nodeID segítségével (ha a
csomópont üres).
Minden egyes gráf-triplet számára, amelynek az így azonosított
csomópont az alanya, egy megfelelő tulajdonság-elemet készítünk, amelynek
a tárgya vagy literál tartalom, vagy ha ez üres, akkor egy erőforrás. Ezt
az erőforrást vagy egy rdf:resource attribútum specifikálja
(ha a tárgy csomópontja egy URIref), vagy egy rdf:nodeID
attribútum (ha a tárgy csomópontja üres).
Összehasonlítva az [RDF-SZINTAXIS] néhány,
ennél jelentősebb rövidítést lehetővé tevő opciójával, ez az egyszerű módszer
adja a gráf-struktúra legközvetlenebb ábrázolását, és ezért különösen
ajánlható az olyan alkalmazások számára, ahol a kimenő RDF/XML kód további
RDF feldolgozások bemenő adata lesz.
Az eddigi példáink feltételezték, hogy az éppen leírt erőforrásoknak már
van URI hivatkozásuk. Így pl. a kezdetben bemutatott példáinkban a különböző
adataival jellemeztük a hipotetikus example.org szervezet
weblapját amelynek URI hivatkozása:
http://www.example.org/index.html volt. Ezt az erőforrást az
RDF/XML-ben az rdf:about attribútum segítségével azonosítottuk,
amelyben teljes formájában idéztük ezt az URI-t. Noha az RDF nem
specifikálja, és nem is ellenőrzi, hogy miként rendelnek hozzá egy URI
hivatkozást egy erőforráshoz, néha azonban jó lenne, ha olyan erőforrásokhoz
rendelnénk az URI hivatkozásokat, amelyek egy szervezett csoportot alkotnak.
Példaképpen képzeljünk el egy sportszergyártó céget, amelynek a neve
example.com, és amely szeretne kiadni egy RDF alapú katalógust
az ilyen termékeiről, mint sátrak, túrabakancsok stb., és mindezt egy RDF/XML
dokumentum formájában kívánják publikálni a
http://www.example.com/2002/04/products URI-vel azonosított
webhelyen. Ebben a dokumentumban minden termékhez megadhatnának egy külön RDF
leírást. Ezt a katalógust (amelyben most még csak egyetlen árufajta szerepel:
az "Overnighter" modellnevű sátor) úgy írhatjuk le RDF/XML-ben, ahogyan azt a
9. példa mutatja:
1. <?xml version="1.0"?>
2. <!DOCTYPE rdf:RDF [<!ENTITY xsd "http://www.w3.org/2001/XMLSchema#">]>
3. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
4. xmlns:exterms="http://www.example.com/terms/">
5. <rdf:Description rdf:ID="item10245">
6. <exterms:model rdf:datatype="&xsd;string">Overnighter</exterms:model>
7. <exterms:sleeps rdf:datatype="&xsd;integer">2</exterms:sleeps>
8. <exterms:weight rdf:datatype="&xsd;decimal">2.4</exterms:weight>
9. <exterms:packedSize rdf:datatype="&xsd;integer">784</exterms:packedSize>
10. </rdf:Description>
...további termékek leírásai...
11. </rdf:RDF>
A 9. példa hasonló a korábbi példákhoz, abban a
módban, ahogyan ábrázolja pl. a sátor (tent) tulajdonságait: a
modellt (model), a fekvőhelyek számát (sleeps), a
súlyt (weight) és a szállítási méretet (packedSize).
(Itt a keretül szolgáló xml-, DOCTYPE-, RDF- és névtér-deklarációk az 1-4
sorokban, és a 11. sorban szerepelnek. Ez olyan információ, amelyet csak
egyszer kell megadni egy katalógus megírásánál, azaz nem kell megismételni a
többi termék leírásához. Figyeljük meg azt is, hogy azokat az
adattípusokat, amelyeket a sátor különböző tulajdonságaihoz
társítottunk, explicit módon adtuk meg, míg az egyes tulajdonságértékekhez
tartozó mértékegységeket nem jeleztük, pedig ezeknek is
rendelkezésre kellene állniuk ahhoz, hogy helyesen interpretáljuk az
értékeket. (A 4.4 szekció ismerteti az olyan
mértékegységek és egyéb információk ábrázolását, amelyek a tulajdonságok
értékeihez társulhatnak.) A példából csupán sejthető, hogy az
exterms:sleeps tulajdonság értéke azon személyek száma, akik a
sátorban éjszakázhatnak, hogy az exterms:weight értéke (a sátor
súlya) kilogrammban van kifejezve, és hogy az exterms:packedSize
(az összecsomagolt sátor mérete) négyzetcentiméterben van megadva.
Az egyik fontos különbség a korábbi példáink és a
jelenlegi között az, hogy az 5. sorban az rdf:Description
elemnek rdf:ID attribútuma van rdf:about helyett.
Az rdf:ID használatával itt egy
erőforrásrész-azonosítót (fragment identifier) specifikáltunk,
amelyet az rdf:ID attribútum értékeként adtunk meg. Ez az
azonosító az item10245, mely nyilván az example.com cég által
megadott egyik katalógustétel száma, és egyben annak a teljes URI
hivatkozásnak a rövidítése, mely az éppen leírt erőforrást (azaz a terméket:
az "Overnighter" típusú sátort) azonosítja. Az item10245
erőforrásrész-azonosító egy bázis-URI-hez viszonyítva értendő, ami
esetünkben a katalógust tartalmazó dokumentum URI-je. A sátort azonosító
teljes URI hivatkozást úgy kapjuk meg, hogy a dokumentum bázis-URI-jének
végéhez, egy "#" karakterrel elválasztva, hozzáillesztjük az
erőforrásrész-azonosítót. Ez tehát így néz ki:
http://www.example.com/2002/04/products#item10245.
Az rdf:ID attribútum némileg hasonlít az XML és a HTML által
használt ID attribútumhoz, mégpedig annyiban, hogy ez is egy
olyan nevet definiál, mely egyedi az aktuális bázis-URI által azonosított
dokumentumon (esetünkben a katalóguson) belül. A példából kitűnik, hogy az
rdf:ID attribútum az item10245 nevet rendelte az
"Overnighter" típusú sátorhoz. Bármilyen más RDF/XML leírás, ami ezen a
katalóguson belül van, hivatkozhat erre a termékre akár az abszolút
URI hivatkozással, ami
http://www.example.com/2002/04/products#item10245, akár a
relatív változatával, ami #item10245.
Ismét hangsúlyozzuk: a relatív URIref úgy értendő, hogy az egy olyan
URIref, amelyet a katalógus bázis-URI-jéhez viszonyítva definiálunk. Egy
hasonló rövidítést használva, az adott sátortípusra vonatkozó URI hivatkozást
így is megadhatnánk a fenti katalógus bejegyzésben:
rdf:about="#item10245" (azaz közvetlenül a relatív URI-vel,
ahelyett, hogy az rdf:ID="item10245" formát választanánk). Mint
rövidítő mechanizmus, a két forma lényegében szinonim, hiszen az RDF/XML az
értéküket mindkét esetben a
http://www.example.com/2002/04/products#item10245 abszolút URI
hivatkozássá terjeszti ki. Az rdf:ID használatakor azonban egy
ellenőrzés is megvalósul, amikor valamilyen nevet rendelünk hozzá, ugyanis az
rdf:ID attribútummal csak egyszer szabad definiálnunk egy nevet
relatív URI-ként ugyanahhoz a bázis-URI-hez viszonyítva. (Vagyis, ugyanazon a
dokumentumon belül egy helyi név csak egyszer deklarálható, de
akárhányszor hivatkozhatunk rá más elemekből).
Bármelyik relatív hivatkozási formát is használnánk, az example.com két
lépésben rendelné hozzá az URI hivatkozást a sátorhoz: először is
hozzárendelne egy URI hivatkozást magához a katalógushoz, majd pedig, már a
katalóguson belül, a sátor tulajdonságainak leírásakor hozzárendelné az adott
katalógustételhez a relatív hivatkozás nevét. A relatív URIref ilyen
használatát úgy is felfoghatjuk, hogy ez annak a teljes URI-nek a rövidítése,
amely az RDF-től függetlenül már hozzá van rendelve a sátorhoz, és
csak hivatkozunk erre (az rdf:about attribútum segítségével), de
felfoghatjuk úgy is, hogy a relatív URIref-et a dokumentumon belül éppen most
deklaráljuk, és éppen most rendeljük hozzá ehhez a katalógustételhez
(az rdf:ID segítségével).
Egy olyan RDF leírás, mely a katalóguson kívül van, az URIref
abszolút változatával hivatkozhatna erre a katalógustételre. Ezt, mint már
említettük, a sátorra mutató relatív URIref és a katalógust azonosító
bázis-URI egybetoldásával állítjuk elő. Tegyük fel, hogy egy túrasportokkal
foglalkozó web alapú szolgáltatás, nevezzük exampleRatings.com-nak,
RDF-et használna a különböző sátrak fogyasztói tetszési indexének a
publikálására. Azt az ötcsillagos minősítést, amelyet az egyik vásárló
(Richard Roe) a 9. példában leírt sátorra adott, az
exampleRatings.com webhely a 10. példában látható
módon regisztrálhatná:
1. <?xml version="1.0"?>
2. <!DOCTYPE rdf:RDF [<!ENTITY xsd "http://www.w3.org/2001/XMLSchema#">]>
3. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
4. xmlns:sportex="http://www.exampleRatings.com/terms/">
5. <rdf:Description rdf:about="http://www.example.com/2002/04/products#item10245">
6. <sportex:ratingBy rdf:datatype="&xsd;string">Richard Roe</sportex:ratingBy>
7. <sportex:numberStars rdf:datatype="&xsd;integer">5</sportex:numberStars>
8. </rdf:Description>
9. </rdf:RDF>
A 10 példa 5. sora egy
rdf:Description elemet használ egy rdf:about
attribútummal, amelynek az értéke a sátort azonosító abszolút URIref. Ennek a
használata egyértelművé teszi, hogy a minősítés (rating) pontosan melyik
termékre vonatkozik.
Ezek a példák több lényeges dolgot is illusztrálnak. Mindenekelőtt azt,
hogy bár az RDF nem specifikálja, és nem is ellenőrzi, hogy miként
rendeljék/rendelték hozzá az URI hivatkozásokat az erőforrásokhoz (esetünkben
a katalógusban szereplő különböző sátrakhoz és más tételekhez), mégis
létrejön az a kívánatos eredmény, hogy a megfelelő URI hivatkozások a
megfelelő erőforrásokhoz vannak hozzárendelve. Ez az eredmény mindig két
folyamat kombinációja révén jön létre: az egyik egy RDF-en kívüli folyamat,
amelynek során egy olyan dokumentumot (esetünkben egy katalógust) látunk el
azonosítóval, mely tartalmazza ezeknek az erőforrásoknak a leírását, a másik
pedig egy olyan, RDF-en belüli folyamat, amelynek során ezen a dokumentumon
belül, az erőforrások leírásakor, a rájuk hivatkozó relatív URI
hivatkozásokat az rdf:ID segítségével deklaráljuk. Például az
example.com cég használhatná ezt a katalógust egy olyan központi forrásként,
amelyben a termékei le vannak írva, annak implicit elfogadásával, hogy ha egy
áru termékszáma nem szerepel a katalógus valamelyik tételének a leírásában,
akkor ez az áru nem tartozik az example.com termékei közé. (Megjegyzendő,
hogy az RDF nem tételezi fel, hogy bármilyen konkrét kapcsolat létezik két
erőforrás között, csak mert az URI hivatkozásuknak ugyanaz a bázis-URI-je,
vagy mert más módon hasonlóak. Egy ilyen kapcsolat esetleg ismert lehet az
example.com számára, de ezt nem definiálja közvetlenül az RDF.)
Ezek a példák egyébként a Web egyik alapvető architekturális alapelvére is
rávilágítanak: arra, hogy bárki szabadon megadhat információkat egy létező
erőforrásról egy tetszése szerinti szókészlet használatával [BERNERS-LEE98]. Ezek a példák azt is mutatják,
hogy az RDF segítségével leírt erőforrásoknak nem kell egyetlen helyen
összegyűjtve lenniük, hanem a weben szétszórva is elhelyezkedhetnek. Ez
nemcsak a példabeli esetünkre igaz, amelyben az egyik szervezet minősít, vagy
kommentál egy olyan erőforrást, amelyet egy másik definiált, hanem olyan
esetekre is érvényes, ahol az erőforrás eredeti definiálója (vagy bárki más)
további információk megadásával erősíteni és gazdagítani kívánja annak az
erőforrásnak a leírását. Ez megtörténhet magának a dokumentumnak a
módosításával, amelyben az erőforrást eredetileg definiálták, vagy pedig,
ahogy az exampleRatings.com is teszi, egy új, külön dokumentum
elkészítésével, amelyben további tulajdonságokat és értékeket ad meg egy
rdf:Description elemben, mely az eredeti erőforrásra hivatkozik
egy rdf:about attribútummal megadott URI-ref
segítségével.
A fenti diszkusszió jelezte, hogy a relatív URI hivatkozások, mint pl. a
#item10245, egy bázis-URI-hez viszonyítva értelmezhetők. Ez
implicit módon annak az erőforrásnak az URI-je lesz, amelyikben a relatív
URIref-et használjuk. Egyes esetekben azonban kívánatos, hogy explicit módon
is specifikálhassuk ezt a bázis-URI-t. Tételezzük fel például, hogy a
http://www.example.com/2002/04/products URI-vel azonosított
katalógust az example.org cég egy duplikát változatban, egy másik, ún.
tükröző webhelyen (mirror site) is szeretné publikálni, amelyet azonosítson,
mondjuk, a http://mirror.example.com/2002/04/products URIref. Ez
problémát okozhatna, hiszen ha az eredeti katalógushoz a tükrözött webhelyen
kívánnánk hozzáférni, akkor a példabeli sátor teljes URI hivatkozását a
leírást tartalmazó dokumentum bázis-URI-jéből állítanánk elő, ami ebben az
esetben a http://mirror.example.com/2002/04/products#item10245
URIref lenne, és nem a kívánt
http://www.example.com/2002/04/products#item10245, vagyis más
erőforrásra hivatkoznánk, mint amire akartunk. Ennek elkerülése érdekében az
example.org feltehetőleg egy explicit bázis-URI-t rendelne a termékeit
azonosító URI hivatkozásokhoz ahelyett, hogy a problémát megkerülendő, csak
egy helyen publikálná a katalógusát.
Hogy az ilyen helyzetekre megoldást adjon, az RDF/XML támogatja az XML
bázis opciót (XML Base [XML-BASE]), mely lehetővé teszi, hogy az XML
dokumentum specifikáljon egy olyan bázis-URI-t, amelyik független a saját
bázis-URI-jétől. A 11. példa azt mutatja meg, hogy
miként írnánk meg a korábbi katalógust az XML Base
felhasználásával:
1. <?xml version="1.0"?>
2. <!DOCTYPE rdf:RDF [<!ENTITY xsd "http://www.w3.org/2001/XMLSchema#">]>
3. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
4. xmlns:exterms="http://www.example.com/terms/"
5. xml:base="http://www.example.com/2002/04/products">
6. <rdf:Description rdf:ID="item10245">
7. <exterms:model rdf:datatype="&xsd;string">Overnighter</exterms:model>
8. <exterms:sleeps rdf:datatype="&xsd;integer">2</exterms:sleeps>
9. <exterms:weight rdf:datatype="&xsd;decimal">2.4</exterms:weight>
10. <exterms:packedSize rdf:datatype="&xsd;integer">784</exterms:packedSize>
11. </rdf:Description>
...további termékek leírásai...
12. </rdf:RDF>
A 11. példa 5. sorában látható
xml:base deklaráció azt specifikálja, hogy egy esetleges további
xml:base deklaráció előfordulásáig, az rdf:RDF
elemen belül a http://www.example.com/2002/04/products URI
tekintendő bázis-URI-nek, és így minden relatív URIref, mely az adott
xml:base attribútum hatályán belül van, a deklarált bázishoz
viszonyítva értendő, mindegy, hogy mi az aktuális dokumentum saját
bázis-URI-je. Ennek eredményeképpen a sátrat azonosító
#item10245 relatív hivatkozást úgy értelmezi az RDF/XML, hogy
annak abszolút URI hivatkozása
http://www.example.com/2002/04/products#item10245, függetlenül
attól, hogy éppen melyik webhelyen publikálják a katalógust. Vagyis,
függetlenül attól, hogy mi a dokumentum aktuális URI-je, sőt még attól is,
hogy a bázis-URI-ref azonosít-e egyáltalán valamilyen konkrét
dokumentumot.
Eddig a példánk csupán egyetlen termék leírását: egy meghatározott
sátortípus leírását mutatta be. Az example.com azonban valószínűleg ajánlani
szeretne többféle sátormodellt, és más termékfajtából is többfélét, például
hátizsákokat, túrabakancsokat stb. A dolgok különböző fajtákba vagy
kategóriákba történő besorolása/osztályozása hasonló koncepció, mint
a programnyelvekben használt objektumok különböző típusokba vagy
osztályokba sorolása. Az RDF támogatja ezt a fogalmat egy előre
definiált tulajdonság, az rdf:type bevezetésével. Amikor egy RDF
erőforrást valamely tulajdonságával leírunk, akkor ennek a tulajdonságnak az
értékét egy olyan erőforrásnak tekintjük, mely a dolgok egy kategóriáját vagy
osztályát képviseli; ennek a tulajdonságnak az alanyát pedig a saját
kategóriája vagy osztálya egyik esetének, előfordulásának
(instance), vagy más szóval: egyedének (individual) tekintjük. A 12. példa az rdf:type használatával
bemutatja, hogy az example.com miként jelezhetné azt, hogy az "item10245"
katalógustétel leírása egy sátorra vonatkozik:
1. <?xml version="1.0"?>
2. <!DOCTYPE rdf:RDF [<!ENTITY xsd "http://www.w3.org/2001/XMLSchema#">]>
3. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
4. xmlns:exterms="http://www.example.com/terms/"
5. xml:base="http://www.example.com/2002/04/products">
6. <rdf:Description rdf:ID="item10245">
7. <rdf:type rdf:resource="http://www.example.com/terms/Tent"/>
8. <exterms:model rdf:datatype="&xsd;string">Overnighter</exterms:model>
9. <exterms:sleeps rdf:datatype="&xsd;integer">2</exterms:sleeps>
10. <exterms:weight rdf:datatype="&xsd;decimal">2.4</exterms:weight>
11. <exterms:packedSize rdf:datatype="&xsd;integer">784</exterms:packedSize>
12. </rdf:Description>
...további termékek leírásai...
13. </rdf:RDF>
A 12. példa 7.sorában az rdf:type
tulajdonság azt jelzi, hogy az éppen leírt erőforrás a
http://www.example.com/terms/Tent URI hivatkozással azonosított
Sátor osztálynak egyik konkrét előfordulása, vagy más szóval: egyik
egyede. Ez feltételezi, hogy az example.com cég már előre definiálta
a saját termék-osztályait ugyanannak a szókészletnek a részeként, mely a cég
többi sajátos szakkifejezését is tartalmazza (mint pl. az
exterms:weight), s így a Tent osztály abszolút
URI-jével hivatkozhatunk rá. Ha az example.com cég a termék-osztályait a
katalóguson belül definiálta volna, akkor a #Tent relatív URIref
segítségével is hivatkozhatnánk a sátorok osztályára.
Az RDF, maga, nem tartalmaz eszközöket a dolgok olyan
alkalmazás-specifikus osztályainak a definiálására, mint pl. a "Sátor", vagy
az olyan tulajdonságaik definiálására, mint pl. az
exterms:weight. Az ilyen osztályokat és tulajdonságokat egy RDF
séma keretében lehet definiálni az RDF Séma nyelv
segítségével, amelyet az 5. fejezet tárgyal. Az
osztályok és tulajdonságok definiálására más eszközök is léteznek, mint pl. a
DAML+OIL és az OWL nyelvek; ezeket az 5.5 szekció mutatja be röviden.
Meglehetősen általános az RDF használatában, hogy az erőforrásokhoz típust
rendelünk az rdf:type tulajdonság segítségével, mely úgy
jellemzi ezeket a forrásokat, mint típusok vagy osztályok konkrét
előfordulását/egyedét. Az ilyen erőforrásokat a gráfban tipizált
csomópontoknak (typed nodes), az RDF/XML leírásban pedig tipizált
csomópont-elemeknek nevezzük. Az RDF/XML szintaxis az ilyen elemek
leírásánál egy speciális rövidítést tesz lehetővé. Ennél a rövidítésnél
kihagyjuk az rdf:type tulajdonságot és az értékét, az
rdf:Description elemet pedig egy másik elemmel helyettesítjük,
amelynek a neve egy olyan minősített név, mely megfelel a kihagyott
rdf:type tulajdonság értékének (vagyis annak az URI
hivatkozásnak, amelyik megnevezi az osztályt). Ennek a rövidítésnek a
használatával az example.com 12. példabeli sátrát a
13. példában megadott módon lehetne leírni:
1. <?xml version="1.0"?>
2. <!DOCTYPE rdf:RDF [<!ENTITY xsd "http://www.w3.org/2001/XMLSchema#">]>
3. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
4. xmlns:exterms="http://www.example.com/terms/"
5. xml:base="http://www.example.com/2002/04/products">
6. <exterms:Tent rdf:ID="item10245">
7. <exterms:model rdf:datatype="&xsd;string">Overnighter</exterms:model>
8. <exterms:sleeps rdf:datatype="&xsd;integer">2</exterms:sleeps>
9. <exterms:weight rdf:datatype="&xsd;decimal">2.4</exterms:weight>
10. <exterms:packedSize rdf:datatype="&xsd;integer">784</exterms:packedSize>
11. </exterms:Tent>
...tov@?bbi termékek leírásai...
12. </rdf:RDF>
Minthogy egy erőforrás leírható egynél több osztály egyedeként is, egy
erőforrásnak lehet több rdf:type tulajdonsága, de ezek közül
csak egy rövidíthető a fenti módszerrel. A többit ki kell írni az
rdf:type tulajdonság segítségével, a 12.
példában illusztrált módon.
Amellett, hogy egy tipizált csomópont-elemmel (mint pl. az
exterms:Tent) megadhatjuk, hogy a leírt egyed melyik felhasználó
által definiált osztályhoz tartozik, az RDF-ben a tipizált csomópont-elem
használata legális olyankor is, amikor olyan beépített RDF osztályok egyedeit
írjuk le, mint amilyen pl. az rdf:Bag. Ez utóbbi osztályokat a
4. fejezet írja le, míg az RDF Séma
osztályokat (mint amilyen pl. az rdfs:Class) az 5. fejezet tárgyalja.
A 12. és a 13. példa
egyaránt jól mutatta, hogy az RDF kijelentéseket le lehet írni az RDF/XML-ben
olyan módon is, amely nagyon emlékeztet a közvetlenül XML-ben (tehát nem
RDF/XML-ben) készült leírásokra. Ez egy lényeges aspektus, tekintettel a
különféle XML alkalmazások egyre növekvő számára, hiszen ez azt sejteti, hogy
az RDF használható lenne ezekben az alkalmazásokban anélkül, hogy nagyobb
változtatásokat kellene végrehajtani abban a módban, ahogyan az
információikat strukturálják.
A fenti példák illusztrálták az RDF/XML szintaxis néhány fundamentális
elemét. Ezek a példák elegendő információt nyújtottak ahhoz, hogy elkezdjünk
hasznos RDF/XML dokumentumokat készíteni. Az RDF/XML szintaxis
specifikációja című (normatív) dokumentum egy alaposabb diszkussziót
tartalmaz azokról az elvekről is, amelyekre az RDF gráfok XML-ben történő
modellezése épül, és amelyeket összefoglalóan "csíkozás" (striping) néven
emleget az RDF/XML zsargon. Ugyanez a dokumentum további lehetőségeket mutat
be az RDF/XML kód írásának rövidítésére, valamint további részleteket és
példákat közöl az RDF adatok XML-be történő átírásához.
4. Az RDF egyéb
lehetőségei
Az RDF számos további lehetőséget is nyújt, amelyekről eddig nem szóltunk.
Ilyenek például a beépített típusok és tulajdonságok, amelyek az erőforrások
és RDF kijelentések csoportos ábrázolására szolgálnak, és ilyenek azok a
lehetőségek is, amelyekkel XML kódrészeket tulajdonságok értékeként
ábrázolhatunk. Ezeket a lehetőségeket ismertetjük e fejezet következő
szekcióiban.
Gyakran szükség van arra, hogy dolgokból csoportokat képezzünk, és így
írjuk le őket. Például Ilyen eset az, amikor ki kell jelentenünk, hogy egy
könyvnek több szerzője, egy tanfolyamnak több hallgatója, vagy egy
szoftvernek több modulja van, és ezeket csoportként kell jellemeznünk és
kezelnünk. Az RDF rendelkezik több, előre definiált (beépített) típussal és
tulajdonsággal, amelyeket arra használhatunk, hogy az ilyen csoportokat
leírjuk.
Először is, az RDF-nek van egy konténer szókészlete, mely három
előre definiált típust tartalmaz (néhány ezekhez kapcsolódó tulajdonsággal
együtt). A konténer egy olyan erőforrás, mely több dolgot tartalmaz.
Ezeket a dolgokat tagoknak nevezzük. A konténer tagjai lehetnek
erőforrások (beleértve az üres csomópontokat is), és lehetnek literálok. Az
RDF háromféle típusú konténert definiál:
rdf:Bag (zsák)rdf:Seq (sorozat, v. szekvencia)rdf:Alt (alternativa-csoport)
A zsák egy olyan erőforrás, amelynek típusa rdf:Bag,
és olyan erőforrások vagy literálok csoportját
ábrázolja, amelyben duplikát tagok is előfordulhatnak, és amelyben nincs
jelentősége a tagok sorrendjének. Egy Bag konténer
leírhatja például alkatrész-számok egy csoportját, ahol a tagok
feldolgozásánál a sorrendnek nincs szerepe.
A sorozat vagy szekvencia egy olyan erőforrás, amelynek
típusa rdf:Seq, és olyan erőforrások vagy literálok csoportját
ábrázolja, amelyben duplikát tagok is előfordulhatnak, és amelyben a tagok
sorrendje szignifikáns. Egy Seq konténer leírhat például egy
olyan csoportot, amelynek a tagjait név szerinti ábécésorrendben kell
tartani.
Az alternatíva-csoport, amelynek típusa rdf:Alt,
olyan erőforrások vagy literálok csoportját ábrázolja, amelyek alternatívák
(tipikusan egy tulajdonság értékének az alternatívái). Egy Alt
konténer leírhatja például egy könyv címének különböző nyelvű, alternatív
fordításait, vagy alternatív webhelyek egy listáját, amelyben egy erőforrás
megtalálható. Egy alkalmazásnak, mely olyan tulajdonságot használ, amelynek
értéke egy Alt konténer, tudnia kell, hogy a konténer bármelyik
tagját választhatja a tulajdonság értékének, amelyik a számára megfelel.
Ahhoz, hogy leírjunk egy erőforrást, mint e konténertípusok egyikét, az
erőforrásnak egy rdf:type tulajdonságot adunk, amelynek értéke
az rdf:Bag, rdf:Seq, vagy rdf:Alt
előre definiált erőforrás valamelyike lesz, attól függően, hogy melyikre van
szükségünk. A konténer erőforrás, ami ugyanúgy lehet egy üres csomópont, mint
egy URI hivatkozással azonosított erőforrás, megjelöli a csoportot mint
egészet. A konténer tagjait úgy írhatjuk le, hogy mindegyikük
számára definiálunk egy konténertagság-tulajdonságot (röviden:
tagságtulajdonságot), amelyeknek alanya egy konténer típusú erőforrás, tárgya
pedig a konténer éppen definiált tagja. A tagságtulajdonságok nevének
formátuma rdf:_n, ahol n egy nem
nulla értékű decimális egész szám, bevezető nullák nélkül, mint pl.
rdf:_1, rdf:_2,
rdf:_3 stb. Ezeket specifikusan a konténer tagjainak leírására
használjuk. A konténertagság és az rdf:type mellett, a
konténer-erőforrásoknak lehetnek más olyan tulajdonságaik is, amelyek leírják
a konténert.
Lényeges, hogy megértsük: noha ezeket a konténertípusokat előre definiált
RDF típusokkal és tulajdonságokkal írjuk le, azok a speciális jelentések,
amelyeket ezekhez a konténerekhez társítunk (pl., hogy egy Alt
konténer tagjai alternatív értékek), csupán szándékolt jelentések. Ezeket a
specifikus konténertípusokat, és ezek definícióit azzal a szándékkal
tervezték, hogy egy közös konvenciót teremtsenek azok között, akik
csoportokat kívánnak leírni. Amit az RDF tesz, az csak annyi, hogy biztosítja
azokat a típusokat és tulajdonságokat, amelyekkel leírható bármelyik
konténerfajta gráfja. Az RDF ugyanúgy nem érti önmagától, hogy milyen
erőforrás az rdf:Bag típusú erőforrás, mint ahogy nem érti,
milyen erőforrás, mondjuk, az ex:Tent típusú erőforrás (a 3.2 szekcióból). Minden egyes esetben az
alkalmazásokat úgy kell megírni, hogy annak a jelentésnek megfelelően
működjenek, amelyet az általuk alkalmazott konténertípusok hordoznak. Ezt a
témát a következő példák kapcsán bővebben is kifejtjük.
Egy konténer tipikus alkalmazása annak a jelzése, hogy egy tulajdonság
értéke bizonyos dolgok egy csoportja. Például, ha azt a mondatot akarjuk
ábrázolni, hogy "A 6.001 számú tanfolyam hallgatói: Mohamed, Johann, Maria és
Phuong", akkor a tanfolyamot úgy írhatjuk le, hogy adunk neki egy
s:students tulajdonságot (egy megfelelő szókészletből), amelynek
értéke egy rdf:Bag típusú konténer, mely a hallgatók csoportját
ábrázolja. Azután a konténertagság-tulajdonság segítségével az egyes
hallgatókat úgy azonosítjuk, mint ennek a csoportnak a tagjait, ahogy a 14. ábrán látható gráf mutatja:
Mivel az s:students tulajdonság értéke ebben a példában egy
Bag formájában van leírva, nincs szándékolt jelentése annak a
sorrendnek, amelyben a hallgatókat azonosító URI hivatkozások fel vannak
sorolva, akkor sem, ha a gráfban a tagságtulajdonságok sorszámokat
tartalmaznak a nevükben. Kizárólag azoknak az alkalmazásoknak a
kompetenciája, hogy figyelembe veszik-e, vagy sem a tagságtulajdonságokban
szereplő nevek (számmal jelzett) sorrendjét, amelyek előállítják vagy
feldolgozzák az rdf:Bag típusú konténert tartalmazó gráfot.
Az RDF/XML tartalmaz néhány olyan speciális szintaktikai elemet, illetve
rövidítési lehetőséget, amelyek egyszerűbbé teszik az ilyen konténerek
leírását. A 14. példa a következőképpen írja le a 14. ábrán bemutatott gráfot:
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:s="http://example.org/students/vocab#">
<rdf:Description rdf:about="http://example.org/courses/6.001">
<s:students>
<rdf:Bag>
<rdf:li rdf:resource="http://example.org/students/Amy"/>
<rdf:li rdf:resource="http://example.org/students/Mohamed"/>
<rdf:li rdf:resource="http://example.org/students/Johann"/>
<rdf:li rdf:resource="http://example.org/students/Maria"/>
<rdf:li rdf:resource="http://example.org/students/Phuong"/>
</rdf:Bag>
</s:students>
</rdf:Description>
</rdf:RDF>
A 14. példából látható, hogy az RDF/XML-nek van
egy rdf:li nevű beépített tulajdonsága, amellyel elkerülhetjük,
hogy explicit módon sorszámoznunk kelljen az összes tagságtulajdonságot.
Ennek használatakor a gráfnak megfelelő rdf:_1,
rdf:_2 stb. számozott tulajdonságokat az rdf:li
elemekből generálja az RDF/XML. Az rdf:li elem mnemonikus neve a
HTML-ből is ismert "list item" (lista-elem) kifejezés rövidítése. Vegyük
észre azt is, hogy az <rdf:Bag> elem itt bele van ágyazva
az <s:students> tulajdonság-elembe. Az
<rdf:Bag> elem egy újabb példája a 13. példában már alkalmazott rövidítésnek, ahol
egyetlen elemmel helyettesítettük az rdf:Description és az
rdf:type elemet, amikor leírtuk egy típus egyik előfordulását.
(Esetünkben az rdf:Bag egyik előfordulását írjuk le ilyen
rövidített formában, amikor beágyazzuk az s:students elembe.)
Minthogy itt nem specifikáltunk URI hivatkozást, a Bag konténert egy üres
csomópont reprezentálja a gráfban. Ennek beágyazása az
<s:students> elembe egy rövidített ábrázolása annak, hogy
az üres csomópont az <s:students> tulajdonság értéke. Az
ilyen rövidítési módszereket az [RDF-SZINTAXIS]
tárgyalja bővebben.
A rdf:Seq konténer gráfstruktúrája, és az annak megfelelő
RDF/XML leírás hasonló az rdf:Bag ugyanilyen ábrázolásához,
azzal a különbséggel, hogy a konténertípus itt rdf:Seq. Itt is
hangsúlyozzuk, hogy bár az rdf:Seq konténer szándékoltan
explicit sorrendet ábrázol a tagok között, mégis kizárólag a gráfot előállító
és felhasználó alkalmazások dolga, hogy megfelelően interpretálják az egész
számokkal megadott tulajdonságnevek sorrendjét.
Azért, hogy illusztráljunk egy Alt konténert is, a 15. ábrán ábrázoljuk a következő mondat gráfját: "Az X11
forráskódja megtalálható az ftp.example.org, az ftp1.example.org vagy az
ftp2.example.org webhelyen":
A 15. példa azt illusztrálja, hogy miként
írhatjuk le RDF/XML-ben a 15. ábrán ábrázolt
gráfot:
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:s="http://example.org/packages/vocab#">
<rdf:Description rdf:about="http://example.org/packages/X11">
<s:DistributionSite>
<rdf:Alt>
<rdf:li rdf:resource="ftp://ftp.example.org"/>
<rdf:li rdf:resource="ftp://ftp1.example.org"/>
<rdf:li rdf:resource="ftp://ftp2.example.org"/>
</rdf:Alt>
</s:DistributionSite>
</rdf:Description>
</rdf:RDF>
Az Alt konténert arra tervezték, hogy legalább egy tagot
tartalmazzon, amelyet az rdf:_1 tulajdonság azonosít. Az ehhez
társított tagot a tulajdonság alapértelmezett értékének, vagy preferált
értékének tekintjük. A többi tag sorrendje közömbös, és a rangjuk is
azonos.
A 15. ábrán szereplő RDF gráf (ahogyan le van
leírva) egyszerűen azt mondja ki, hogy az s:DistributionSite
tulajdonság maga az Alt konténer erőforrás. Minden további jelentés, ami
ennek a gráfnak tulajdonítható (például, hogy az Alt konténer egyik
tagja az s:DistributionSite tulajdonság értékének
tekintendő, vagy hogy az ftp://ftp.example.org az
alapértelmezett érték), bele kell hogy épüljön a feldolgozó alkalmazásnak az
Alt konténer vagy az s:DistributionSite tulajdonság szándékolt
jelentését interpretáló logikájába.
Az Alt konténereket gyakran használják a nyelvi címkézéssel
összefüggésben. (Az RDF/XML megengedi az xml:lang attribútum
használatát, amelyet az [XML] dokumentum definiál, és
amely annak jelzésére szolgál, hogy az adott elem tartalma az attribútum
értékeként megadott természetes nyelven íródott. Az xml:lang
használatát az [RDF-SZINTAXIS] ismerteti, az
illusztrációja pedig könyvünk 6.2 szekciójában látható.)
Például egy olyan publikációnak a title tulajdonsága, amelynek a
címét több nyelvre is lefordították, egy olyan Alt konténerre mutathat,
amelynek a literál-értékekkel megadott tagjai a cím különböző nyelvű
fordításait ábrázolják.
A Bag és az Alt szándékolt jelentése közötti különbséget jól illusztrálja
pl. a "Huckleberry Finn kalandjai" című regény szerzőjének ábrázolása. A
könyvnek egyetlen szerzője van, de két néven is ismerjük (Mark Twain és
Samuel Clemens). Bármelyik név elégséges arra, hogy specifikáljuk vele a
szerzőt. Így, ha egy Alt konténert használunk a szerző neveinek megadására,
az pontosabban írja le a szerzőségi viszonyt, mintha egy Bag konténerrel
adtuk volna meg (amelyik azt sugallná, hogy a könyvnek két különböző
szerzője van).
A felhasználók szabadon eldönthetik, hogy mivel, és hogyan írják le az
erőforrások csoportjait, ha nem kívánják az RDF konténer-szókészletét
használni. Ezt ugyanis csak azért definiálták, hogy legyenek olyan közös
definíciók, amelyeket, ha általánosan használunk, megnövelik azoknak az
alkalmazásoknak az együttműködőképességét, amelyek erőforrás-csoportokat
tartalmazó adatokat használnak.
Néha egyenértékű alternatívákat találunk az RDF konténertípusainak
használata helyett. Például egy erőforrás, és más erőforrások egy csoportja
közötti viszony ábrázolható úgy is, hogy az első erőforrást több olyan
kijelentés alanyává tesszük, amelyek ugyanazt a tulajdonságot használják. Ez
strukturálisan különbözik attól a megoldástól, ahol ez az erőforrás csupán
egyetlen olyan kijelentés alanya, amelynek a tárgya egy több tagot tartalmazó
konténer. Ez a két különböző struktúra egyik esetben jelentheti ugyanazt, a
másik esetben pedig nem. Amikor el kell döntenünk, hogy egy adott
szituációban melyiket használjuk, az esetleges különbséget fel kell
ismernünk.
Példaképpen tekintsük egy írónő és a publikációi között fennálló viszonyt
az alábbi mondatban:
Sue has written "Anthology of Time", "Zoological Reasoning", and
"Gravitational Reflections".
(Ez a mondat azt jelenti ki, hogy Sue írta az idézett című publikációkat).
Ebben az esetben három erőforrásunk van, amelyek mindegyikéről önállóan
kijelenthető, hogy ugyanaz a szerző írta. Ezt kifejezhetjük ismételt
tulajdonságok használatával:
exstaff:Sue exterms:publication ex:AnthologyOfTime .
exstaff:Sue exterms:publication ex:ZoologicalReasoning .
exstaff:Sue exterms:publication ex:GravitationalReflections .
Ebben a példában nem állapítunk meg egyéb viszonyt ezek között a
publikációk között, mint azt, hogy ugyanaz a szerző írta őket. A kijelentések
mindegyike egy független tény, s ezért az ismételt tulajdonságok használata
értelmes választás lenne. De ugyanilyen értelmes lenne ezt a viszonyt
egyetlen olyan kijelentéssel ábrázolni, mely olyan erőforrások csoportjára
vonatkozik, amelyeket Sue írt:
exstaff:Sue exterms:publication _:z .
_:z rdf:type rdf:Bag .
_:z rdf:_1 ex:AnthologyOfTime .
_:z rdf:_2 ex:ZoologicalReasoning .
_:z rdf:_3 ex:GravitationalReflections .
Nézzük meg ugyanakkor az alábbi mondatot:
The resolution was approved by the Rules Committee, having members Fred,
Wilma, and Dino.
Ez azt mondja: "A határozatot (resolution) elfogadta (approved by) a
Szabálybizottság (Rules Committee), amelynek a tagjai Fred, Wilma és Dino. Ez
a mondat csak azt állítja, hogy a bizottság mint egész elfogadta a
határozatot, azt azonban nem, hogy minden tagja egyenként is
elfogadta volna. Ebben az esetben félrevezető lenne három külön
exterms:approvedBy elemi kijelentéssel modellezni a fenti
mondatot, mint ahogy ezt az alábbi RDF leírás teszi:
ex:resolution exterms:approvedBy ex:Fred .
ex:resolution exterms:approvedBy ex:Wilma .
ex:resolution exterms:approvedBy ex:Dino .
hiszen ez a leírás minden bizottsági tagról egyenként kijelenteni, hogy
elfogadta a határozatot, holott az eredeti mondatban nem erről van szó.
Ebben az esetben célszerűbb lenne egyetlen olyan
exterms:approvedBy kijelentéssel modellezni a mondatot, amelynek
alanya az ex:resolution, tárgya pedig az
ex:rulesCommittee. Ezzel már (helyesen) azt jelentenénk ki, hogy
a határozatot elfogadta a bizottság mint egész. A Rules Commitee erőforrás
azután leírható egy Bag konténerrel, amelynek a tagjai azonosak a bizottság
tagjaival, ahogy az alábbi tripletekben látható:
ex:resolution exterms:approvedBy ex:rulesCommittee .
ex:rulesCommittee rdf:type rdf:Bag .
ex:rulesCommittee rdf:_1 ex:Fred .
ex:rulesCommittee rdf:_2 ex:Wilma .
ex:rulesCommittee rdf:_3 ex:Dino .
Amikor RDF konténereket használunk, fontos megértenünk, hogy a
kijelentéseink nem konstruálják a konténert, mint a programozási
nyelvek adatstruktúrái esetén. Valójában a kijelentések itt csupán
leírják a konténert (a dolgok egy csoportját), amely feltehetően a
világban létező entitás. Például az imént látott példában a Szabálybizottság
mindenképpen emberek rendezetlen halmaza, akár ilyennek írjuk le RDF-ben,
akár nem. Azzal, hogy azt mondjuk az ex:rulesCommittee
erőforrásról, hogy annak típusa rdf:Bag, még nem állítjuk, hogy
a Szabálybizottság egy adatstruktúra, és nem is konstruálunk ezzel egy
konkrét adatstruktúrát a csoport tagjai számára (a Szabálybizottság leírható
volna Bag konténerként anélkül is, hogy akár egyetlen tagját is leírnánk).
Ehelyett csupán azt állítjuk a Szabálybizottságról, hogy olyan jellemzőkkel
rendelkezik, amelyek megfelelnek a Bag konténerhez társított jellemzőknek,
nevezetesen, hogy tagjai vannak, és hogy a tagok leírásának sorrendje nem
szignifikáns. Hasonlóképpen, a konténertagság-tulajdonságok használatával is
csupán azt írjuk le a konténer erőforrásról, hogy bizonyos dolgokat
tartalmaz, amelyeket a tagjainak tekintünk. Ez pedig nem szükségszerűen
jelenti azt, hogy a tagjaiként leírt dolgokon kívül nincsenek más
tagjai. Például a fenti tripletek, amelyekkel leírtuk a bizottság tagjait,
csupán azt mondják ki, hogy Fred, Wilma és Dino tagjai a
bizottságnak, de azt nem, hogy csak ők a tagjai.
Ugyanígy, a 14. és a 15.
példában is illusztráltunk egy általános "mintát" a konténerek leírására,
függetlenül a használt konténer típusától (pl. bemutattuk egy üres csomópont
használatát, mely egy megfelelő rdf:type tulajdonsággal magát a
konténert ábrázolta, és bemutattuk az rdf:li használatát,
amellyel legeneráltattuk a sorszámozott konténertagság-tulajdonságokat).
Fontos tehát megértenünk, hogy az RDF nem erőlteti az RDF konténer
szókészlet kizárólag ilyen célú használatát, vagyis, használhatjuk ezt a
szókészletet más módon, és más célokra is. Például: egyes esetekben célszerű
lehet egy URI hivatkozással rendelkező konténer erőforrást használni üres
csomópont helyett. Sőt, mi több,
használhatjuk a konténer szókészletet oly módon is, hogy szintaktikailag nem
feltétlenül jól formált (not well-formed) struktúrájú gráfokat írunk le vele,
ahogyan az előző példáink is mutatták. A 16. példa
is (lásd alább) egy olyan gráf RDF/XML leírását mutatja be, amely hasonló a
15. ábrán már bemutatott konténerhez, de amelyik
explicit módon kiírja a konténertagság-tulajdonságokat ahelyett, hogy az
rdf:li használatával legeneráltatná azokat:
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:s="http://example.org/packages/vocab#">
<rdf:Description rdf:about="http://example.org/packages/X11">
<s:DistributionSite>
<rdf:Alt>
<rdf:type rdf:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#Bag"/>
<rdf:_2 rdf:resource="ftp://ftp.example.org"/>
<rdf:_2 rdf:resource="ftp://ftp1.example.org"/>
<rdf:_5 rdf:resource="ftp://ftp2.example.org"/>
</rdf:Alt>
</s:DistributionSite>
</rdf:Description>
</rdf:RDF>
Amint az [RDF-SZEMANTIKA] dokumentum
megjegyzi, az RDF nem köt ki "jól formáltsági" feltételeket a konténer
szókészlet használatára, és így a 16. példa teljesen
legális, noha a konténert egyidejűleg Bag és Alt típusúnak is
leírtuk, mégpedig úgy, hogy az rdf:_2 tulajdonságának két
különböző értéket adtunk, és emellett még nem is tartalmaz a konténer
rdf:_1, rdf:_3, vagy rdf:_4
tulajdonságokat.
Ennek következtében azokat az RDF alkalmazásokat, amelyek azt igénylik,
hogy a konténerek "jól formáltak" legyenek, úgy kell megírni, hogy
ellenőrizzék a konténer szókészlet korrekt használatát, annak érdekében, hogy
kellően stabilak és robusztusak maradjanak.
A 4.1 szekcióban ismertetett konténerek egyik
hiányossága, hogy nem adnak lehetőséget arra, hogy lezárjuk őket,
vagyis, hogy azt mondjuk: "ez az összes tagja a konténernek". Mint a 4.1 szekcióban megjegyeztük, egy konténer mindössze
azt mondja, hogy néhány azonosított erőforrás a tagja; azt azonban nem
jelenti ki, hogy nincsenek más tagjai. Így akkor is, amikor egy gráf leírja
egy konténer néhány tagját, nem lehet kizárni, hogy esetleg létezik valahol
egy másik olyan gráf, mely néhány további tagját is leírja. Szerencsére, az
RDF támogatja olyan csoportok leírását is, RDF kollekciók
formájában, amelyekről biztosan tudható, hogy csakis a leírt tagokat
tartalmazzák. Egy RDF kollekció a dolgok egy csoportja, amelyet egy
lista-struktúra formájában ábrázolunk az RDF gráfban. Ezt a lista-struktúrát
egy előre definiált kollekció szókészlet segítségével konstruáljuk,
mely az rdf:List típusból, az rdf:first ("első
eleme") és rdf:rest ("maradék része")
tulajdonságokból, valamint a szintén előre definiált rdf:nil
("üres lista") erőforrásból áll.
Ha kollekcióval kívánnánk leírni pl. azt a mondatot, hogy "A 6.001. számú
tanfolyam hallgatói Amy, Mohamed és Johann", akkor a 16.
ábrán látható gráfot ábrázolnánk:
Ebben a gráfban a kollekció minden egyes tagja, mint pl.
s:Amy, egy rdf:first tulajdonság tárgya, s ez
utóbbinak az alanya pedig egy erőforrás (példánkban ez üres csomópont), mely
a listát képviseli. Ezt a lista típusú erőforrást egy rdf:rest
tulajdonsággal kapcsoljuk a lista maradék részéhez. A lista végét egy
rdf:nil értékkel rendelkező rdf:rest tulajdonság
jelzi, ahol az rdf:nil egy rdf:List típusú üres
listát reprezentál. Ez a szerkezet ismerős lehet azok számára, akik ismerik a
Lisp programozási nyelvet. Ugyanúgy, mint a Lisp-ben, az
rdf:first és az rdf:rest tulajdonságok lehetővé
teszik az alkalmazásoknak, hogy sorban végigmenjenek a struktúrán. Minden
üres csomópont, mely ezt a listát alkotja, eleve rdf:List típusú
(azaz, e csomópontok mindegyikének van egy implicit rdf:type
tulajdonsága, amelynek az értéke az rdf:List előre definiált
típus), habár ezt explicit módon nem mutatja a gráf. Az RDF Séma nyelv [RDF-SZÓKÉSZLET] úgy definiálja az
rdf:first és az rdf:rest tulajdonságot, hogy ezek
alanya egy rdf:List típusú csomópont, tehát az a tény, hogy ezek
a csomópontok listák, általában kikövetkeztethető, s így a nekik megfelelő
rdf:type tripleteket nem kell állandóan ismételve kiírni.
Az RDF/XML támogat egy speciális írásmódot is, amelyik megkönnyíti az
ilyen gráffal megadott kollekciók leírását. Az RDF/XML-ben egy kollekció
leírható egy olyan tulajdonságelemmel, amelynek van egy
rdf:parseType="Collection" attribútuma, és amelynek a tartalma
olyan beágyazott elemek egy csoportja, amelyek a kollekció tagjait
ábrázolják. Az RDF/XML annak jelzésére használja az
rdf:parseType attribútumot, hogy az adott elem tartalmát
speciális módon kell értelmezni. Esetünkben az
rdf:parseType="Collection" attribútum azt jelzi, hogy a
beágyazott elemeket a kollekciónak megfelelő listaszerkezetet ábrázoló gráf
előállítására kell használni, vagy hogy egy ilyen gráf RDF/XML leírásaként
kell értelmezni. (Az rdf:parseType attribútum egyéb lehetséges
értékeit tankönyvünk későbbi fejezeteiben tárgyaljuk.)
Annak érzékeltetésére, hogy hogyan működik az
rdf:parseType="Collection", a 17.
példában leírjuk azt az RDF/XML kódot, mely a 16.
ábrán szereplő gráfot eredményezi:
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:s="http://example.org/students/vocab#">
<rdf:Description rdf:about="http://example.org/courses/6.001">
<s:students rdf:parseType="Collection">
<rdf:Description rdf:about="http://example.org/students/Amy"/>
<rdf:Description rdf:about="http://example.org/students/Mohamed"/>
<rdf:Description rdf:about="http://example.org/students/Johann"/>
</s:students>
</rdf:Description>
</rdf:RDF>
Az rdf:parseType="Collection" használata XML-ben mindig egy
olyan lista-struktúrát definiál, mint amilyent a 16.
ábra mutat, azaz egy rögzített, véges számú elemet tartalmazó, adott
hosszúságú listát, amelyet egy rdf:nil zár le, és amelyik olyan
"új" üres csomópontokat használ, amelyek egyediek a lista-struktúrán belül.
Az RDF azonban nem erőlteti, hogy az RDF kollekciós szókészletét kizárólag
ilyen módon, és ilyen célra használjuk; valójában használhatjuk ezt más
módokon, más célokra is (beleértve még azt is, hogy esetleg nem listát és nem
zárt kollekciót írunk le vele). Hogy lássuk, miért van ez így, figyeljük meg,
hogy a 16. ábrán látható gráfot leírhatjuk
RDF/XML-ben úgy is, hogy kiírjuk ugyanazokat a tripleteket a hosszabb
írásmóddal (vagyis az rdf:parseType="Collection" használata
nélkül), ahogyan a 18. példa mutatja:
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:s="http://example.org/students/vocab#">
<rdf:Description rdf:about="http://example.org/courses/6.001">
<s:students rdf:nodeID="sch1"/>
</rdf:Description>
<rdf:Description rdf:nodeID="sch1">
<rdf:first rdf:resource="http://example.org/students/Amy"/>
<rdf:rest rdf:nodeID="sch2"/>
</rdf:Description>
<rdf:Description rdf:nodeID="sch2">
<rdf:first rdf:resource="http://example.org/students/Mohamed"/>
<rdf:rest rdf:nodeID="sch3"/>
</rdf:Description>
<rdf:Description rdf:nodeID="sch3">
<rdf:first rdf:resource="http://example.org/students/Johann"/>
<rdf:rest rdf:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#nil"/>
</rdf:Description>
</rdf:RDF>
Ahogyan az [RDF-SZEMANTIKA] megjegyzi, és
ahogyan a 4.1 szekcióban leírt konténer
szókészlet kapcsán is felmerült, az RDF nem
köti ki a "jól formáltság" ("well-formedness") követelményét a kollekciós
szókészlet használatában sem. Így tehát, amikor a tripleteket kiírjuk a
hosszabb írásmóddal, akkor definiálhatjuk az RDF gráfokat egy kevésbé jól
strukturált formában, vagyis nem úgy, ahogyan azokat az RDF automatikusan
generálja, amikor az rdf:parseType="Collection"-ra épülő
rövidített írásmódot használjuk. Például, nem illegális azt kijelenteni, hogy
egy adott csomópont rdf:first tulajdonságának két különböző
értéke van, ugyanis ezzel előállíthatunk olyan lista-szerkezeteket is,
amelyeknek a vége elágazik, vagy nem listaként folytatódik, vagy egyszerűen
csak kihagyhatjuk vele a kollekció egy részének a leírását. Hasonlóképpen, az
olyan gráfok, amelyeket a kollekciós szókészlettel a hosszabb írásmódban
definiálunk, URI hivatkozásokat is használhatnak a lista komponenseinek
azonosítására az üres csomópontok helyett (amelyek a lista-struktúrán belül
egyediek). Ebben az esetben lehetséges volna tripleteket kreálni más
gráfokban is, amelyek további elemeket adhatnának a kollekcióhoz, és ily
módon nyílttá válhatna a kollekció.
Ennek következtében, azokat az RDF alkalmazásokat, amelyek azt igénylik,
hogy a kollekciók "jól formáltak" legyenek, úgy kell megírni, hogy
ellenőrizzék a kollekciós szókészlet korrekt használatát, ha stabilak és
robusztusak akarnak maradni. Emellett az olyan nyelvek, mint pl. az [OWL], amelyek további korlátozásokat definiálhatnak az
RDF gráfok struktúrájával kapcsolatban, eleve ki is zárhatják az ilyen
speciális szerkezetek egyik vagy másik változatát.
Az RDF alkalmazásoknak néha RDF kijelentésekkel kell leírniuk más RDF
kijelentéseket. Ilyen eset pl. az, ha információt kell rögzíteni arról, hogy
mikor készítették az adott kijelentéseket, ki készítette őket, vagy más
hasonló információt, amelyeket néha származási információknak hívunk.
Emlékezzünk a 3.2 szekcióban bemutatott 9. példára, mely leír egy
exproducts:item10245 URI hivatkozással azonosított sátort,
amelyet az example.com ajánl az Interneten: ennek a leírásnak az egyik
tripletje, mely leírja a sátor súlyát, a következő volt:
exproducts:item10245 exterms:weight "2.4"^^xsd:decimal .
Itt nagyon hasznos lenne, ha az example.com azt is rögzítené, hogy kitől
származik ez az információ.
Az RDF-nek van egy olyan beépített szókészlete, amellyel magukról az RDF
kijelentésekről is lehet kijelentéseket tenni. Azt az eljárást, amelynek
során ezzel a szókészlettel leírunk egy kijelentést, tárgyiasításnak
hívjuk, e művelet eredményét pedig az adott kijelentés
tárgyiasulásának, vagy megtestesülésének nevezzük. Az RDF
tárgyiasító szókészlete az rdf:Statement típusból és az
rdf:subject, rdf:predicate és
rdf:object tulajdonságokból áll (ezek jelentése ebben a
sorrendben: Kijelentés, "alanya", "állítmánya", "tárgya"). Az RDF
rendelkezésünkre bocsátja ugyan ezt a tárgyiasító szókészletet, de csak
óvatosan szabad élnünk vele, mert nagyon könnyű abba a tévedésbe esni, hogy a
szókészlettel olyan dolgokat definiálunk, amelyek ténylegesen még nincsenek
definiálva. Erről később még ejtünk néhány szót.
A tárgyiasító szókészlet használatával most tárgyiasítsuk az említett
sátor súlyáról szóló kijelentést oly módon, hogy hozzárendeljük az
exproducts:triple12345 URI hivatkozást, mely alanyként ezt a
kijelentést azonosítja, majd pedig leírjuk az eredeti kijelentés egyes
részeit az alábbi tripletekkel:
exproducts:triple12345 rdf:type rdf:Statement .
exproducts:triple12345 rdf:subject exproducts:item10245 .
exproducts:triple12345 rdf:predicate exterms:weight .
exproducts:triple12345 rdf:object "2.4"^^xsd:decimal .
Ezek az elemi kijelentések azt fogalmazzák meg, hogy az
exproducts:triple12345 URI hivatkozással azonosított erőforrás
"típusa" Kijelentés, és ennek a kijelentésnek az "alanya" az
exproducts:item10245 erőforrásra mutat, az "állítmánya" az
exterms:weight tulajdonságra, a "tárgya" pedig egy olyan
decimális egész számra, amelyet a "2.4"^^xsd:decimal tipizált
literál ábrázol. Tegyük fel, hogy az eredeti kijelentést ténylegesen az
exproducts:triple12345 azonosítja, és hasonlítsuk össze az
eredeti kijelentést a tárgyiasult változatával: világosan látható hogy a
tárgyiasítás ténylegesen leírja az eredeti kijelentést. Az RDF tárgyiasító
szókészletének konvenció szerinti használata során mindig a fenti
minta szerinti négy kijelentéssel (a "tárgyiasító négyes"-nek is nevezett
kijelentésekkel) írunk le egy másik kijelentést.
A tárgyiasítás konvencionális használatával az example.com cég rögzíthetné
pl. azt a tényt, hogy John Smith írta a fenti kijelentést a sátor súlyáról,
oly módon, hogy először hozzárendelné az exproducts:triple12345
URI hivatkozást, mint az előbb, majd elvégezné az eredeti kijelentés
tárgyiasítását a fentebb megadott módon, és végül, folytatva a tárgyiasítást,
hozzá adna egy elemi kijelentést arról, hogy az
exproducts:triple12345 URI-vel azonosított eredeti kijelentés
szerzője (dc:creator) az exstaff:85740 alkalmazotti
sorszámmal azonosított John Smith. Az eljárás során az alábbi kijelentéseket
kellene leírnunk:
exproducts:triple12345 rdf:type rdf:Statement .
exproducts:triple12345 rdf:subject exproducts:item10245 .
exproducts:triple12345 rdf:predicate exterms:weight .
exproducts:triple12345 rdf:object "2.4"^^xsd:decimal .
exproducts:triple12345 dc:creator exstaff:85740 .
Az eredeti kijelentés, annak tárgyiasított változata, valamint az ehhez
hozzáadott új kijelentés John Smith szerzőségéről, a 17.
ábrán látható gráfot eredményezné:
Ezt a gráfot, RDF/XML-ben, a 19. példában
bemutatott módon írhatjuk le:
<?xml version="1.0"?>
<!DOCTYPE rdf:RDF [<!ENTITY xsd "http://www.w3.org/2001/XMLSchema#">]>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:exterms="http://www.example.com/terms/"
xml:base="http://www.example.com/2002/04/products">
<rdf:Description rdf:ID="item10245">
<exterms:weight rdf:datatype="&xsd;decimal">2.4</exterms:weight>
</rdf:Description>
<rdf:Statement rdf:about="#triple12345">
<rdf:subject rdf:resource="http://www.example.com/2002/04/products#item10245"/>
<rdf:predicate rdf:resource="http://www.example.com/terms/weight"/>
<rdf:object rdf:datatype="&xsd;decimal">2.4</rdf:object>
<dc:creator rdf:resource="http://www.example.com/staffid/85740"/>
</rdf:Statement>
</rdf:RDF>
A 3.2 szekció bemutatta az rdf:ID
attribútum használatát RDF/XML-ben, amelynek segítségével egy
rdf:Description elemben lerövidíthettük a kijelentés alanyát
azonosító URI hivatkozást. Az rdf:ID azonban használható egy
tulajdonság-elemben is, például arra, hogy automatikusan előállítsa
annak a tripletnek a tárgyiasítását, amelyet a tulajdonság-elem generál. A 20. példa megmutatja, hogyan használhatjuk ki ezt a
lehetőséget arra, hogy előállítsuk ugyanazt a gráfot, amelyet a 19. példában már előállítottunk:
<?xml version="1.0"?>
<!DOCTYPE rdf:RDF [<!ENTITY xsd "http://www.w3.org/2001/XMLSchema#">]>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:exterms="http://www.example.com/terms/"
xml:base="http://www.example.com/2002/04/products">
<rdf:Description rdf:ID="item10245">
<exterms:weight rdf:ID="triple12345" rdf:datatype="&xsd;decimal">2.4
</exterms:weight>
</rdf:Description>
<rdf:Description rdf:about="#triple12345">
<dc:creator rdf:resource="http://www.example.com/staffid/85740"/>
</rdf:Description>
</rdf:RDF>
Ebben a változatban az rdf:ID="triple12345" attribútum
megadása az exterms:weight elemben azt az eredeti tripletet
eredményezi, amelyik leírta a sátor súlyát:
exproducts:item10245 exterms:weight "2.4"^^xsd:decimal .
valamint a tárgyiasításának tripletjeit:
exproducts:triple12345 rdf:type rdf:Statement .
exproducts:triple12345 rdf:subject exproducts:item10245 .
exproducts:triple12345 rdf:predicate exterms:weight .
exproducts:triple12345 rdf:object "2.4"^^xsd:decimal .
Ezeknek a tárgyiasító tripleteknek az alanya egy olyan teljes URIref,
amely úgy alakul ki, hogy egybetoldjuk a bázis URI-t (amelyet az
xml:base deklarációban adtunk meg) egy "#"
karakterrel (ami jelzi, hogy erőforrásrész-azonosító következik), valamint az
rdf:ID attribútum értékével; vagyis a tripleteknek ugyanaz lesz
az alanyuk, mint az előző példákban: exproducts:triple12345.
Jegyezzük meg azonban, hogy a tárgyiasítás kijelentése nem azonos az
eredeti kijelentéssel, és nem is implikálja azt. Ha ugyanis valaki azt
mondja, hogy John mondott valamit a sátor súlyáról, az nem magáról a sátor
súlyáról állít valamit, hanem arról, hogy John mondott valamit valamiről.
Vagy megfordítva: amikor valaki leírja a sátor súlyát, az nem arról állít
valamit, hogy ki, mit mondott.
A fenti szöveg nem véletlenül fogalmazott úgy, több helyen is, hogy a
"tárgyiasítás konvenció szerinti használata". Mint már korábban megjegyeztük,
óvatosságra van szükség, amikor a tárgyiasító szókészletet használjuk, mert
könnyű úgy képzelni, hogy ezzel a szókészlettel valami olyan dolgot
definiálunk, ami még nincs definiálva. Ha vannak olyan alkalmazások, amelyek
sikeresen használják a tárgyiasítást, akkor ez azért van, mert bizonyos
konvenciókat követnek, és olyan feltételezésekkel élnek, amelyek többletet
jelentenek ahhoz a tényleges jelentéshez képest, amit az RDF definiál a
tárgyiasító szókészletében, és többletet jelentenek azokhoz az eszközökhöz
képest is, amelyeket ennek a szókészletnek a támogatásához az RDF nyújt.
Mindenekelőtt fontos megjegyezni, hogy a tárgyiasítás konvenciószerű
használatánál a tárgyiasító tripletek alanyáról feltételezzük, hogy az egy
konkrét tripletet azonosít egy konkrét RDF dokumentumban, és nem valamiféle
tetszőleges tripletet, amelynek ugyanaz az alanya, az állítmánya és a tárgya.
Ezt a konvenciót azért használjuk, mert a tárgyiasítást elsősorban olyan
tulajdonságok kifejezésére szánták, mint pl. a kijelentés készítési dátuma,
vagy az információ eredete (amire az eddigi példáinkban is használtuk), és az
ilyen tulajdonságokat mindig meghatározott tripletekre alkalmazzuk. Létezhet
több olyan triplet, amelynek ugyanaz az alanya, állítmánya és tárgya, és noha
egy gráf mindig tripletek halmazaként van definiálva, ugyanaz a
triplet-struktúra előfordulhat több különböző dokumentumban is. Hogy tehát
ezt a konvenciót teljes mértékben támogassuk, kell valami olyan eszköz,
amivel összekapcsolhatjuk a tárgyiasító tripletek alanyát egy
meghatározott triplettel valamelyik dokumentumban. Az RDF
azonban nem ad ehhez támogatást.
A fenti példákban például nincs olyan explicit információ (sem a
tripletekben, sem az RDF/XML kódban), amely jelezné, hogy az eredeti
kijelentés, amelyik leírja a sátor súlyát, ténylegesen az az
exproducts:triple12345 nevű erőforrás, amelyet a négy
tárgyiasító kijelentésnek, valamint annak az ötödik kijelentésnek az
alanyaként adtunk meg, amely John Smith szerzőségéről szól. Ez rögtön
kiderül, ha ránézünk a 17. ábrán felrajzolt gráfra.
Az eredeti kijelentés természetesen része ennek a gráfnak, de ami a
gráfban szereplő információt illeti, az exproducts:triple12345
egy külön erőforrás, és a gráfnak nem ezt a részét azonosítja. Az
RDF-ben nincs olyan beépített lehetőség, amellyel jelezni lehetne, hogy egy
olyan URIref, mint az exproducts:triple12345 össze van kapcsolva
egy konkrét kijelentéssel vagy gráffal, azon túl, hogy van egy olyan
beépített lehetősége, amellyel jelezni tudjuk, hogy egy olyan URIref, mint az
exproducts:item10245 miként kapcsolódik egy tényleges sátorhoz.
Ez azt jelenti, hogy egy meghatározott URIref-nek valamilyen specifikus
erőforráshoz (esetünkben egy kijelentéshez) való kapcsolását valamilyen
RDF-en kívüli mechanizmussal kell megoldani.
Az rdf:ID-nek a 20. példában
bemutatott használata automatikusan generálja a tárgyiasítást, és megfelelő
lehetőséget nyújt arra is, hogy megnevezzük azt az URI hivatkozást, amelyet a
tárgyiasító kijelentések alanyaként kívánunk használni. Sőt ez még egyfajta
"csáklyát" is jelent, ami összekapcsolja a tárgyiasító tripleteket azzal az
RDF/XML kódrésszel, amelyik ezeket a tripleteket generálja, minthogy az
rdf:ID attribútum triple12345 értékéből áll elő az
az URIref is, amely a tárgyiasító tripletek alanyát azonosítja. Ismételten
hangsúlyozzuk azonban, hogy ez a viszony szintén csak az RDF-en kívül
létezik, mivel semmi nincs a generált tripletekben, ami explicit módon
kimondaná, hogy az eredeti triplet URI hivatkozása az
exproducts:triple12345. (Az RDF ugyanis nem feltételezi, hogy
valamilyen viszony van egy URIref és egy olyan RDF/XML kódrész között,
amelyben ezt – akár teljes hosszban, akár rövidített formában –
használják.)
Egy olyan beépített eszköz hiánya, amellyel URI hivatkozásokat
tripletekhez (kijelentésekhez) lehet asszociálni, nem jelenti azt, hogy
efféle "származási" információkat nem lehet kifejezni RDF-ben, hanem csak
azt, hogy ezt nem lehet megtenni pusztán arra a jelentésre alapozva, amelyet
az RDF maga asszociál a tárgyiasító szókészletéhez. Például: ha egy RDF
dokumentumnak (mondjuk, egy weblapnak) van egy URI-je, akkor kijelentéseket
tehetünk arról az erőforrásról, amelyet ez az URI azonosít, majd pedig,
alapozva arra az alkalmazásfüggő, "külső tudásra", hogy miként kell ezeket a
kijelentéseket értelmezni, az alkalmazás értelmezheti pl. úgy, hogy ezek a
kijelentések a dokumentum összes állítására vonatkoznak. Ugyanígy, ha létezne
valamilyen mechanizmus (az RDF-en kívül) arra, hogy URI hivatkozásokat
kapcsoljunk egyedi RDF kijelentésekhez, akkor bizonyára tehetnénk
kijelentéseket ezekről az egyedi kijelentésekről is az őket azonosító URI-k
segítségével. Ilyen esetekben azonban nem lenne feltétlenül szükséges
konvenciószerűen használni a tárgyiasító szókészletet.
Hogy bemutassuk ezt, tekintsük ismét az eredeti kijelentésünket a sátor
súlyáról:
exproducts:item10245 exterms:weight "2.4"^^xsd:decimal .
Ha ennek a kijelentésnek az azonosítása céljából hozzá kapcsolhatnánk
ehhez az exproducts:triple12345 URIref-et, akkor ennek a
kijelentésnek a szerzőségét egyszerű módon John Smith-hez társíthatnánk a
következő kijelentéssel:
exproducts:triple12345 dc:creator exstaff:85740 .
És tehetnénk mindezt anélkül is, hogy használnánk a tárgyiasító
szókészletet (bár annak a leírásához, hogy az
exproducts:triple12345 URIref által azonosított dolog típusa:
"kijelentés" (rdf:type = rdf:Statement), nem lenne
haszontalan a szókészlet alkalmazása).
Emellett, a tárgyiasító szókészletet közvetlenül is használhatnánk, a
fentebb definiált konvenciónak megfelelően, azzal az alkalmazásfüggő tudással
kombinálva, hogy miként kell egyes tripleteket a tárgyiasulásukhoz kapcsolni.
Ilyenkor azonban azok az alkalmazások, amelyek megkapják az ilyen RDF kódot,
nem szükségszerűen rendelkeznek ugyanezzel az alkalmazásfűggő tudással, és
így nem feltétlenül interpretálnák helyesen annak a gráfjait.
Azt is fontos megjegyezni, hogy a tárgyiasítás imént leírt értelmezése nem
azonos az "idézet" fogalmával, amelyet egyes számítógép-nyelvekben
használnak. A tárgyiasítás ugyanis egy viszonyt ír le egy konkrét triplet és
azon erőforrások között, amelyekre a triplet hivatkozik. Tehát intuitív
módon, valahogy így kellene olvasnunk a tárgyiasítást: "ez az RDF
triplet ezekről a dolgokról szól", és nem úgy, ahogy az idézet
teszi: "ennek az RDF tripletnek ez a formája". Így tehát az alábbi
tárgyiasítási példa:
exproducts:triple12345 rdf:subject exproducts:item10245 .
amelyet már használtunk ebben a szekcióban, és amelyik az eredeti
kijelentés alanyát írja le, azt mondja ki (az rdf:subject
tulajdonság révén), hogy a kijelentés alanya az az erőforrás (a sátor),
amelyet az exproducts:item10245 URIref azonosít. Nem
azt mondja tehát, hogy a kijelentés alanya maga az URIref (azaz egy
olyan karakterlánc, amelyik bizonyos karakterekből áll), ahogyan ezt az
"idézet" teszi.
A 2.3 szekcióban már szó volt arról,
hogy az RDF modell csak bináris relációkat képes leírni a beépített
lehetőségeivel; azaz, egy kijelentés csak két erőforrás között állapíthat meg
valamilyen viszonyt. Például az alábbi kijelentés:
exstaff:85740 exterms:manager exstaff:62345 .
azt mondja, hogy az "igazgatója" (exterms:manager) viszony
áll fenn két alkalmazott között (feltehetően az egyik igazgatja a
másikat).
Bizonyos esetekben azonban olyan információkat kell ábrázolnunk,
amelyekben kettőnél több erőforrás között kell a viszonyokat leírnunk,
vagyis, kettőnél több ágú (azaz magasabb "aritású") relációkat kell kezelnünk
RDF-ben. A 2.3. szekció már bemutatott
erre egy példát, ahol az volt a probléma, hogy ábrázolnunk kell a viszonyt
John Smith és a lakáscíme között, és ahol John címe egy strukturált érték
volt, mely utcanévből, városnévből, az állam nevéből és az irányítószámból
állt. Ha ezt az információt reláció formájában akarjuk leírni, akkor
láthatjuk, hogy itt már egy n-áris (több ágú, angolul:
n-ary) relációról van szó, ahol n=5:
address(exstaff:85740, "1501 Grant Avenue",
"Bedford", "Massachusetts", "01730")
A 2.3 szekcióban már megjegyeztük,
hogy az ilyen jellegű strukturált információt úgy ábrázoljuk RDF-ben, hogy
ezt az összetett dolgot (azaz John címét) egy önálló erőforrásnak tekintve
írjuk le úgy, hogy több külön kijelentést teszünk erről az új erőforrásról,
ahogy az alábbi tripletek mutatják:
exstaff:85740 exterms:address _:johnaddress .
_:johnaddress exterms:street "1501 Grant Avenue" .
_:johnaddress exterms:city "Bedford" .
_:johnaddress exterms:state "Massachusetts" .
_:johnaddress exterms:postalCode "01730" .
(Itt _:johnaddress egy ürescsomópont-azonosító, mely John
címét reprezentálja.)
Az RDF-ben bármilyen n-áris reláció ábrázolásának ez a szokásos
módja: válaszd a résztvevők egyikét az eredeti bináris reláció (esetünkben az
address) alanyának (esetünkben ez John), majd specifikálj egy
közbülső (akár üres, akár URI-vel azonosított) erőforrást (esetünkben ez
_:johnaddress), mely az eredeti bináris reláció tárgyaként, s egyszersmind
egy sor újabb bináris reláció alanyaként is funkcionál, amelyek az
n-áris reláció további komponenseit (esetünkben a cím elemeit)
ábrázolják a tulajdonságok és értékeik megadásával.
John címe esetében a strukturált érték egyetlen egyedi részét sem
tekintjük a cím (exterms:address) tulajdonság "fő" értékének;
minden rész azonos mértékben járul hozzá az összetett érték kialakításához.
Egyes esetekben azonban a strukturált érték összetevőinek egyikét "fő"
értéknek kell tekintenünk, míg a többi összetevők kiegészítő jellegű
kontextuális, vagy egyéb információt szállítanak, amelyek minősítik a fő
értéket. Például a 3.2 szekció által bemutatott
9. példában egy meghatározott sátortípus súlyaként a
2.4 decimális értéket adtuk meg tipizált literál segítségével:
exproduct:item10245 exterms:weight "2.4"^^xsd:decimal .
Valójában, a súly kielégítő leírása 2.4 kilogramm volna, hiszen a
2.4 szám a mértékegység nélkül nem pontosan specifikálja a súlyt.
Hogy ezt is megadhassuk, az exterms:weight (súly) tulajdonságnak
két komponensből kellene állnia: a decimális érték tipizált literáljából,
valamint a mértékegység (kilogramm) jelzéséből. Ilyen esetben a decimális
értéket az exterms:weight tulajdonság "fő" értékének kell
tekintenünk, hiszen ezt az értéket legtöbbször egyetlen tipizált literállal
adják meg (mint a fenti tripletben is), és rábízzák az ezeket használó
programokra, vagy felhasználókra, hogy a hiányzó mértékegységet a kontextus
alapján "derítsék ki".
Az RDF modellben az efféle minősített tulajdonságértéket egyszerűen egy
másfajta strukturált értéknek tekintjük. Hogy ezt ábrázolhassuk, egy külön
erőforrást használunk a strukturált értéknek mint egésznek az ábrázolására,
mely az eredeti kijelentés (exterms:weight) tárgyaként jelenik
meg. Ehhez az erőforráshoz azután olyan tulajdonságokat rendelünk, amelyek a
strukturált érték részeit ábrázolják. Esetünkben kell egy tulajdonság a
decimális értéket reprezentáló tipizált literál megadására, és kell egy másik
tulajdonság a mértékegység leírására. Az RDF-ben van egy előre definiált
tulajdonság, az rdf:value, amelyik a strukturált adat fő
értékének leírására szolgál (ha van ilyen). Így tehát, esetünkben, a súlyt
ábrázoló tipizált literált az rdf:value értékeként adhatjuk meg,
míg a súlyegységet (exunits:kilograms) a mértékegység
(exterms:units) tulajdonság értékeként (feltéve persze, hogy az
itt említett három kifejezést már definiálták az example.org saját
szókészletében). Ha ezek a feltételek fennállnak, akkor az eredményül kapott
tripletek az alábbiak lesznek:
exproduct:item10245 exterms:weight _:weight10245 .
_:weight10245 rdf:value "2.4"^^xsd:decimal .
_:weight10245 exterms:units exunits:kilograms .
Ugyanezt az RDF/XML használatával a 21. példában
leírt módon fejezhetjük ki:
<?xml version="1.0"?>
<!DOCTYPE rdf:RDF [<!ENTITY xsd "http://www.w3.org/2001/XMLSchema#">]>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:exterms="http://www.example.org/terms/">
<rdf:Description rdf:about="http://www.example.com/2002/04/products#item10245">
<exterms:weight rdf:parseType="Resource">
<rdf:value rdf:datatype="&xsd;decimal">2.4</rdf:value>
<exterms:units rdf:resource="http://www.example.org/units/kilograms"/>
</exterms:weight>
</rdf:Description>
</rdf:RDF>
A 21. példa illusztrálja a 4.2. szekcióban ismertetett
rdf:parseType attribútumnak egy újabb alkalmazását, ahol az
értéke ezúttal nem "Collection", hanem "Resource". Az
rdf:parseType="Resource" típusú attribútumot annak jelzésére
használjuk, hogy az ilyen attribútumú elem tartalmának elemzésekor (parsing)
azt egy új erőforrás (Resource) leírásának (egy üres csomópontnak) kell
értelmezni anélkül, hogy megadnánk egy beágyazott
rdf:Description elemet. Esetünkben az
exterms:weight tulajdonság-elemben használt
rdf:parseType="Resource" attribútum azt jelzi, hogy egy üres
csomópontot kell kreálni az exterms:weight tulajdonság
értékeként, és hogy a két közrefogott elem (az rdf:value és az
exterms:units) ezt az üres csomópontot írja le. (Az [RDF-SZINTAXIS] dokumentumban további részletek
találhatók az rdf:parseType="Resource" attribútumról.)
Ugyanezt a módszert használjuk akkor is, ha bármilyen más mértékegységben
megadott mennyiséget ábrázolunk, és akkor is, ha az ábrázolandó értékeket
különböző osztályozó vagy minősítő rendszerekből vesszük: minden esetben az
rdf:value tulajdonsággal adjuk meg a fő értéket, a további
tulajdonságokkal pedig egyéb olyan információkat adunk meg, amelyek
szükségesek a fő érték pontos értelmezéséhez (pl. ezekkel azonosíthatjuk az
osztályozó/minősítő sémát).
Nem kötelező azonban az rdf:value tulajdonságot használni
erre a célra; pl. egy olyan, felhasználó által definiált tulajdonságnevet is
használhattunk volna a 21. példában, mint
exterms:amount, az rdf:value helyett, hiszen az RDF
nem társít semmilyen speciális jelentést ehhez a névhez. Ez csupán egy
kényelmi eszköz egy gyakran előforduló leírási szituáció megoldására.
Tény, hogy ma még, a különböző adatbázisokban, a weben (sőt még a későbbi
példáinkban is) többnyire a legegyszerűbb formában vannak megadva az olyan
tulajdonságok értékei, mint a súly, a fogyasztói ár stb. Mégis hangsúlyoznunk
kell azt az alapelvet, hogy az értékek ilyen egyszerűsített megadása gyakran
nem elegendő ahhoz, hogy pontosan leírják a tulajdonságot. Egy olyan globális
környezetben, mint a Web, általában nem biztonságos azzal a feltételezéssel
élni, hogy aki elolvassa egy tulajdonság értékét, az feltétlenül érti is,
hogy milyen egységben van az megadva, vagy hogy ismeri azokat a
környezetfüggő információkat, amelyek az adat helyes értelmezéséhez
szükségesek. Például az Egyesült Államokban egy webhely megadhat egy
súlyértéket Fontban, ám egy más országbeli szörföző könnyen azt hiheti, hogy
ez a súly Kilogrammban van megadva. A weben található adatok korrekt
értelmezése tehát azt igényli, hogy az adatokkal együtt explicit módon
megadjuk azok interpretációs adatait is (legalább a mértékegységüket). Ezt
sokféle módon meg lehet valósítani: pl. az rdf:value
mechanizmusának fentebb ismertetett használatával, a mértékegységnek a
tulajdonság nevébe történő beépítésével (pl.
exterms:weightInKg), specializált adattípusok definiálásával,
amelyek mértékegység-információt is tartalmaznak (pl.
extypes:kilograms), vagy éppen a felhasználó által definiált,
olyan tulajdonságok megadásával, amelyekkel specifikálhatók az aktuálisan
használt mértékegységek (pl. exterms:unitOfWeight). És az ilyen
információközlést célszerű alkalmazni mind az egyes termékek leírásában, mind
a nagyobb adathalmazok leírásában (mint pl. katalógus-adatok, vagy egy adott
webhely adatai), mind pedig a sémákban (amelyekről az 5.
fejezetben még szólunk).
Néha egy tulajdonság értékeként XML kód egy darabját, vagy olyan szöveget
kell megadnunk, amelyben XML jelölések is szerepelnek. Például egy kiadó
szeretne publikálni olyan RDF meta-adatokat, amelyek könyvek vagy cikkek
címeit tartalmazzák. Jóllehet, az ilyen címek többnyire egyszerű
karakterláncok, de nem mindig ilyen egyszerű a helyzet. Például a matematikai
szakkönyvek címei tartalmazhatnak matematikai formulákat is, amelyek MathML
[MATHML] nyelven íródtak, de a címek
tartalmazhatnak XML jelöléseket egyéb okokból is. Ilyen például a Ruby
annotálás (a japán és kínai írás kiejtési jeleinek feltüntetése az írás
fölötti sorban, az íráshoz képest fele akkora fontméretben) [RUBY]. Vagy ilyenek lehetnek a szöveg olvasási irányát,
esetleg a speciális betűképek variánsait azonosító XML jelölések (lásd pl. [CHARMOD]).
Az RDF/XML speciális elemeket biztosít, amelyek megkönnyítik az ilyen
típusú literálok írását. Ilyen pl. az rdf:parseType attribútum
harmadik változata. Ha egy elemnek az rdf:parseType="Literal"
attribútumot megadjuk, ez azt jelzi, hogy az elem tartalmát XML
kódrészletként kell interpretálni. A 22. példa
illusztrálja ennek az alkalmazását:
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xml:base="http://www.example.com/books">
<rdf:Description rdf:ID="book12345">
<dc:title rdf:parseType="Literal">
<span xml:lang="en">
The <em><br /></em> Element Considered Harmful.
</span>
</dc:title>
</rdf:Description>
</rdf:RDF>
A 22. példában bemutatott RDF/XML kód egy olyan
gráfot ír le, mely egyetlen tripletet tartalmaz: ennek az alanya egy bizonyos
könyv, amelynek azonosítója: ex:book12345, az állítmánya pedig
az, hogy "címe" (dc:title). Az
rdf:parseType="Literal" attribútum pedig azt jelzi, hogy a
<dc:title> elem tartalma egy XML kódrész, mely
(esetünkben) a triplet tárgyaként a könyv címét ábrázolja. A gráfban ez a cím
egy olyan tipizált literálként jelenik meg, amelynek az adattípusa
rdf:XMLLiteral. (Ezt az [RDF-FOGALMAK] dokumentum definiálja,
kifejezetten XML kódrészek ábrázolása céljára, beleértve ebbe az olyan
szövegek ábrázolását is, amelyek esetleg nem tartalmaznak XML jelöléseket).
Az XML kódrészletnek "hitelesnek" kell lennie az XML Exkluzív hitelesítési
ajánlása (az "XML Exclusive Canonicalization Recommendation", [XML-XC14N]) szerint. Ez azt jelenti, hogy a
kódrészletben meg kell adni a használt névterek deklarációit, a speciális
karakterek uniformizált átugratását, és az egyéb transzformációkat. (Részben
emiatt, részben pedig abból a meggondolásból, hogy a tripletek írása is még
további transzformációkat igényel, a tényleges tipizált literált itt nem
mutatjuk meg. Lévén, hogy az RDF/XML tartalmazza az
rdf:parseType="Literal" attribútumot, az RDF felhasználóknak
nem kell közvetlenül foglalkozniuk ezekkel a transzformációkkal.
Azok, akiket érdekelnek az ezzel kapcsolatos részletek, felkereshetik az [RDF-FOGALMAK] és az [RDF-SZINTAXIS] dokumentumokat.) Az olyan
kontextuális attribútumok, mint az xml:lang és az
xml:base szintén nem automatikusan öröklődnek át az RDF/XML
dokumentumból, ezért ha szükséges, explicit módon specifikálni kell ezeket az
XML-literálként megadott kódrészletben is.
Ez a példa is jól mutatta, hogy nagy figyelemre van szükség az RDF adatok
tervezésénél. Első pillantásra úgy tűnik, hogy a címek egyszerű
karakterláncok, amelyeket típus nélküli literálokkal lehet a legjobban
ábrázolni, és csak később vesszük észre, hogy néhány cím adott esetben
jelöléseket is tartalmazhat. Olyan esetekben tehát, amikor egy bizonyos
tulajdonság értéke várhatólag olyan, hogy egyik esetben tartalmaz XML
jelöléseket, a másikban meg nem, akkor vagy úgy járunk el, hogy
következetesen az rdf:parseType="Literal"-t használjuk, vagy
pedig szoftverrel kezeltetjük az alkalmazásainkban az ilyen tulajdonságok
értékeiként megadott típus nélküli literálokat, vagy az
rdf:XMLLiteral-ként megadott kódrészeket.
Az RDF Séma természetesen nem tartalmazza az efféle
alkalmazás-specifikus osztályokat, mint exterms:Tent,
ex2:Book vagy ex3:Person, vagy az ilyen
tulajdonságokat, mint exterms:weightInKg,
ex2:author vagy ex3:JobTitle. Ehelyett olyan
eszközöket és módszereket tartalmaz, amelyek szükségesek az
ilyen osztályok és tulajdonságok definiálásához, valamint annak jelzéséhez,
hogy mely osztályokat és tulajdonságokat kívánunk együtt használni. (Ez
utóbbira példa annak jelzése, hogy az ex3:jobTitle tulajdonságot
csakis az ex3:Person osztály egyedeinek a leírásához kívánjuk
használni). Más szóval, az RDF Séma egy "típus-rendszert" nyújt az RDF
számára. Az RDF Séma típus-rendszere néhány szempontból hasonlít az olyan
objektumortientált programozási nyelvek típus-rendszeréhez, mint pl. a Java.
Az RDF Séma lehetővé teszi, például, hogy az erőforrásokat egy vagy több
osztály egyedeként definiáljuk, sőt azt is lehetővé teszi, hogy az
osztályokat hierarchiákba szervezzük. Így például egy olyan osztályt, mint a
Kutya, pl. az Emlős osztály alosztályaként definiálhatunk, ami viszont az
Állat osztály alosztálya lehet. Ezzel lényegében azt jelentjük ki, hogy egy
erőforrás, amelyik a Kutya osztályban szerepel, implicite az Állat osztálynak
is tagja. Az RDF osztályok és tulajdonságok azonban néhány szempontból
jelentősen különböznek a programnyelvekben használatos "típusoktól". Az RDF
osztályok és tulajdonságok ugyanis nem jelentenek valamiféle
kényszerzubbonyt, amelybe bele kell erőltetni az információt; ezek inkább
olyan mechanizmusok, amelyek további információkat nyújtanak az általuk leírt
RDF osztályokról. Ez az információ sokféleképpen felhasználható, amint arról
részletesebben szólunk majd az 5.3
szekcióban.
Az RDF Séma eszköztára maga is egy RDF szókészlet
formájában áll a rendelkezésünkre; vagyis olyan, előre definiált RDF
erőforrások specializált halmazának formájában, amelyeknek sajátos jelentésük
van. Az RDF Séma szókészletében szereplő erőforrások URI hivatkozásai mind a
http://www.w3.org/2000/01/rdf-schema# prefixszel érhetők el
(amelyet konvencionálisan az rdfs: minősítettnév-prefixhez
asszociál az RDF). Az RDF Séma nyelven megírt szókészletek (más néven: sémák)
legális RDF gráfok. Ebből következik, hogy egy RDF szoftver, amelyet nem úgy
írtak meg, hogy az RDF Séma szókészletét is fel tudja dolgozni, ennek
ellenére is képes egy sémát legális gráfként értelmezni, csakhogy ez nem
fogja "érteni" az RDF Séma kifejezéseinek beépített többletjelentését. Ahhoz,
hogy megérthesse ezt, úgy kell megírni az RDF információt feldolgozó
szoftvert, hogy az a kiterjesztett RDF-et dolgozza fel, amely nemcsak az
rdf: szókészletből áll, hanem magában foglalja az
rdfs: szókészletet is, annak beépített jelentésével együtt. Ezt
a témát járjuk körül a következő szekciókban.
Az alább következő szekciók az RDF Séma alapvető erőforrásait és
tulajdonságait ismertetik.
Bármilyen leírási folyamatban az egyik alapvető lépés a leírandó dolgok
különböző fajtáinak azonosítása. Az RDF Séma a "dolgok fajtáit"
osztályoknak nevezi. Az RDF Sémában az osztály fogalma nagyjából
megfelel a típus vagy a kategória általános fogalmának, és
némileg hasonlít az olyan objektumorientált nyelvek osztályfogalmához, mint a
Java. Az RDF osztályai a dolgok csaknem minden kategóriájának az ábrázolására
alkalmasak, legyenek azok pl. weblapok, emberek, dokumentumtípusok,
adatbázisok, vagy akár elvont fogalmak. Az osztályokat az
rdfs:Class és az rdfs:Resource nevű RDF Séma
erőforrások, valamint az rdf:type és az
rdfs:subClassOf nevű tulajdonságok segítségével írhatjuk le.
Tételezzük fel, például, hogy egy szervezet, az example.org, arra szeretné
használni az RDF-et, hogy információkat nyújtson különféle gépjárművekről.
Ennek a cégnek a saját RDF sémájában (privát szókészletében) először is
szüksége lesz egy olyan osztályra, amelyik a Gépjármű kategóriát képviseli.
Azokat az erőforrásokat, amelyek valamilyen osztályhoz tartoznak, az osztály
példányainak (instance) vagy egyedeinek (individual) nevezzük. Esetünkben az
example.org cég ennek az osztálynak az egyedei alatt olyan erőforrásokat ért,
amelyek mind gépjárművek.
Az RDF Sémában osztálynak tekintünk minden olyan erőforrást,
amelyiknek a leírásában szerepel egy olyan rdf:type tulajdonság,
amelynek az értéke az Osztály nevű erőforrás (rdfs:Class). Így
tehát a gépjármű (motor vehicle) osztályt úgy írhatjuk le, hogy nevet adunk
neki (pontosabban: hozzá rendelünk egy URI hivatkozást), mondjuk, az
ex:MotorVehicle minősített nevet (ahol ex: a
http://www.example.org/schemas/vehicles URI hivatkozás
rövidítése, amely prefixként az example.org szókészletét azonosítja), majd
pedig kijelentjük az így azonosított erőforrásról, hogy annak típusa
(rdf:type) = Osztály (rdfs:Class). Az example.org
tehát a következő RDF kijelentéssel definiálhatná ezt az új osztályt:
ex:MotorVehicle rdf:type rdfs:Class .
Mint már jeleztük a 3.2 szekcióban, az
rdf:type tulajdonságot annak kijelentésére használjuk, hogy a
vele jellemzett erőforrás valamely osztálynak az egyede. Így, ha az
ex:MotorVehicle erőforrást már osztályként definiáltuk, akkor pl
a "cégautó" (exthings:companyCar) nevű egyedi erőforrást RDF-ben
így deklarálhatnánk gépjárműnek:
exthings:companyCar rdf:type ex:MotorVehicle .
(Ez a kijelentés használja azt az általános konvenciót, hogy az
osztályneveket nagy kezdőbetűvel írjuk, a tulajdonságok és az egyedek nevét
pedig kicsivel. Ennek a konvenciónak a betartását azonban sem az RDF, sem az
RDF Séma nem várja el, és nem is ellenőrzi. A fenti kijelentés prefixei azt
is elárulják, hogy az example.org úgy döntött, hogy külön-külön szókészletben
definiálja az osztályokat és az egyedeket.)
Magának az rdfs:Class erőforrásnak a típusa szintén
rdfs:Class. Egy erőforrás több osztálynak is lehet az egyede.
Az example.org, miután leírta az ex:MotorVehicle osztályt,
definiálhat további osztályokat is, amelyek a gépjárművek különféle speciális
csoportjait képviselik, mint pl. Személygépkocsi (Passanger Vehicle),
Tehergépkocsi (Truck), Van, Mini-Van stb. Ezeket az osztályokat is ugyanúgy
írja le, mint fentebb a Gépjármű osztályt (ex:MotorVehicle),
vagyis mindegyiknek egy nevet (URI hivatkozást) ad, és egy-egy kijelentéssel
osztálynak deklarálja őket, a következőképpen:
ex:Van rdf:type rdfs:Class .
ex:Truck rdf:type rdfs:Class .
és így tovább. De ezek a kijelentések, önmagukban, csak az egyes
osztályokat írják le. Az example.org cég azonban jelölni akarja ezeknek a
viszonyát a Gépjármű (ex:MotorVehicle) osztályhoz, mondván, hogy
ezek nem egyebek, mint a Gépjármű specializált fajtái.
Az ilyen specializációs viszonyt, két osztály között, a beépített
rdfs:subClassOf (alosztálya ~nak) tulajdonsággal írjuk le. [A tulajdonságnevek magyar fordításának
olvasásakor a tilde karakter (~) helyére képzeljük a triplet tárgyát. Így a
magyarra fordított tripletekben is fenntarthatjuk a tripletek eredeti
szórendjét – a ford.]. Például, ha az example.org
ki akarja jelenteni, hogy a Van egy speciális fajtája a
Gépjárműnek, akkor az RDF Séma segítségével ezt így írja le:
ex:Van rdfs:subClassOf ex:MotorVehicle .
Ebben a kijelentésben az "alosztálya ~nak" (rdfs:subClassOf)
viszony jelentése az, hogy az ex:Van osztály bármelyik egyede
egyben az ex:MotorVehicle osztálynak is egyede. Így tehát, ha
pl. az exthings:companyVan az ex:Van osztály egyik
egyede, akkor az olyan szoftver, amelyik érti az RDF Séma szókészletét, a
fenti rdfs:subClassOf reláció alapján ki tudja következtetni ebből azt, a mondatban
egyébként explicite nem szereplő információt is, hogy az
exthings:companyVan egy Gépjármű.
Ez az exthings:companyVan példa jól
illusztrálja azt a korábbi megjegyzésünket, hogy az RDF Séma az RDF
szemantikai kiterjesztését definiálja. Az RDF, maga, ugyanis nem definiálja
az RDF Séma szókészletéből való ilyen kifejezések speciális jelentését, mint
pl. az rdfs:subClassOf. Így, ha a cég RDF sémája definiálná az
rdfs:subClassOf viszonyt az ex:Van és az
ex:MotorVehicle között, akkor az olyan RDF szoftver, amelyik nem
érti az RDF Séma kifejezéseit, felismerné ugyan, hogy ez egy triplet,
amelynek az állítmánya rdfs:subClassOf, de nem értené ennek a
speciális "mondanivalóját", és így nem is tudná "kitermelni" a mondatból azt
a plusz információt, hogy az exthings:companyVan szintén egy
gépjármű (lévén az ex:MotorVehicle osztály egyede).
Az rdfs:subClassOf tulajdonság tranzitív. Ez azt
jelenti, hogy, ha például adott az alábbi két RDF kijelentés:
ex:Van rdfs:subClassOf ex:MotorVehicle .
ex:MiniVan rdfs:subClassOf ex:Van .
akkor az RDF Séma a tranzitivitás elve alapján, implicit
módon, ezt a tripletet is definiálta: ex:MiniVan rdfs:subClassOf
ex:MotorVehicle. A tranzivitás jelentése alapján tehát az RDF
Sémát ismerő alkalmazás "rájöhet" arra, hogy azok az erőforrások, amelyek az
ex:MiniVan osztály egyedei, nemcsak az ex:Van
osztálynak, de az ex:MotorVehicle osztálynak is egyedei. Egy
osztály egyszerre több osztálynak is lehet alosztálya (pl. a MiniVan osztály
egyszerre lehet alosztálya a Van osztálynak és a Személygépkocsi osztálynak
is). Az RDF Séma minden osztályt eleve az Erőforrás
(rdfs:Resource) osztály alosztályaként értelmez (minthogy az
összes osztály egyedei erőforrások).
A 18. ábra a teljes osztályhierarchiát mutatja,
amelyet a fenti példákban tárgyaltunk:
(Hogy egyszerűsítsük az ábrát, az rdf:type tulajdonságokat,
amelyek minden osztályt az rdfs:Class osztályhoz kapcsoltak,
kihagytuk a 18. ábrából. Valójában az RDF Séma minden
olyan erőforrást, amelyik megjelenik az rdfs:subClassOf
tulajdonság alanyaként vagy tárgyaként, eleve rdfs:Class típusú
erőforrásnak tekint, ez tehát külön definíció nélkül is kikövetkeztethető.
Amikor azonban valódi sémákat írunk, a helyes gyakorlat az, hogy mégis
explicit módon megadjuk ezt az információt.)
A 18. ábrán látható séma tripletekkel is
leírható:
ex:MotorVehicle rdf:type rdfs:Class .
ex:PassengerVehicle rdf:type rdfs:Class .
ex:Van rdf:type rdfs:Class .
ex:Truck rdf:type rdfs:Class .
ex:MiniVan rdf:type rdfs:Class .
ex:PassengerVehicle rdfs:subClassOf ex:MotorVehicle .
ex:Van rdfs:subClassOf ex:MotorVehicle .
ex:Truck rdfs:subClassOf ex:MotorVehicle .
ex:MiniVan rdfs:subClassOf ex:Van .
ex:MiniVan rdfs:subClassOf ex:PassengerVehicle .
A 23. példa azt mutatja, hogyan írnánk le
ugyanezt a sémát RDF/XML-ben:
<?xml version="1.0"?>
<!DOCTYPE rdf:RDF [<!ENTITY xsd "http://www.w3.org/2001/XMLSchema#">]>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
xml:base="http://example.org/schemas/vehicles">
<rdf:Description rdf:ID="MotorVehicle">
<rdf:type rdf:resource="http://www.w3.org/2000/01/rdf-schema#Class"/>
</rdf:Description>
<rdf:Description rdf:ID="PassengerVehicle">
<rdf:type rdf:resource="http://www.w3.org/2000/01/rdf-schema#Class"/>
<rdfs:subClassOf rdf:resource="#MotorVehicle"/>
</rdf:Description>
<rdf:Description rdf:ID="Truck">
<rdf:type rdf:resource="http://www.w3.org/2000/01/rdf-schema#Class"/>
<rdfs:subClassOf rdf:resource="#MotorVehicle"/>
</rdf:Description>
<rdf:Description rdf:ID="Van">
<rdf:type rdf:resource="http://www.w3.org/2000/01/rdf-schema#Class"/>
<rdfs:subClassOf rdf:resource="#MotorVehicle"/>
</rdf:Description>
<rdf:Description rdf:ID="MiniVan">
<rdf:type rdf:resource="http://www.w3.org/2000/01/rdf-schema#Class"/>
<rdfs:subClassOf rdf:resource="#Van"/>
<rdfs:subClassOf rdf:resource="#PassengerVehicle"/>
</rdf:Description>
</rdf:RDF>
Ahogyan azt már a 3.2 szekcióban, a 13. példával kapcsolatban is tárgyaltuk, az RDF
lehetővé tesz egy rövidítést az olyan erőforrások leírásánál, amelyeknek van
egy rdf:type tulajdonságuk (vagyis, amelyek tipizált
csomópontok). Minthogy az RDF Séma osztályai RDF erőforrások, ez a rövidítési
módszer alkalmazható az osztályok leírásánál is. Ennek a rövidítésnek az
alkalmazásával a fenti séma úgy is leírható, ahogyan azt a 24. példa mutatja:
<?xml version="1.0"?>
<!DOCTYPE rdf:RDF [<!ENTITY xsd "http://www.w3.org/2001/XMLSchema#">]>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
xml:base="http://example.org/schemas/vehicles">
<rdfs:Class rdf:ID="MotorVehicle"/>
<rdfs:Class rdf:ID="PassengerVehicle">
<rdfs:subClassOf rdf:resource="#MotorVehicle"/>
</rdfs:Class>
<rdfs:Class rdf:ID="Truck">
<rdfs:subClassOf rdf:resource="#MotorVehicle"/>
</rdfs:Class>
<rdfs:Class rdf:ID="Van">
<rdfs:subClassOf rdf:resource="#MotorVehicle"/>
</rdfs:Class>
<rdfs:Class rdf:ID="MiniVan">
<rdfs:subClassOf rdf:resource="#Van"/>
<rdfs:subClassOf rdf:resource="#PassengerVehicle"/>
</rdfs:Class>
</rdf:RDF>
Ehhez hasonló, tipizált csomópontokon alapuló rövidítéseket használunk
ennek a szekciónak a további részében is.
A 23. és a 24. példában
bemutatott RDF/XML leírás neveket vezet be (mint pl.
MotorVehicle) az erőforrások (osztályok) számára, amelyeket az
rdf:ID segítségével rendel az osztályokhoz, jelezve, hogy ezek a
nevek relatív URI hivatkozások az éppen leírt sémadokumentumon
belül, ahogyan ezt már a 3.2 szekcióban is
láttuk. Az rdf:ID itt kétszeresen is hasznos, mert egyrészt
rövidíti a hivatkozást, és emellett ellenőrzi azt is, hogy a segítségével
megadott név egyedi-e az aktuális bázis-URI-vel azonosított dokumentumon
belül. Ez segít észrevenni, ha véletlenül egynél többször definiálunk egy
osztálynevet az adott RDF sémában. Az ilyen neveken alapuló relatív URI-kkel
azután a sémadokumentumon belül más osztályokból, akárhányszor hivatkozhatunk
ezekre az osztályokra, ahogyan pl. a #MotorVehicle relatív
hivatkozást használtuk néhány osztály definíciójában. Ha az aktuális sémánk
pl. a http://example.org/schemas/vehicles dokumentum lenne,
akkor ennek az osztálynak a teljes URI hivatkozása így nézne ki:
http://example.org/schemas/vehicles#MotorVehicle (ahogy a 18. ábra legfelső erőforrásánál is látható). Mint a 3.2. szekcióban már megjegyeztük: ahhoz, hogy a
sémában szereplő osztályokra történő hivatkozás akkor is konzisztens
maradjon, ha esetleg ugyanezt a sémát valamilyen okból két webhelyen is
hozzáférhetővé kell tenni, vagy ha várható, hogy a részeit elosztva kell
tárolni, akkor a sémát alkotó dokumentumok alkalmazhatnak egy explicit
bázis-URI deklarációt, ami esetünkben
xml:base="http://example.org/schemas/vehicles" lenne. (Az
xml:base használata helyes gyakorlatnak tekinthető, ezért mi is
használtuk ezt mindkét példánkban.)
Ha az example.org cég helyesen akar hivatkozni ezekre az osztályokra az
egyedek RDF-ben történő leírásánál (pl. a fenti gépjármű-osztályokhoz tartozó
egyedi járművek jellemzésénél) abban az esetben is, ha ezeket az osztályokat
előzőleg más dokumentumban definiálta, akkor vagy teljesen kiírt abszolút (az
aktuális bázis URI-n alapuló) URI hivatkozásokat kell használnia, vagy pedig
olyan minősített nevekkel kell az osztályokra hivatkoznia, amelyek egy
megfelelő névtérprefix-deklaráció révén ugyanezt az abszolút URI hivatkozást
eredményezik. A 25. példánkban a "cégautó"
(companyCar) nevű erőforrást a 24. példában
definiált ex:MotorVehicle osztály
egyedének deklaráljuk:
<?xml version="1.0"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:ex="http://example.org/schemas/vehicles#"
xml:base="http://example.org/things">
<ex:MotorVehicle rdf:ID="companyCar"/>
</rdf:RDF>
Vegyük észre, hogy amikor az RDF kiterjeszti az
ex:MotorVehicle minősített nevet, akkor az
xmlns:ex="http://example.org/schemas/vehicles#"
névtér-deklarációt használja, és így az adott osztályra hivatkozó teljes
abszolút URIref a
http://example.org/schemas/vehicles#MotorVehicle lesz, ami
pontosan megfelel a 18. ábra tetején megadott
erőforrásnak. A példában szereplő
xml:base="http://example.org/things" bázis-URI-deklarációt azért
adtuk meg, hogy az rdf:ID="companyCar" attribútumban relatív
formában adhassuk meg az egyed nevét, tekintve, hogy az rdf:ID
(mint attribútum) értéke nem lehet minősített név, és ezért itt nem
használhatnánk pl. az exthings:companyCar nevet egy hozzátartozó
xmlns:exthings névtér-deklarációval.
Amellett, hogy előre definiálni tudják azoknak a dolgoknak az osztályait,
amelyeket majd később jellemezni szeretnének, a felhasználói
közösségeknek szükségük van olyan lehetőségre is, hogy előre definiálhassák
azokat a specifikus tulajdonságokat is, amelyekkel ezeket az
osztályokat jellemezhetik. (Ilyen tulajdonság lehet pl. a Személygépkocsi
osztályban a hátsó ülések előtt, az utasok lábai számára fenntartott terület
nagysága, amelyről rearSeatLegRoom néven még többször lesz szó a
további példáinkban). Az RDF Sémában a tulajdonságokat a Tulajdonság
(rdf:Property) nevű RDF osztály, valamint az "érvényességi kör"
(rdfs:domain) az "értéktartomány" (rdfs:range) és
az "altulajdonsága ~nak" (rdfs:subPropertyOf) nevű RDF Séma
tulajdonságok (más szóval: tulajdonságkorlátozások) használatával írjuk le.
[A tulajdonságnevek magyar
fordításának olvasásakor a tilde karakter (~) helyére képzeljük a triplet
tárgyát. Így a magyarra fordított tripletekben is fenntarthatjuk a tripletek
eredeti szórendjét – a ford.]
Az RDF-ben minden tulajdonságot az rdf:Property osztály
egyedeként írunk le. Így, ha egy olyan új tulajdonságot definiálunk, mint pl.
"kilogrammban mért súly" (exterms:weightInKg), akkor először is
adunk neki egy ilyen nevet (pontosabban: hozzá rendelünk a fogalomhoz egy
ilyen URI hivatkozást), majd pedig egy olyan rdf:type
megadásával, amelynek értéke az rdf:Property osztály,
tulajdonságként definiáljuk ezt az egyedet. A "kilogrammban mért súly" egyedi
tulajdonság pl. az alábbi kijelentéssel definiálható:
exterms:weightInKg rdf:type rdf:Property .
Az RDF Séma egy olyan szókészletet is tartalmaz, amellyel leírhatjuk, hogy
mely tulajdonságokat, mely osztályokkal összefüggésben kívánunk használni az
RDF adatok leírásakor. A legfontosabb ilyen jellegű információt az
"érvényességi köre" (rdfs:domain) illetve az "értéktartománya"
(rdfs:range) RDF Séma tulajdonságokkal adhatjuk meg (ezeket
tulajdonságkorlátozásoknak is nevezzük) .
Az rdfs:range tulajdonságot annak jelzésére használjuk, hogy
egy adott tulajdonság értéke csak a megjelölt osztály valamelyik egyede
lehet. Például, ha az example.org cég azt akarná jelezni, hogy a "szerzője"
(ex:author) tulajdonság csak a Személy (ex:Person)
osztály egyedei közül kerülhet ki, akkor az alábbi RDF kijelentéseket írná
le:
ex:Person rdf:type rdfs:Class .
ex:author rdf:type rdf:Property .
ex:author rdfs:range ex:Person .
Ezek a kijelentések azt mondják, hogy az ex:Person egy
osztály, az ex:author egy tulajdonság, valamint, hogy egy olyan
jövőbeli RDF kijelentés, amelyik majd az ex:author tulajdonságot
használja, ennek értékeként (azaz, a mondat tárgyaként) csak az
ex:Person osztály valamelyik egyedét jelölheti meg.
Egy olyan tulajdonsághoz, mint pl. "anyja" (ex:hasMother),
hozzárendelhetünk zéró, egy, vagy több "értéktartománya"
tulajdonságkorlátozást. Ha nem adunk meg egyet sem, akkor ez azt jelenti,
hogy nem kívánjuk korlátozni az "anyja" tulajdonság lehetséges értékeit. Ha
megadunk egyet, mondjuk az ex:Person osztályt, akkor ezzel azt
deklaráljuk, hogy az ex:hasMother tulajdonság lehetséges értékei
az ex:Person osztály egyedei. Ha több értéktartományt adunk meg
az ex:hasMother tulajdonság számára, mondjuk az
ex:Person osztály mellett még az ex:Female
(NőneműLény) osztályt is, akkor ezzel azt fejezzük ki, hogy az "anyja"
tulajdonság értéke lehet bármi, ami Személy és ugyanakkor NőneműLény
is.
Lehet, hogy ez utóbbi állításunk nem azonnal belátható, hiszen nem lehet
egyetlen rdfs:range tulajdonságnak két különböző értéket adni.
Azonban ez nem is szükséges, minthogy az ex:hasMother alanyra
megadhatunk kettő vagy több "értéktartománya" (rdfs:range)
kijelentést is, különböző értékekkel:
ex:hasMother rdfs:range ex:Female .
ex:hasMother rdfs:range ex:Person .
E deklarációk alapján, az alábbi kijelentésből:
exstaff:frank ex:hasMother exstaff:frances .
amelynek állítmányában az imént definiált ex:hasMother
tulajdonságot használjuk, nemcsak az állapítható meg, hogy "Frank anyja
Frances", hanem az is, hogy Frances személy és nőnemű. (Ha Frances nem lenne
mind az ex:Person, mind
pedig az ex:Female osztály egyedeként
deklarálva, akkor ezt a mondatot az RDF elemző hibásként visszadobná.)
Az rdfs:range értéke nemcsak valamilyen felhasználó által
definiált osztály lehet, hanem egy XML Séma adattípus is, mint pl.
xsd:integer, mely történetesen az egész számok osztályát
reprezentálja. (Az ilyen adattípusokat a 2.4.
szekcióban a tipizált literálok ábrázolásával kapcsolatban már
tárgyaltuk). Ha például az example.org cég azt akarná jelezni, hogy az
"életkora" (ex:age) tulajdonság értéke csakis egész szám (vagyis
az XML Séma adattípus xsd:integer osztályának egyik egyede)
lehet, akkor az ex:age tulajdonságot így definiálná RDF-ben:
ex:age rdf:type rdf:Property .
ex:age rdfs:range xsd:integer .
Az xsd:integer adattípust az URI hivatkozásával azonosítjuk,
amelynek teljes változata:
http://www.w3.org/2001/XMLSchema#integer. Ez az URIref anélkül
használható, hogy explicit módon kijelentenénk a sémában, hogy egy adattípust
reprezentál. Mégis, gyakran hasznos explicit módon kijelenteni, hogy egy
adott URIref valamilyen adattípust azonosít. Ezt az
rdfs:Datatype nevű RDF Séma osztály használatával tehetjük meg.
Ha az example.org ki akarná jelenteni, hogy az xsd:integer egy
adattípus, akkor a következő RDF mondatot írhatná:
xsd:integer rdf:type rdfs:Datatype .
Ez a kijelentés azt mondja, hogy az xsd:integer egy olyan
adattípus URI hivatkozása, amelyről feltételezzük, hogy megfelel az [RDF-FOGALMAK] dokumentumában leírt
követelményeknek. Egy ilyen kijelentés nem jelent adattípus-definíciót (abban
az értelemben, hogy az example.com egy új adattípust definiál). Az RDF
Sémában nincs is lehetőség arra, hogy adattípusokat definiáljunk. Amint a 2.4 szekcióban már jeleztük, az adattípusok
definiálása az RDF-en és az RDF Sémán kívül történik. Az RDF mondatokból csak
hivatkozhatunk ezekre, az URIref-jeik segítségével. A fenti mondat
pusztán csak arra szolgál, hogy dokumentálja az adattípus létezését, és
jelezze, hogy ebben a sémában használni fogjuk azt.
Az "érvényességi köre" (rdfs:domain) RDF Séma tulajdonságot
(más szóval: tulajdonságkorlátozást) annak jelzésére használjuk, hogy egy
adott tulajdonság a megjelölt osztályra vonatkozik (vagyis, csak arra
érvényes). Ha pl. az example.org cég azt szeretné jelezni, hogy a "szerzője"
(ex:author) tulajdonság csak a Könyv (ex:Book)
osztály egyedeire legyen érvényes, akkor a következő RDF kijelentéseket
tenné:
ex:Book rdf:type rdfs:Class .
ex:author rdf:type rdf:Property .
ex:author rdfs:domain ex:Book .
Ezek a mondatok azt jelentik, hogy az ex:Book egy osztály, az
ex:author egy tulajdonság, valamint, hogy az
ex:author tulajdonság alanya csak az ex:Book
osztály valamelyik egyede lehet (vagy másként kifejezve: az
ex:author tulajdonság érvényességi köre az ex:Book
osztály egyedeinek halmaza).
Egy adott tulajdonság, pl. a "súlya" ( exterms:weight),
rendelkezhet zéró, egy, vagy több "érvényességi köre"
(rdfs:domain) tulajdonságkorlátozással. Ha egyetlen ilyent sem
adunk meg, akkor ez azt jelenti, hogy nem akarjuk korlátozni a tulajdonság
érvényességi körét, tehát bármelyik erőforrásnak lehet "súlya" tulajdonsága.
Ha csak egyetlen ilyen korlátozást adunk meg, amelyik pl. a Könyv osztályt
jelöli meg e tulajdonság érvényességi körének, akkor ez a tulajdonság
kizárólag a Könyv osztály egyedeire lesz alkalmazható. Ha azonban több
korlátozást adnánk meg a "súlya" tulajdonságra, amelyek közül az
egyik pl. a Könyv osztályt, a másik pedig a Gépjármű osztályt
nevezné meg érvényességi körnek, akkor ezzel azt jelentenénk ki, hogy bármely
erőforrás, amelynek lehet olyan tulajdonsága, hogy "súlya", az a Gépjármű
osztálynak, és a Könyv osztálynak egyaránt egyede kell hogy
legyen. (Ez utóbbi példa azt is illusztrálja, hogy mennyire óvatosnak kell
lennünk az ilyen többszörös korlátozásokkal.)
Ugyanúgy mint az "értéktartománya" (rdfs:range)
tulajdonságkorlátozás használatánál, itt is elsőre nehéz lehet elképzelni,
miként adhatunk két különböző értéket az rdfs:domain
tulajdonságnak, hogy deklaráljuk a kettős korlátozást. A magyarázat azonban
itt is hasonló: két külön mondatban rendeljük az
exterms:weight tulajdonsághoz a két rdfs:domain
értéket:
exterms:weight rdfs:domain ex:Book .
exterms:weight rdfs:domain ex:MotorVehicle .
Ezt követően minden olyan kijelentés, amelyik az
exterms:weight tulajdonságot használja, mint pl. ez:
exthings:companyCar exterms:weight "2500"^^xsd:integer .
csak akkor lehet korrekt, ha az alanyaként használt erőforrás (esetünkben
az exthings:companyCar) mind az ex:Book osztálynak,
mind az ex:MotorVehicle osztálynak egyede.
Az rdfs:range és az rdfs:domain
tulajdonságkorlátozások leírása jól illusztrálható a "Gépjármű" sémánk olyan
kiterjesztésével, hogy megadunk két gépjármű-tulajdonságot: a "tulajdonosa"
és a "hátsóÜlésElőttiTérNagysága" (a példákban: ex:registeredTo,
illetve ex:rearSeatLegRoom néven), valamint bevezetünk egy új
osztályt "Személy" (ex:Person) néven, és leírjuk, hogy az
xsd:integer-t mint adattípust fogjuk használni ebben a sémában.
A "tulajdonosa" (ex:registeredTo) tulajdonságot úgy definiáljuk,
hogy alanya csak az ex:MotorVehicle osztályból, értéke pedig
csak az ex:Person osztályból származó erőforrás lehessen. Ebben
példában az ex:rearSeatLegRoom tulajdonságot az
ex:PassengerVehicle (Személygépkocsi) osztály egyedeire
korlátozzuk, és ennek értéke egy egész szám (xsd:integer) típusú
adat lesz, mely a "hátsóÜlésElőttiTérNagysága" tulajdonságot centiméterekben
adja meg. Ezek a leírások a 26. példában
láthatók.
<rdf:Property rdf:ID="registeredTo">
<rdfs:domain rdf:resource="#MotorVehicle"/>
<rdfs:range rdf:resource="#Person"/>
</rdf:Property>
<rdf:Property rdf:ID="rearSeatLegRoom">
<rdfs:domain rdf:resource="#PassengerVehicle"/>
<rdfs:range rdf:resource="&xsd;integer"/>
</rdf:Property>
<rdfs:Class rdf:ID="Person"/>
<rdfs:Datatype rdf:about="&xsd;integer"/>
Figyeljük meg, hogy a 26. példában nem használunk
<rdf:RDF> elemet, mert úgy tekintjük ezt a kis kódrészletet, hogy
később beillesztjük a 24. példában szereplő
Gépjármű séma szövegébe. Ugyanilyen alapon használunk relatív URI hivatkozást
a sémában definiált ilyen osztályokra is, mint pl. a Gépjármű
(MotorVehicle).
Az RDF Séma az osztályok mellett a tulajdonságok esetében is lehetővé
teszi a specializációt. A specializációs viszonyt két tulajdonság között az
előre definiált "altulajdonsága ~nak" (rdfs:subPropertyOf) RDF
Séma tulajdonsággal írjuk le. Ha pl. a "segédvezetője"
(ex:secondaryDriver) és a "vezetője" (ex:driver)
egyaránt tulajdonságok, akkor az example.org cég a következőképpen definiálná
ezt a két tulajdonságot és a kettejük közötti specializációs viszonyt (vagyis
azt, hogy a "segédvezetője" tulajdonság a "vezetője" tulajdonság speciális
esete):
ex:driver rdf:type rdf:Property .
ex:secondaryDriver rdf:type rdf:Property .
ex:secondaryDriver rdfs:subPropertyOf ex:driver .
Az rdfs:subPropertyOf viszony következménye itt az, hogy ha
pl. azt mondjuk, hogy az exstaff:fred személy egyed az
ex:companyVan gépjármű egyed "segédvezetője", akkor az RDF Séma
implicit módon azt a kijelentést is generálja, hogy Fred "vezetője" is ennek
a gépjárműnek. Azt az RDF/XML kódot, mely leírja ezeket a tulajdonságokat
(ismét feltételezve, hogy ezt majd beépítjük a 24.
példában látható sémába) a 27. példa mutatja:
<rdf:Property rdf:ID="driver">
<rdfs:domain rdf:resource="#MotorVehicle"/>
</rdf:Property>
<rdf:Property rdf:ID="secondaryDriver">
<rdfs:subPropertyOf rdf:resource="#driver"/>
</rdf:Property>
Egy tulajdonság zéró, egy, vagy több tulajdonságnak is altulajdonsága
lehet. Minden rdfs:range és rdfs:domain
tulajdonságkorlátozás, amelyet valamely tulajdonságra megadunk, érvényes
annak összes altulajdonságára is. Ezen összefüggés révén a fenti példa
(implicit módon) azt is definiálja, hogy az ex:secondaryDriver
tulajdonság érvényességi körébe (rdfs:domain) az
ex:MotorVehicle is beletartozik, hiszen az
ex:secondaryDriver tulajdonság az alosztály-reláció révén örökli
az ex:driver tulajdonság korlátozásait.
A 28. példa mutatja azt az RDF/XML kódot, mely
tartalmazza a Gépjármű sémánkhoz eddig megadott összes leírást:
<?xml version="1.0"?>
<!DOCTYPE rdf:RDF [<!ENTITY xsd "http://www.w3.org/2001/XMLSchema#">]>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
xml:base="http://example.org/schemas/vehicles">
<rdfs:Class rdf:ID="MotorVehicle"/>
<rdfs:Class rdf:ID="PassengerVehicle">
<rdfs:subClassOf rdf:resource="#MotorVehicle"/>
</rdfs:Class>
<rdfs:Class rdf:ID="Truck">
<rdfs:subClassOf rdf:resource="#MotorVehicle"/>
</rdfs:Class>
<rdfs:Class rdf:ID="Van">
<rdfs:subClassOf rdf:resource="#MotorVehicle"/>
</rdfs:Class>
<rdfs:Class rdf:ID="MiniVan">
<rdfs:subClassOf rdf:resource="#Van"/>
<rdfs:subClassOf rdf:resource="#PassengerVehicle"/>
</rdfs:Class>
<rdfs:Class rdf:ID="Person"/>
<rdfs:Datatype rdf:about="&xsd;integer"/>
<rdf:Property rdf:ID="registeredTo">
<rdfs:domain rdf:resource="#MotorVehicle"/>
<rdfs:range rdf:resource="#Person"/>
</rdf:Property>
<rdf:Property rdf:ID="rearSeatLegRoom">
<rdfs:domain rdf:resource="#PassengerVehicle"/>
<rdfs:range rdf:resource="&xsd;integer"/>
</rdf:Property>
<rdf:Property rdf:ID="driver">
<rdfs:domain rdf:resource="#MotorVehicle"/>
</rdf:Property>
<rdf:Property rdf:ID="secondaryDriver">
<rdfs:subPropertyOf rdf:resource="#driver"/>
</rdf:Property>
</rdf:RDF>
Miután láttuk, hogy hogyan írjuk le az osztályokat és tulajdonságokat az
RDF Séma segítségével, most már illusztrálhatjuk azokat az egyedeket is,
amelyek az így definiált osztályokat és tulajdonságokat használják. A 29. példa leírja a 28.
példából ismert Személygépkocsi osztály
(ex:PassengerVehicle) egyik egyedét, néhány tulajdonságával
együtt, amelyeknek itt most csak hipotetikus értékeket adunk.
<?xml version="1.0"?>
<!DOCTYPE rdf:RDF [<!ENTITY xsd "http://www.w3.org/2001/XMLSchema#">]>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:ex="http://example.org/schemas/vehicles#"
xml:base="http://example.org/things">
<ex:PassengerVehicle rdf:ID="johnSmithsCar">
<ex:registeredTo rdf:resource="http://www.example.org/staffid/85740"/>
<ex:rearSeatLegRoom
rdf:datatype="&xsd;integer">127</ex:rearSeatLegRoom>
<ex:secondaryDriver rdf:resource="http://www.example.org/staffid/85740"/>
</ex:PassengerVehicle>
</rdf:RDF>
Ez a példa feltételezi, hogy ezt az egyedet (John Smith autóját) nem
ugyanabban a dokumentumban írjuk le, mint amelyikben a sémát leírtuk.
Minthogy a séma bázis-URI-je
http://example.org/schemas/vehicles, ezért ebben a leírásban az
xmlns:ex="http://example.org/schemas/vehicles#"
névtér-deklarációval teremtjük meg annak a lehetőségét, hogy olyan
ex: prefixszel minősített nevekkel hivatkozhassunk a 28. példa sémájában deklarált osztályokra és
tulajdonságokra (mint pl. az ex:registeredTo), amelyeket korrekt
módon, az ott definiált osztályok és tulajdonságok abszolút URI
hivatkozásaira terjeszt ki az RDF. Az
xml:base="http://example.org/things" deklarációt pedig azért
adtuk meg ebben az kódrészletben, hogy lehetővé tegyük az itt leírt egyed
relatív azonosítójának (rdf:ID="johnSmithsCar") egy olyan URI
hivatkozássá történő kiterjesztését, mely a kívánatos módon, mindig az ebben
a dokumentumban szereplő egyedre mutasson (akkor is, ha netán két példányban,
két különböző webhelyen létezne ugyanez a dokumentum).
Vegyük észre, hogy a "tulajdonosa" (ex:registeredTo)
tulajdonság nyugodtan használható a Személygépkocsi osztálynak erre az
egyedére (johnSmithsCar), mert a 28. példa sémájában
a Személygépkocsi osztályt a Gépjármű osztály alosztályának definiáltuk, s
ezért örökli a Gépjármű osztály tulajdonságkorlátait. Figyeljük meg azt is,
hogy egy tipizált literált használunk az egyed "hátsóÜlésElőttiTérNagysága"
(ex:rearSetLegRoom) tulajdonságának értékeként, ahelyett, hogy
ezt az értéket az
<ex:rearSeatLegRoom>127</ex:rearSeatLegRoom> típus
nélküli literállal adtuk volna meg. Mivel a séma ennek a tulajdonságnak az
értéktartományát xsd:integer-ként definiálta, ezért e
tulajdonság értékeként csakis egy ennek az adattípusnak megfelelő
tipizált literált fogad el az RDF. Egyéb információt is megadhatnánk
(akár a sémában, akár az egyedet leíró dokumentumban) ennek az értéknek a
további pontosítására: pl. az adat mértékegységét (centiméter), ahogyan azt a
4.4.szekcióban már részleteztük.
Mint már korábban megjegyeztük, az RDF Séma típus-rendszere némely
tekintetben hasonlít az olyan objektumorientált programozási nyelvek
típus-rendszerére, mint pl. a Java. Az RDF azonban több lényeges kérdésben
eltér a programozási nyelvek típus-rendszerétől.
Az egyik fontos eltérés, hogy ahelyett, hogy úgy írnánk le egy osztályt,
mint amelyik rendelkezik egy sor tulajdonsággal, az RDF séma a
tulajdonságokat írja le úgy (az érvényességi körük és az értéktartományuk
segítségével), hogy azok az egyedek meghatározott osztályaira vonatkoznak.
Egy tipikus objektumorientált rendszer például definiálna egy Könyv osztályt
egy olyan attribútummal, mint pl. "szerzője", amelynek az értéke Személy
típusú. Az ennek megfelelő RDF séma viszont előbb definiálna egy Könyv
osztályt, majd egy külön leírásban definiálna egy "szerzője" tulajdonságot
úgy, hogy ennek "érvényességi köre" a Könyv osztály, az "értéktartománya"
pedig a Személy osztály lenne.
A két közelítés közötti különbség első pillantásra csak szintaktikai
jellegűnek tűnik, ám valójában jelentős különbségről van szó. Egy
programozási nyelv osztályleírásában a "szerzője" attribútum a Könyv osztály
leírásának a része, és csak a Könyv osztály egyedeire érvényes. Egy
másik osztálynak (mondjuk, a Szoftver Modulnak) szintén lehetne egy
"szerzője" attribútuma, de ezt már különböző attribútumnak
tekintenénk. Más szóval: egy attribútum-leírás szkópja (hatóköre) a legtöbb
programozási nyelvben arra az osztályra korlátozódik, amelyikben definiálták.
Ugyanakkor az RDF-ben a tulajdonságok eleve függetlenek az
osztálydefinícióktól, és a hatókörük alapértelmezésben globális
(szükség esetén azonban meghatározott osztály(ok)ra korlátozhatjuk ezeket az
"érvényességi köre" és az "értéktartománya" RDF Séma tulajdonságok
segítségével.)
Ennek megfelelően egy RDF séma leírhatna egy olyan tulajdonságot, mint pl.
"súly" anélkül, hogy érvényességi kört definiálna a számára. Ezt a
tulajdonságát azután használhatnánk bármelyik osztály egyedének a leírásához,
amelyikről úgy gondoljuk, hogy van súlya. Az RDF tulajdonság alapú
közelítésének egyik előnye az, hogy ezzel könnyebbé válik valamely
tulajdonság használatának a kiterjesztése olyan helyzetekre is, amelyeket nem
lehetett előre látni a tulajdonság eredeti deklarációja idején. Ugyanakkor ez
egy olyan előny, amelyet csak körültekintően szabad kihasználni, hogy
elkerüljük a nem megfelelő esetekre történő alkalmazását.
További következménye az RDF tulajdonságok globális
hatókörének az, hogy egy RDF sémában nem lehet úgy definiálni egy adott
tulajdonságot, hogy helyileg különböző értéktartománya legyen attól függően,
hogy melyik osztályhoz tartozik az egyed, amelyre alkalmazzuk. Például a
"szülője" tulajdonság definiálásánál kívánatos lenne, ha azt tudnánk
deklarálni, hogy amikor ezt az Ember osztályhoz tartozó erőforrás leírására
használjuk, akkor az értéktartománya is az Ember osztály legyen, amikor pedig
egy Tigris osztályú egyed leírására használjuk, akkor az értéktartománya
automatikusan a Tigris osztály legyen. Egy ilyenfajta definíció nem
lehetséges az RDF Sémában. Ehelyett minden értéktartomány, amelyet egy RDF
tulajdonságra megadunk, érvényes a tulajdonság minden egyes használatánál, s
ezért az értéktartományok definiálása óvatosságot igényel. Noha az RDF
Sémában nem lehet ilyen, helyileg különböző értéktartományokat definiálni, ez
megvalósítható a gazdagabb sémanyelvekben, amelyeket az 5.5. szekcióban ismertetünk.
Ugyancsak fontos különbség, hogy az RDF Séma leírásai nem feltétlenül
előírás jellegűek, abban az értelemben, ahogy a programozási nyelvek
típusdeklarációi jellemzően azok. Ha például egy programozási nyelv definiál
egy Könyv osztályt egy "szerzője" attribútummal, amelynek értékei Személy
típusúak, akkor ezeket tipikusan szigorú korlátozásoknak értelmezi.
Ezért az ilyen nyelv nem engedi meg, hogy úgy kreáljuk a Könyv osztály
valamelyik példányát, hogy az ne rendelkezzék a "szerzője" attribútummal, és
azt sem engedi meg, hogy egy ilyen példány "szerzője" attribútumának értéke
ne Személy típusú legyen. Sőt, ha a "szerzője" az egyetlen
attribútum, amelyet ehhez az osztályhoz deklaráltunk, akkor a nyelv azt sem
engedi meg, hogy az osztálynak egy más attribútummal is rendelkező egyedét
kreáljuk.
Az RDF Séma viszont lehetővé teszi, hogy a sémainformációk további
adatokkal pontosítsák az erőforrások leírását, de nem írja elő, hogy ezeket a
leírásokat hogyan kell használnia egy alkalmazásnak. Tegyük fel, például,
hogy egy RDF séma azt definiálja, hogy a "szerzője" tulajdonság
értéktartománya a Személy osztály. Ez az RDF kijelentés nem mond többet, csak
annyit, hogy az olyan RDF állításokban, ahol a "szerzője" tulajdonság az
állítmány, a kijelentés tárgya Személy típusú.
Ezt a sémainformációt különböző módokon lehet felhasználni. Az egyik
alkalmazás értelmezheti a fenti állítást úgy, mint egy olyan RDF adatminta
részét, amelynek megfelelő adatokat az alkalmazásnak elő kell állítania, és
annak biztosítására használja az információt, hogy "szerzője" tulajdonság
értéke mindig a Személy osztályból származzék. Vagyis, ez az alkalmazás a
sémaleírást korlátozásként értelmezi, ahogyan ezt egy programozási
nyelv is tenné. Egy másik RDF alkalmazás azonban interpretálhatja ezt az
állítást úgy is, hogy az plusz információt nyújt arról az adatról amit kap:
olyan információt, mely explicit módon nem szerepel az eredeti adatban. Ez a
második alkalmazás például kaphat egy olyan adatot, amelyben szerepel egy
"szerzője" tulajdonság, amelynek értéke egy ismeretlen osztályhoz tartozó
egyed, és ilyenkor a sémainformáció alapján kikövetkeztetheti, hogy ez a
Személy osztályhoz tartozik. Egy harmadik alkalmazás kaphat egy olyan RDF
adatot, amelyben a "szerzője" tulajdonság tárgya a Testület osztályhoz
tartozik, és ilyenkor arra használja a fenti állítást, hogy annak alapján
kiad egy figyelmeztetést: "Ebben az adatban lehet, hogy inkonzisztencia van,
de lehet, hogy nem". Másutt létezhet esetleg egy olyan további deklaráció,
mely feloldja ezt kétséget azáltal, hogy kikövetkeztethető belőle: a Testület
a szerzőség tekintetében a Személy osztályhoz tartozik (pl. azon az alapon,
hogy a testület jogi személy).
Továbbá, attól függően, hogy miként interpretálja az alkalmazás a
tulajdonságok leírásait, egy egyed leírása érvényesnek tekinthető akár néhány
séma specifikálta tulajdonság nélkül is (pl. létezhet egy Könyv
osztályú egyed "szerzője" tulajdonság nélkül akkor is, ha a "szerzője"
tulajdonságra azt adták meg, hogy az "érvényességi köre" a Könyv osztály), de
érvényesnek tekinthető az egyed leírása akkor is, ha hozzáadott
tulajdonságokkal rendelkezik (létezhet pl. egy Könyv osztályú egyednek egy
"szerkesztője" tulajdonsága akkor is, ha a Könyv osztályt eredetileg leíró
séma még nem adott meg az osztály számára ilyen tulajdonságot).
Más szavakkal összefoglalva: az RDF Séma kijelentései mindig
leírások. Ezek tekinthetők előírás jellegűeknek (azaz
korlátozásoknak), de csak akkor, ha az ezeket értelmező alkalmazás ilyenként
kívánja kezelni őket. Amit az RDF Séma nyújt, az nem más, mint egy lehetőség
arra, hogy megadjuk ezeket a többletinformációkat. Annak megállapítása, hogy
ez az új információ ütközik-e az explicit módon specifikált egyedi adatokkal,
kizárólag az adott alkalmazástól függ (mint ahogy az is, hogy az alkalmazás
miként reagál erre a megállapításra).
Az RDF Séma rendelkezik több más, beépített tulajdonsággal, amelyek
dokumentálják, vagy kommentálják az RDF sémánkat, vagy az abban definiált
egyedeket. Például a "kommentárja" (rdfs:comment) tulajdonság
ember által olvasható módon írhatja le az erőforrást. A "címkéje"
(rdfs:label) tulajdonság egy erőforrás nevének ember által
olvashatóbb változatát adhatja meg. A "lásd továbbá"
(rdfs:seeAlso) tulajdonság utalást jelent egy másik erőforrásra,
mely további információt nyújthat az alanyként megadott erőforrásról. A
"definiálja" (rdfs:isDefinedBy) tulajdonság a "lásd továbbá"
(rdfs:seeAlso) tulajdonság altulajdonsága, és egy olyan
erőforrás megjelölésére használható, amely valamilyen formában definiálja az
alanyként megadott erőforrást. Azért használtuk itt a "valamilyen formában"
kifejezést, mert előfordulhat, hogy az rdfs:isDefinedBy
segítségével megnevezett erőforrás valamilyen RDF által nem specifikált
értelemben definiálja az alanyt (pl. a megadott erőforrás esetleg nem egy RDF
séma). Az RDF Szókészlet Leíró Nyelv
1.0: RDF Séma [RDF-SZÓKÉSZLET]
dokumentum tárgyalja részletesen ezeket a tulajdonságokat.
Miként több beépített RDF tulajdonság
(rdf:value stb.) használati leírása, ugyanúgy az RDF Séma
tulajdonságok használati leírása is csupán ezek szándékolt
használatát adja meg. Az [RDF-SZEMANTIKA]
nem tulajdonít speciális jelentést ezeknek a tulajdonságoknak, és az RDF Séma
sem definiál semmilyen korlátozást ezekre a tulajdonságokra a szándékolt
használat alapján. Semmilyen szabály nem írja elő, például, hogy egy "lásd
továbbá" tulajdonság köteles további információt nyújtani annak a
kijelentésnek az alanyáról, amelyben megjelenik.
Az RDF Séma biztosítja az alapvető eszközöket az RDF szókészletek
leírására, de léteznek további olyan eszközök is, amelyek szintén hasznosak
lehetnek. Ilyen eszközökhöz juthatunk az RDF Séma továbbfejlesztésével, vagy
más olyan nyelvek alkalmazásával, amelyek az RDF-en alapulnak. Azok a
további, gazdagabb sémaleíró lehetőségek, amelyekről tudjuk, hogy hasznosak,
de amelyek nem szerepelnek az RDF Sémában, egyebek között az alábbiak
lehetnek:
- kardinalitáskorlátozások specifikálása a tulajdonságokra, pl.,
hogy egy Személynek kizárólag egy "biológiai apja" lehet (a
kardinalitás egy olyan tulajdonságkorlátozás, amely megadja, hogy egy
adott a tulajdonságnak hány különböző értéke lehet).
- annak specifikálása, hogy egy adott tulajdonság (mint pl. "felmenője")
tranzitív (vagyis, ha A "felmenője" B, és B "felmenője" C, akkor
A "felmenője" C.)
- annak specifikálása, hogy egy adott tulajdonság egy adott osztály
valamelyik egyedének egyedi azonosítója (vagy kulcsa) .
- annak specifikálása, hogy két olyan osztály, amelyik két különböző URI
hivatkozással érhető el, ténylegesen ugyanazt az osztályt
reprezentálja.
- annak specifikálása, hogy két olyan egyed, amelyik két különböző URI
hivatkozással érhető el, ténylegesen ugyanazt az egyedet
reprezentálja.
- egy tulajdonság értéktartományának vagy
kardinalitásának helyi korlátozása arra az osztályra vagy erőforrásra,
vonatkoztatva, amelyikkel kapcsolatban éppen definiáljuk. Erre azért van
szükség, hogy képesek legyünk pl. ilyen korlátokat specifikálni: a
"játékosa" tulajdonság a Futballcsapat erőforrás esetén 11-szer adható
meg, 11 különböző értékkel, amely egy-egy
játékost reprezentál, míg a Kosárlabda-csapat erőforrás esetén ez a szám
csak 5 lehet.
- új osztályok leírása egy vagy több osztály halmazuniójaként vagy
metszeteként, továbbá annak kijelentése, hogy két osztály diszjunkt (más
szóval két idegen osztály, mert nincsenek közös egyedeik).
Az itt említett fejlettebb képességeket, sok más hasznos képességgel
együtt, az olyan ontológianyelvek célozzák meg, mint a DAML+OIL [DAML+OIL] és az OWL [OWL].
E két nyelv mindegyike az RDF-en és az RDF Sémán alapszik (és jelenleg
mindegyik tartalmazza a fentebb leírt plusz képességeket). Az
ontológianyelvek célja, hogy további, géppel feldolgozható
szemantikai információt kapcsoljanak az erőforrásokhoz, és ezáltal
az erőforrások gépi ábrázolását jobban közelítsék azok való világbeli
megfelelőihez. Noha az ilyen képességek nem feltétlenül szükségesek ahhoz,
hogy hasznos alkalmazásokat készítsünk RDF-ben (a 6.
fejezet bemutat egy sor létező RDF alkalmazást), mégis, az ilyen nyelvek
fejlesztése nagyon aktív munkaterület a Szemantikus Web
fejlesztésében.
Az erőforrások felfedezése: Ez egy általános kifejezés a
tartalom megtalálásának folyamatára, mely magában foglalja a keresést, a
böngészést, a tartalom irányítását és más technikákat is. Amikor a felfedezés
kérdése kerül szóba, elsősorban a nyilvános webhelyeknek a fogyasztók általi
megtalálására gondolunk. A tartalom felfedezése azonban ennél jóval szélesebb
fogalmat takar. A közönség ugyanis a fogyasztók mellett olyan belső
felhasználókat is magában foglal, mint a kutatók, a tervezők, a
fotószerkesztők, a licenc-ügynökök stb. A PRISM, hogy növelje a felfedezés
valószínűségét, olyan tulajdonságokat definiál, amelyekkel leírható az
erőforrások témája, formátuma, jellege, eredete és kontextusa. De eszközöket
biztosít az erőforrások kategorizálására is, tematikus taxonómiák
formájában.
A jogok nyomon követése: A magazinok gyakran vesznek át anyagokat
más magazinoktól, kiadói licencek alapján. Ennek leggyakoribb formája
fotóügynökségek, fotóarchívumok anyagainak licencelése, de előfordulhat
cikkek, mellékcikkek és más hasonló tartalom licenc alapján történő
publikálása is. Azonban néha szinte reménytelen megtudni, hogy pl. egy
bizonyos tartalmat egyszeri használatra licenceltek-e, hogy kell e utána
szerzői jogdíjat fizetni, vagy hogy fenntart-e minden jogot az elsődleges
kiadó stb. Ezért a PRISM rendszer olyan elemeket tartalmaz, amelyekkel nyomon
követhetők az efféle jogok. A RRISM specifikációja egy külön szókészletet
definiál azoknak a helyeknek, időpontoknak és kiadói szakmáknak a leírására,
ahol az adott tartalom felhasználható, illetve, ahol nem felhasználható.
A meta-adatok megőrzése: A legtöbb publikált tartalom már ma is
el van látva meta-adatokkal. Azonban, ahogy a tartalom mozog a rendszerek
között, a meta-adatokat gyakran eldobják, hogy azután a produkciós folyamat
során, jelentős költséggel újra előállítsák azokat. A PRISM megpróbálja
csökkenteni ezt a problémát azzal, hogy olyan metaadat-specifikációt készít,
amelyik használható a tartalom előállítási folyamatának minden fázisában. A
PRISM specifikációjának fontos jellemzője a meglévő specifikációk
alkalmazása. A PRISM Munkacsoport ahelyett, hogy elkezdett volna elölről
kidolgozni egy teljesen új dolgot, elhatározta, hogy amennyire lehet,
felhasználja a már létező specifikációkat, és csak ott definiál új dolgokat,
ahol az feltétlenül szükséges. Ebből a célból kiindulva, a PRISM specifikáció
felhasználja az XML, az RDF, a Dublin Core specifikációit, valamint a
különböző ISO szabványú formátumokat és szókészleteket.
Egy PRISM leírás olyan egyszerű, mint néhány Dublin Core tulajdonság
megadása típus nélküli literál-értékekkel. A 34.
példa egy fényképfelvétel meta-adatait írja le alapvető információkkal a
felvétel címéről, a fotósról, a formátumról stb.
<?xml version="1.0" encoding="UTF-8"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xml:lang="en-US">
<rdf:Description rdf:about="http://travel.example.com/2000/08/Corfu.jpg">
<dc:title>Walking on the Beach in Corfu</dc:title>
<dc:description>Photograph taken at 6:00 am on Corfu with two models
</dc:description>
<dc:creator>John Peterson</dc:creator>
<dc:contributor>Sally Smith, lighting</dc:contributor>
<dc:format>image/jpeg</dc:format>
</rdf:Description>
</rdf:RDF>
A PRISM tovább bővíti a Dublin Core-t is abból a célból, hogy még
részletesebb leírásokat lehessen készíteni vele. A bővítményeket három új szókészletben definiálja, amelyeket a
névtér-prefixeik alapján általában prism:,
pcv: és prl: néven emlegetnek. Ezek szerepe a
következő:
A prism: minősítettnév-prefix a PRISM fő szókészletét
azonosítja, amelyben a kifejezések a
http://prismstandard.org/namespaces/basic/1.0/
URI-prefixet használják. Ebben a szókészletben a legtöbb tulajdonság a Dublin
Core tulajdonságok specifikusabb változata. Például a "dátum"
(dc:date) tulajdonság specifikusabb változatai: "a publikálás
ideje", "a kiadás ideje" és "az elévülés ideje" (prism:publicationTime,
prism:releaseTime, prism:expirationTime) stb.
A pcv: prefix a PRISM Controlled Vocabulary kifejezés
rövidítése, mely a PRISM "szabályozott" (controlled) szókészletét azonosítja.
Ennek a szókészletnek a kifejezései mind a
http://prismstandard.org/namespaces/pcv/1.0/ URI prefixet
használják. A jelenlegi gyakorlat egy cikk tárgyának vagy tárgyainak
leírására a kulcsszavak megadása. Sajnos azonban, az egyszerű kulcsszavak nem
növelik jelentősen a találat valószínűségét, főleg amiatt, hogy az emberek
néha különböző kulcsszavakat használnak azonos fogalmak megnevezésére [BATES96]. A legjobb módszer az lenne, ha a cikkek
témáit egy "szabályozott" (controlled) szókészletből vennék a cikk tartalmát
leírók. Ennek a szókészletnek minél több szinonimát kellene megadnia a benne
szereplő fogalmakra, hogy a keresők és az indexelők által használt
kifejezések minél nagyobb valószínűséggel találkozhassanak. A
pcv: szókészlet olyan tulajdonságokat tartalmaz, amelyekkel
kifejezéseket definiálhatunk, leírhatjuk a köztük lévő viszonyokat, és
alternatív változatokat is kapcsolhatunk hozzájuk.
A prl: prefix a PRISM Rights Language (PRISM jogok nyelve) nevű szókészlet rövidítése, amelynek a
kifejezései mind a http://prismstandard.org/namespaces/prl/1.0/
URI prefixet használják. A digitális jogok kezelése napjainkban egy
lendületesen fejlődő terület. Számos javaslat látott napvilágot jogkezelő
nyelvekre vonatkozóan, de eddig egyikük sem nyerte el a szakma egyértelmű
tetszését. Mivel nem volt miből választani, átmeneti megoldásként a PRL
nyelvet definiálták erre a célra. Ez olyan tulajdonságokat tartalmaz,
amelyekkel kijelenthetjük, hogy egy erőforrás használható-e, vagy nem
használható, az időtől a helytől és a szakmától függően. Ezt egy 80/20
százalékos arányú kompromisszumnak tekintik, amely bizonyos megtakarításokat
eredményezhet a kiadóknak, ha elkezdik nyomon követni a jogaik
érvényesülését. A PRL-t nem szánták sem egy általános jogkezelő nyelvnek, sem
pedig egy olyan automatikus mechanizmusnak, amellyel a kiadók korlátozhatják
a tartalom fogyasztók általi felhasználását.
A PRISM rendszer azért használja az RDF-et, mert ez lehetővé teszi a
legkülönbözőbb komplexitású leírások kezelését is. Jelenleg nagyon sok
meta-adat csupán egyszerű karakterláncokat használ (többnyire típus nélküli
literál-értékek leírására), mint pl a következő példa is:
<dc:coverage>Greece</dc:coverage>
A PRISM rendszer fejlesztői remélik, hogy idővel a PRISM specifikációi
egyre kifinomultabbak lesznek, és az egyszerű adatértékektől a
strukturáltabbak felé haladnak. Ezeknek az értéknek a köre az a kérdés, amely
most válaszra vár. Néhány kiadó már kifinomult, ún. "szabályozott"
szókészleteket használ, míg mások csak egyszerű, manuálisan megadott
kulcsszavakat használnak. Ennek illusztrálására bemutatunk néhány példát a
dc:coverage tulajdonság különböző lehetséges értékeire:
<dc:coverage>Greece</dc:coverage>
<dc:coverage rdf:resource="http://prismstandard.org/vocabs/ISO-3166/GR"/>
Itt előbb egy típus nélküli literál használatával, majd egy URIref
segítségével azonosítottuk Görögországot (Greece). Az alábbi példában pedig
már egy strukturált értéket adunk meg a Coverage tulajdonság értékeként,
amelyben szerepel az előbbi URIref, valamint Görögország neve két további
nyelven.
<dc:coverage>
<pcv:Descriptor rdf:about="http://prismstandard.org/vocabs/ISO-3166/GR">
<pcv:label xml:lang="en">Greece</pcv:label>
<pcv:label xml:lang="fr">Grčce</pcv:label>
</pcv:Descriptor>
</dc:coverage>
Figyeljük meg azt is, hogy léteznek olyan tulajdonságok, amelyeknek a
jelentése hasonló, vagy amelyek más tulajdonságok altulajdonságai. Például
egy erőforrás geográfiai tárgyát megadhatnánk a következő
tulajdonságokkal:
<prism:subject>Greece</prism:subject>
<dc:coverage>Greece</dc:coverage>
de megadhatjuk egy harmadik tulajdonsággal is:
<prism:location>Greece</prism:location>
E tulajdonságok bármelyike használható akár egyszerű literál-értékkel,
akár egy komplex strukturált értékkel. Az ilyen szélsőséges határok között
mozgó értéktartományokat azonban már nem lehet megfelelően leírni DTD-kkel,
de még az újabb XML sémákkal sem. Erre sokkal alkalmasabb az RDF, bár igaz,
hogy ennél a leírások többféle szintaktikai változatban is megjelenhetnek. Az
RDF gráfmodellje azonban egyszerű szerkezetű: lényegében tripletek halmaza.
Ezért a meta-adatok tripletek szintjén történő kezelése megkönnyítheti a
szoftverek számára a folyton bővülő tartalomhoz való alkalmazkodást.
Ezt a szekciót két példával zárjuk: a 35. példa
azt mondja, hogy a .../Corfu.jpg kép nem felhasználható
(#none) a dohányiparban, amelynek a kódszáma 21 az ipari
tevékenységek (USA-beli) szabványos osztályozási rendszerében (SIC):
<rdf:RDF xmlns:prism="http://prismstandard.org/namespaces/basic/1.0/"
xmlns:prl="http://prismstandard.org/namespaces/prl/1.0/"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/">
<rdf:Description rdf:about="http://travel.example.com/2000/08/Corfu.jpg">
<dc:rights rdf:parseType="Resource"
xml:base="http://prismstandard.org/vocabularies/1.0/usage.xml">
<prl:usage rdf:resource="#none"/>
<prl:industry rdf:resource="http://prismstandard.org/vocabs/SIC/21"/>
</dc:rights>
</rdf:Description>
</rdf:RDF>
A 36. példa azt mondja, hogy a Corfuban készült
felvétel fotográfusa a 3845. számú alkalmazott, akit John Peterson néven
ismernek. A leírásból az is kiderül, hogy a fotó földrajzi területe
(coverage) Görögország. Figyeljük meg, hogy itt egy szabályozott
szókészletből (pcv) vesszük a kifejezéseket, amelyeknek még a verziójáról is
van információ a leírásban (az xmlns:pcv
névtér-deklaráció URI-jében).
<?xml version="1.0" encoding="UTF-8"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:pcv="http://prismstandard.org/namespaces/pcv/1.0/"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xml:base="http://travel.example.com/">
<rdf:Description rdf:about="/2000/08/Corfu.jpg">
<dc:identifier rdf:resource="/content/2357845" />
<dc:creator>
<pcv:Descriptor rdf:about="/emp3845">
<pcv:label>John Peterson</pcv:label>
</pcv:Descriptor>
</dc:creator>
<dc:coverage>
<pcv:Descriptor
rdf:about="http://prismstandard.org/vocabs/ISO-3166/GR">
<pcv:label xml:lang="en">Greece</pcv:label>
<pcv:label xml:lang="fr">Grece</pcv:label>
</pcv:Descriptor>
</dc:coverage>
</rdf:Description>
</rdf:RDF>
Sok esetben szükség van arra, hogy információkat rögzítsünk erőforrások
olyan strukturált csoportosításáról, illetve ezek kapcsolatairól, amelyeket
adott esetben egységként kell kezelnünk. Az XML Csomag specifikáció (XML Package (XPackage)
specification, [XPACKAGE]) egy keretet
biztosít az ilyen, csomagoknak nevezett csoportosítások
definiálásához, és a bennük szereplő erőforrások leírásához: pontosabban az
erőforrások tulajdonságainak, a beépítésük módjának és egymáshoz való
viszonyának a leírásához. Az XPackage alkalmazásai felölelik az egy
dokumentum által használt stíluslapok (style sheets) specifikálását, a több
dokumentum által használt képek és ábrák deklarálását, a dokumentumok
szerzőjének és más meta-adatainak jelzését, továbbá annak leírását, hogy
miként használják a névtereket az XML erőforrások, és végül, olyan
"csomagjegyzék" előállítását, amely leírja, hogy milyen erőforrásokat
csomagoltunk össze egyetlen archív-fájlba.
Az XPackage keretrendszer az XML-re, az RDF-re és az XML Összekapcsoló
Nyelvre (XML Linking Language, [XLINK]) épül, és több RDF szókészletet tartalmaz: egy
szókészletet az általános összecsomagolási leírások számára, és több
szókészletet az erőforrásokról szóló kiegészítő információk megadásához,
amelyek a csomagot feldolgozó szoftver számára lehetnek hasznosak.
Az XPackage egyik alkalmazása az XHTML dokumentumok és támogató
erőforrásaik leírása. Egy XHTML dokumentum, amelyet letöltünk egy webhelyről,
általában több más erőforrásra támaszkodik (ilyenekre, mint pl. stíluslapok
és képfájlok), amelyeket ugyancsak le kell töltenünk. Ezeknek a támogató
erőforrásoknak az azonosító információja azonban nem derül ki az egész
dokumentum feldolgozása nélkül. Más információkhoz, mint pl. a szerző neve,
szintén csak a dokumentum feldolgozásával lehet hozzájutni. Az XPackage
lehetővé teszi, hogy az ilyen leíró információkat szabványos módon, egy RDF
alapú csomagleíró dokumentumban tároljuk. Egy ilyen XHTML fájlhoz készített
csomagleíró dokumentum külső elemei kb. úgy néznek ki, mint a 37. példában bemutatott leírásé (itt az egyszerűsítés
kedvéért a névtér-deklarációkat mellőztük):
<?xml version="1.0"?>
<xpackage:description>
<rdf:RDF>
(description of individual resources go here)
</rdf:RDF>
</xpackage:description>
Az erőforrások (mint pl. egy XHTML dokumentum, a stíluslapok és a
képek/ábrák) leírása a csomagleíró dokumentumokban szabványos RDF/XML
szintaxissal történik. Minden erőforrás-leíró elem használhat különféle RDF
szókészletekből származó tulajdonságokat (az XPackage az "ontológia"
kifejezést használja ott, ahol az RDF "szókészletet" mond). A fő csomagolási
szókészlet mellett az XPackage több kiegészítő szókészletet is specifikál,
amelyek a következők:
- egy
file: prefixet használó szókészlet fájlok leírására,
ilyen tulajdonságokkal, mint pl. "fájlméret" (file:size)
- egy
mime:prefixet használó szókészlet MIME információk
leírására, mint pl. "tartalomtípus" (mime:contentType).
- egy
unicode: prefixet használó szókészlet a
karakterhasználati információk megadására, ilyen tulajdonságokkal, mint
pl. unicode:script
- egy
x: prefixet használó szókészlet XML alapú erőforrások
leírására, ilyen tulajdonságokkal, mint pl. x:namespace és
x:style
A 38. példában, egy dokumentum MIME
tartalomtípusát ("application/xhtml+xml") definiáljuk egy szabványos XPackage
tulajdonság (mime:contentType) használatával, amely az XPackage
MIME szókészlet része. Emellett egy másik tulajdonságot, a dokumentum
szerzőjét (ebben az esetben Garret Wilson-t) is leírjuk a már ismert
dc:creator tulajdonsággal, mely az XPackage-en kívülről, a
Dublin Core szókészletből való:
<?xml version="1.0"?>
<xpackage:description
xmlns:xpackage="http://xpackage.org/namespaces/2003/xpackage#"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:mime="http://xpackage.org/namespaces/2003/mime#"
xmlns:x="http://xpackage.org/namespaces/2003/xml#"
xmlns:xlink="http://www.w3.org/1999/xlink">
<rdf:RDF>
<!--doc.html-->
<rdf:Description rdf:about="urn:example:xhtmldocument-doc">
<rdfs:comment>The XHTML document.</rdfs:comment>
<xpackage:location xlink:href="doc.html"/>
<mime:contentType>application/xhtml+xml</mime:contentType>
<x:namespace rdf:resource="http://www.w3.org/1999/xhtml"/>
<x:style rdf:resource="urn:example:xhtmldocument-stylesheet"/>
<dc:creator>Garret Wilson</dc:creator>
<xpackage:manifest rdf:parseType="Collection">
<rdf:Description rdf:about="urn:example:xhtmldocument-stylesheet"/>
<rdf:Description rdf:about="urn:example:xhtmldocument-image"/>
</xpackage:manifest>
</rdf:Description>
</rdf:RDF>
</xpackage:description>
A fenti példában a "csomagjegyzék" (xpackage:manifest)
tulajdonság azt jelzi, hogy mind a stíluslap, mind pedig a képfájl szükséges
a feldolgozáshoz; ezeket az erőforrásokat külön írjuk le a csomagleíró
dokumentumban.
A 39. példában megadott stíluslap leírása megadja
ennek az erőforrásnak a helyét a csomagon belül (stylesheet.css)
az általános XPackage szókészlet "helye" (xpackage:location)
tulajdonsága segítségével (mely kompatibilis az XLink-kel). A leírás azt is
megmutatja az XPackage MIME szókészlet "tartalomtípus"
(mime:contentType) tulajdonsága segítségével, hogy ez egy CSS
stíluslap ("text/css").
<?xml version="1.0"?>
<xpackage:description
xmlns:xpackage="http://xpackage.org/namespaces/2003/xpackage#"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:mime="http://xpackage.org/namespaces/2003/mime#"
xmlns:x="http://xpackage.org/namespaces/2003/xml#"
xmlns:xlink="http://www.w3.org/1999/xlink">
<rdf:RDF>
<!--stylesheet.css-->
<rdf:Description rdf:about="urn:example:xhtmldocument-css">
<rdfs:comment>The document style sheet.</rdfs:comment>
<xpackage:location xlink:href="stylesheet.css"/>
<mime:contentType>text/css</mime:contentType>
</rdf:Description>
</rdf:RDF>
</xpackage:description>
(Ennek a példának a komplettebb változata megtalálható az [XPACKAGE] dokumentumban.)
Néha szükségünk van arra, hogy napi rendszerességgel hozzáférhessünk
sokféle információhoz a weben (pl. ilyenekhez, mint menetrendek, teendők
listája, kereséséi eredmények, "Mi az új a webhelyen?" típusú információk
stb.). Ahogy az erőforrások mennyisége és változatossága növekszik a weben,
egyre nehezebb lesz kezelni és koherens egésszé integrálni az ilyen
információkat. Az RDF Webhely-összefoglaló (RDF Site Summary: RSS 1.0) egy olyan RDF szókészlet, mely
egy könnyű, de hatékony lehetőséget ad az olyan információk leírására és
újrafelhasználására, amelyeket meghatározott időben, nagy tömegben kell az
érdekeltekhez eljuttatni. Ezért az RSS 1.0 talán a legszélesebb körben
használt RDF alkalmazás a weben.
Hogy egy egyszerű példát említsünk, maga a W3C honlapja is egy elsődleges találkozási pont
a közönséggel, mely részben arra szolgál, hogy szétküldje a Konzorcium által
produkált anyagokról szóló információkat az érdekeltek számára. A W3C
honlapnak egy meghatározott napon megjelent állapotát mutatja a 19. ábra. A hírek középső hasábja gyakran változik. Hogy
támogassa ennek az információnak az időzített szétosztását, a W3C készített
egy RSS 1.0 alapú hírtovábbító
alkalmazást, mely a középső hasáb tartalmát mások számára is hozzáférhetővé
teszi, hogy tetszésük szerint felhasználhassák azt. Az RSS használatával a
hírcsoportosító webhelyek összefoglalót készíthetnek a napok legfontosabb
híreiből, míg mások, az olvasóik kiszolgálása érdekében, hiperszöveg
hivatkozások formájában kiírhatják a címeket a saját honlapjukra. Az is egyre
gyakoribb, hogy egyének előfizetnek egyes hírcsomagok automatikus
továbbítására és vételére, egy erre alkalmas asztaliszámítógép-szoftver
segítségével. Az ilyen asztali RSS olvasó programok lehetővé teszik a
felhasználóknak, hogy akár webhelyek százait is figyelemmel kövessék anélkül,
hogy akárcsak egyet is fel kellene keresniük a böngészőjük segítségével.
Számtalan webhely nyújt RSS 1.0 alapú információ továbbító szolgáltatást.
A 40. példa a W3C feed egyik
küldeményét mutatja (ez egy másik dátumról származik):
<?xml version="1.0" encoding="utf-8"?>
<rdf:RDF xmlns="http://purl.org/rss/1.0/"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<channel rdf:about="http://www.w3.org/2000/08/w3c-synd/home.rss">
<title>The World Wide Web Consortium</title>
<description>Leading the Web to its Full Potential...</description>
<link>http://www.w3.org/</link>
<dc:date>2002-10-28T08:07:21Z</dc:date>
<items>
<rdf:Seq>
<rdf:li rdf:resource="http://www.w3.org/News/2002#item164"/>
<rdf:li rdf:resource="http://www.w3.org/News/2002#item168"/>
<rdf:li rdf:resource="http://www.w3.org/News/2002#item167"/>
</rdf:Seq>
</items>
</channel>
<item rdf:about="http://www.w3.org/News/2002#item164">
<title>User Agent Accessibility Guidelines Become a W3C
Proposed Recommendation</title>
<description>17 October 2002: W3C is pleased to announce the
advancement of User Agent Accessibility Guidelines 1.0 to
Proposed Recommendation. Comments are welcome through 14 November.
Written for developers of user agents, the guidelines lower
barriers to Web accessibility for people with disabilities
(visual, hearing, physical, cognitive, and neurological).
The companion Techniques Working Draft is updated. Read about
the Web Accessibility Initiative. (News archive)</description>
<link>http://www.w3.org/News/2002#item164</link>
<dc:date>2002-10-17</dc:date>
</item>
<item rdf:about="http://www.w3.org/News/2002#item168">
<title>Working Draft of Authoring Challenges for Device
Independence Published</title>
<description>25 October 2002: The Device Independence
Working Group has released the first public Working Draft of
Authoring Challenges for Device Independence. The draft describes
the considerations that Web authors face in supporting access to
their sites from a variety of different devices. It is written
for authors, language developers, device experts and developers
of Web applications and authoring systems. Read about the Device
Independence Activity (News archive)</description>
<link>http://www.w3.org/News/2002#item168</link>
<dc:date>2002-10-25</dc:date>
</item>
<item rdf:about="http://www.w3.org/News/2002#item167">
<title>CSS3 Last Call Working Drafts Published</title>
<description>24 October 2002: The CSS Working Group has
released two Last Call Working Drafts and welcomes comments
on them through 27 November. CSS3 module: text is a set of
text formatting properties and addresses international contexts.
CSS3 module: Ruby is properties for ruby, a short run of text
alongside base text typically used in East Asia. CSS3 module:
The box model for the layout of textual documents in visual
media is also updated. Cascading Style Sheets (CSS) is a
language used to render structured documents like HTML and
XML on screen, on paper, and in speech. Visit the CSS home
page. (News archive)</description>
<link>http://www.w3.org/News/2002#item167</link>
<dc:date>2002-10-24</dc:date>
</item>
</rdf:RDF>
Mint a 40. példa mutatja, a formátumot úgy
tervezték meg, hogy a tartalmat könnyen megkülönböztethető szekciókba
lehessen csomagolni. A hírportálok, a webnaplók, a sporteredmények, a tőzsdei
hírek, és ehhez hasonló információküldő szolgáltatások az RSS 1.0. tipikus
alkalmazási esetei.
Az RSS információküldés bármelyik alkalmazáson keresztül igényelhető,
amelyik használja a HTTP protokollt. Az utóbbi időben azonban az RSS 1.0
alkalmazások kezdenek három különböző kategóriára bomlani:
- On-line tartalomegyesítő webhelyek: a 20. ábra
két ilyent ábrázol egymás mellé állítva (Meerkat
és NewsIsFree,
mindkettő tükrözi a W3C hírrovatát is). Ezek, források ezreiből gyűjtik
az automatikusan küldött anyagokat, és először szétszedik <item>
tegek szerint, majd pedig nagy, tematikus csoportokba ismét összerakják
őket, végül az ilyen csoportot kereshetővé teszik. Ilyen módon
megkereshetjük a több száz webhelyről származó legfrissebb híreket pl. a
"Java" programozási rendszerről anélkül, hogy akárcsak egyet is fel
kellene keresnünk ezek közül.
- Asztali hírolvasó programok: pl. az Amphetadesk és a NetNewsWire Lite, lehetővé
teszik a felhasználóiknak, hogy az íróasztalukról előfizessenek akár több
száz automatikusan küldött információra is. Ezek az olvasóprogramok
általában óránként frissítik a rajtuk keresztül megrendelt híreket, hogy
a felhasználó mindig napra kész legyen az adott témában.
- Inzertek (scripts): Az RSS eredeti célja az volt, hogy lehetővé tegye a
webmesterek számára, hogy a más webhelyekről származó információt
beépítsék a sajátjukba. Az RSS 1.0-t még ma is sok webhelyen (pl. a Slashdot-nál is) arra használják, hogy
segítségével beépítik az RSS küldeményeket a saját honlapjukba.
Az RSS 1.0 tervezés útján bővíthető. További RDF szókészletek (vagy
modulok – ahogy az RSS közösségekben hívják őket)
importálásával az RSS 1.0 fejlesztő nagy mennyiségű meta-adatot és kezelési
instrukciót adhat át a fájlt fogadó alkalmazás számára. Modulokat bárki
írhat, ugyanúgy, ahogy általánosabb RDF szókészleteket. Jelenleg 3 hivatalos modul és 19 javasolt
modul ismeretes; ezeket széles körben elfogadja az RSS alkalmazói
közösség. Ezek a modulok a komplett Dublin Core module-tól
a specializáltabb RSS-centrikus modulokig terjednek, mint pl. az
információegyesítési modul (Aggregation
module).
Bizonyos óvatosságra van szükség, amikor RDF értelemben beszélünk az
RSS-ről, ugyanis jelenleg két szálon fut az RSS specifikációs tevékenység: az
egyik szál (RSS 0.91, 0.92, 0.93, 0.94 és 2.0) nem használja az RDF-et, míg a
másik (RSS 0.9 és 1.0) használja.
6.5 CIM/XML
Az elektromos közműhálózatok többféle célra használnak
energiaellátórendszer-modelleket. Az ilyen rendszerek szimulációja
elengedhetetlen mind a tervezéshez, mind pedig a biztonsági elemzésekhez, de
ilyen modelleket használnak az üzemeltetés során is pl. a
teherelosztó-központok energiagazdálkodási rendszereiben (Energy Management
Systems – EMS). Egy üzemeltetési célú energiaellátórendszer-modell
akár információ-osztályok ezreit is tartalmazhatja. És ezeket a modelleket
nemcsak "házon belül" használják, de az elektromos közművek ki is cserélik
egymás között a modell-információkat, mind tervezési, mind üzemeltetési
célokra (pl. az energiatovábbítás koordinálására és a megbízható üzemeltetés
biztosítására). Az egyes elektromos közműhálózatok azonban különböző
szoftvereket használnak erre, és emiatt a rendszermodelleket különböző
formátumokban tárolják, megnehezítve ezzel a modellek cseréjét.
Hogy támogassák a rendszermodellek hordozhatóságát, az
energiaszolgáltatóknak meg kellett egyezniük a rendszerek entitásainak és a
köztük lévő viszonyoknak a közös definíciójában. Ebből a célból az EPRI, (Electric Power Research Institute, egy
kaliforniai, nonprofit energiakutató konzorcium), kifejlesztett egy közös
információs modellt (Common Information Model [CIM]
néven). A CIM egy közös szemantikát definiál a villamosenergia-hálózatok
erőforrásai, ezek jellemzői és kapcsolatai számára. Emellett, hogy támogassák
a CIM modellek elektronikus továbbítását is, a villamosenergia-ipari szakma
kifejlesztett egy nyelvet a CIM modellek leírására, CIM/XML néven. A CIM/XML egy
RDF alkalmazás, mely az RDF-et és az RDF Sémát használja az XML struktúrák
szervezésére. A North American Electric
Reliability Council (egy ipari hátterű, észak-amerikai nonprofit
szervezet, amelyet az elektromos energia szállításának biztonságosabbá tétele
céljából alapítottak) ipari szabványként adoptálta a CIM/XML-t az
energiaszállító rendszerek üzemeltetői közötti modellcsere céljára. A CIM/XML
nemzetközi IEC szabványosítása is folyamatban van. A CIM/XML nyelv egy kitűnő
ismertetését adja a [DWZ01]. [Nota bene: ez a
villamosenergia-ipari CIM nem tévesztendő össze a Distributed Management Task Force által
kifejlesztett hasonló nevű (DMTF CIM) produktummal, mely vállalatirányítási
információ ábrázolására szolgál elosztott szoftverek, hálózatok és vállalatok
környezetében. A DMTF CIM-nek is van egy XML reprezentációja, bár ez még nem
használ RDF-et, de már folynak független kutatások ez irányban is.]
A CIM segítségével ábrázolhatók az elektromos közművek által használt
objektumosztályok, valamint ezek attribútumainak és viszonyainak túlnyomó
többsége. A CIM arra használja ezeket az objektumosztályokat és
attribútumaikat, hogy támogassa az egymástól függetlenül fejlesztett
alkalmazások integrálását (például: gyártó-specifikus energiagazdálkodási
rendszerek (EMS-ek) egymás közötti integrációját, vagy EMS-eknek olyan
rendszerekkel való integrációját, amelyek az energiarendszerek egyéb
aspektusaival foglalkoznak, mint pl. a villamos energia előállításának és
szállításának irányítása).
A CIM-et osztálydiagramok halmazaként specifikálták az Egységes Modellező
Nyelv (Unified Modeling Language –
UML) segítségével. A CIM bázis-osztálya az Energiarendszer-erőforrás
(PowerSystemResource) osztály, mely további, egyre
specializáltabb osztályokra bomlik, mint pl. Alállomás (Substation), Kapcsoló
(Switch) és Megszakító (Breaker), amelyeket egymás
alosztályaiként definiáltak. A CIM/XML a CIM szókészletét RDF Séma
szókészletként ábrázolja, az RDF/XML nyelvet pedig a specifikus
rendszermodellek adatcsere-nyelveként használja. A 41.
példa CIM/XML alapú osztály- és tulajdonságdefiníciókat mutat be:
<rdfs:Class rdf:ID="PowerSystemResource">
<rdfs:label xml:lang="en">PowerSystemResource</rdfs:label>
<rdfs:comment>"A power system component that can be either an
individual element such as a switch or a set of elements
such as a substation. PowerSystemResources that are sets
could be members of other sets. For example a Switch is a
member of a Substation and a Substation could be a member
of a division of a Company"</rdfs:comment>
</rdfs:Class>
<rdfs:Class rdf:ID="Breaker">
<rdfs:label xml:lang="en">Breaker</rdfs:label>
<rdfs:subClassOf rdf:resource="#Switch" />
<rdfs:comment>"A mechanical switching device capable of making,
carrying, and breaking currents under normal circuit conditions
and also making, carrying for a specified time, and breaking
currents under specified abnormal circuit conditions e.g. those
of short circuit. The typeName is the type of breaker, e.g.,
oil, air blast, vacuum, SF6."</rdfs:comment>
</rdfs:Class>
<rdf:Property rdf:ID="Breaker.ampRating">
<rdfs:label xml:lang="en">ampRating</rdfs:label>
<rdfs:domain rdf:resource="#Breaker" />
<rdfs:range rdf:resource="#CurrentFlow" />
<rdfs:comment>"Fault interrupting rating in amperes"</rdfs:comment>
</rdf:Property>
A CIM/XML a teljes RDF/XML szintaxisnak csak egy részhalmazát használja,
hogy egyszerűsítse a modell-alkotást. Ugyanakkor a CIM/XML implementál néhány
további bővítményt is az RDF Séma szókészletéhez. Ezek a bővítmények az
inverz szerepet és a multiplicitás (RDF terminológiával: kardinalitás)
korlátozását támogatják. Ez utóbbi korlátozás azt jelenti, hogy egy adott
tulajdonság hány különböző értékkel alkalmazható egy adott erőforrás
jellemzésére (ennek megengedett értékei itt: zéró-vagy-egy, pontosan-egy,
zéró-vagy-több, egy-vagy-több). A 42. példában
látható tulajdonságok ezeket a bővítményeket illusztrálják. (Ezeket a
példában a cims: minősítettnév-prefixszel azonosítjuk):
<rdf:Property rdf:ID="Breaker.OperatedBy">
<rdfs:label xml:lang="en">OperatedBy</rdfs:label>
<rdfs:domain rdf:resource="#Breaker" />
<rdfs:range rdf:resource="#ProtectionEquipment" />
<cims:inverseRoleName rdf:resource="#ProtectionEquipment.Operates" />
<cims:multiplicity rdf:resource="http://www.cim-logic.com/schema/990530#M:0..n" />
<rdfs:comment>"Circuit breakers may be operated by
protection relays."</rdfs:comment>
</rdf:Property>
<rdf:Property rdf:ID="ProtectionEquipment.Operates">
<rdfs:label xml:lang="en">Operates</rdfs:label>
<rdfs:domain rdf:resource="#ProtectionEquipment" />
<rdfs:range rdf:resource="#Breaker" />
<cims:inverseRoleName rdf:resource="#Breaker.OperatedBy" />
<cims:multiplicity rdf:resource="http://www.cim-logic.com/schema/990530#M:0..n" />
<rdfs:comment>"Circuit breakers may be operated by
protection relays."</rdfs:comment>
</rdf:Property>
Az EPRI sikeres együttműködőképesség-teszteket hajtott végre a CIM/XML
felhasználásával gyakorlati célú, nagy méretű modellek különböző gyártóktól
származó produktumok közötti cseréje útján, ahol az egyik tesztben több, mint
2000 alállomás leírását tartalmazó adat is szerepelt. Ezek a tesztek
megerősítették, hogy a modelleket korrekt módon interpretálnák a tipikus
alkalmazások. Annak ellenére, hogy a CIM-et eredetileg EMS rendszerek
céljaira szánták, sikerült azt oly módon kibővíteni, hogy támogatni tudja az
energiaelosztást és más alkalmazásokat is.
Az Object Management Group (OMG)
elfogadott egy objektum-interfész szabványt a CIM energiarendszer-modellek
elérésére, amelyet Adatelérési eszköznek (Data Access Facility [DAF]) nevezett el. Ugyanúgy, mint a CIM/XML nyelv, a DAF
is az RDF modellen alapszik, és ugyanazt a CIM sémát használja. De amíg a
CIM/XML dokumentumok formájában teszi lehetővé a modellek cseréjét, addig a
DAF objektumhalmazok formájában biztosítja ugyanezt.
A CIM/XML jól illusztrálja azt a hasznos szerepet, amelyet az RDF játszhat
az olyan információk XML alapú cseréjében, amelyek természetes módon
kifejezhetők entitások közötti viszonyok, vagy pedig objektumorientált
osztályok, attribútumok és a közöttük lévő viszonyok segítségével (akkor is,
ha ezek az információk nem szükségszerűen elérhetők a weben keresztül).
Ezekben az esetekben az RDF egy alapvető struktúrát biztosít az XML számára
az objektumok azonosításának, és strukturált viszonyokban való alkalmazásának
támogatására. Ezt az összefüggést jól illusztrálja az a sok alkalmazás, mely
az RDF/XML-t használja információcsere céljára, de jól illusztrálja az a
számos projekt is, amelyik keresi a kapcsolatot az RDF (vagy az
ontológianyelvek, mint pl. az OWL) és az UML (vagy annak XML reprezentációja)
között. A CIM/XML-nek az a szükséglete, amely miatt ki kellett bővítenie az
RDF Sémát a multiplicitáskorlázozás (kardinalitáskorlátozás) és az inverz
viszonyok támogatásához szükséges elemekkel, ugyanazokat az igénytípusokat
jelzi, amelyek az olyan, nagyobb teljesítményű RDF alapú séma- vagy
ontológianyelvek kifejlesztéséhez vezettek, mint milyen az 5.5 szekcióban már ismertetett DAML+OIL és OWL.
Ezek a nyelvek tehát alkalmasak lehetnek sok hasonló modellező alkalmazás
támogatására.
És végül, a CIM/XML egy másik fontos tényt is illusztrál azok számára,
akik további "RDF a gyakorlatban" típusú példákat keresnek: az RDF
alkalmazásokhoz használt nyelveket sokszor csak úgy emlegetik, mint "XML"
nyelveket, vagy egyes rendszerekre úgy hivatkoznak, mint amelyek "XML"-t
használnak, miközben ténylegesen RDF/XML-ről van szó, tehát valójában RDF
alkalmazásokról kellene beszélnünk. Néha meglehetősen mélyen bele kell ásnunk
magunkat az ilyen nyelvek leírásába, hogy ezt észrevegyük (néhány általunk
felfedezett alkalmazási esetnél egyszer sem említették meg explicit módon az
RDF nevét, de a mintaként megvizsgált adatok világosan kimutatták, hogy
RDF/XML-ről van szó). Sőt, egyes alkalmazásokban, mint pl. a CIM/XML, az
előállított RDF kód nem is jelenik meg a weben, minthogy ezt lokális
szoftverkomponensek közötti információcsere céljára szánják, nem pedig
általános hozzáférés céljára (habár elképzelhetők olyan jövőbeli alkalmazási
variánsok is, amelyekben az ilyen típusú RDF adatok is hozzáférhetővé válnak
a weben).
6.6 GO (Gén-ontológiai Konzorcium)
Az olyan strukturált meta-adatok, amelyek szabályozott (controlled)
szókészleteket használnak, mint például az orvostudományi terminológiát leíró
SNOMED RT (Systematized Nomenclature of
Medicine Reference Terminology), vagy az orvostudomány címszavait rendszerező
szótár MeSH (Medical
Subject Headings) fontos szerepet játszanak az orvostudományban azáltal, hogy
lehetővé teszik a hatékonyabb irodalomkutatást, és segítik az orvostani
ismeretek terjesztését és cseréjét [COWAN]. Az
orvostudomány azonban gyorsan fejlődik, és ez szükségessé teszi egyre újabb
szókészletek kifejlesztését.
A Gén-ontológiai Konzorcium (Gene
Ontology (GO) Consortium,[GO]) célja olyan
szókészletek rendelkezésre bocsátása, amelyek leírják a génproduktumok
specifikus aspektusait. Az együttműködő adatbázisok GO kifejezésekkel
címkézik (annotálják) a génproduktumokat (vagy a géneket), és ezáltal
kölcsönös hivatkozási lehetőségeket teremtenek, valamint jelzik azt is, hogy
milyen bizonyítékok támasztják alá ezeket az annotációkat. A közös GO
kifejezések használata ezekben az adatbázisokban megkönnyíti az egységes
lekérdezést. A GO-féle ontológiák strukturáltak, hogy mind a jellemzést, mind
pedig a lekérdezést el lehessen végezni a részletesség (granularitás)
különböző szintjein. A GO szókészletek dinamikusak, hiszen a gének és
proteinek sejtbeli szerepével kapcsolatos ismeretek folyamatosan szaporodnak
és változnak.
A GO három szervezési alapelve a molekuláris funkció, a biológiai
folyamat és a sejtkomponens. Egy génproduktumnak egy vagy több
molekuláris funkciója van, és egy vagy több biológiai folyamatban használják
fel; ez esetleg kapcsolatban lehet egy vagy több sejtkomponenssel. A
kifejezések definícióját e három ontológiában egy-egy szövegfájl tartalmazza.
Mindhárom szövegfájlból havonta generálnak egy-egy XML formátumú változatot,
amelyek tartalmazzák az összes rendelkezésre álló GO kifejezést.
A funkciókat, folyamatokat és komponenseket nemciklikus irányított gráfok
vagy hálók formájában ábrázolják. Itt egy gyermekfogalom kétféle viszonyban
lehet a szülőfogalmával: lehet annak egyik "esete" (ez az alosztály-osztály,
vagy "is a" [isa] reláció), vagy lehet annak egyik "komponense" (ez a
rész-egész, vagy "part of" reláció). Egy gyermekfogalomnak lehet egynél több
szülőfogalma, és a gyermek lehet különböző típusú viszonyban a különböző
szülőivel. A GO ontológiák ábrázolják a szinonimákat és az adatbázisok
közötti kereszthivatkozásokat is. A GO rendszer RDF/XML-t használ a fogalmak
közötti viszonyok ábrázolására az ontológiák XML változatában, mivel ez
kellőképpen flexibilis az ilyen gráfstruktúrák ábrázolásában, és széleskörű
eszköztámogatással is rendelkezik. Ugyanakkor a GO jelenleg nem-RDF típusú
beágyazott struktúrákat használ a kifejezések leírásában, tehát a használt
nyelv nem teljesen tiszta RDF/XML.
A 43. példa néhány minta jellegű GO információt
mutat be, amelyek a GO
dokumentációjából származnak:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE go:go>
<go:go xmlns:go="http://www.geneontology.org/xml-dtd/go.dtd#"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<go:version timestamp="Wed May 9 23:55:02 2001" />
<rdf:RDF>
<go:term rdf:about="http://www.geneontology.org/go#GO:0003673">
<go:accession>GO:0003673</go:accession>
<go:name>Gene_Ontology</go:name>
<go:definition></go:definition>
</go:term>
<go:term rdf:about="http://www.geneontology.org/go#GO:0003674">
<go:accession>GO:0003674</go:accession>
<go:name>molecular_function</go:name>
<go:definition>The action characteristic of a gene product.</go:definition>
<go:part-of rdf:resource="http://www.geneontology.org/go#GO:0003673" />
<go:dbxref>
<go:database_symbol>go</go:database_symbol>
<go:reference>curators</go:reference>
</go:dbxref>
</go:term>
<go:term rdf:about="http://www.geneontology.org/go#GO:0016209">
<go:accession>GO:0016209</go:accession>
<go:name>antioxidant</go:name>
<go:definition></go:definition>
<go:isa rdf:resource="http://www.geneontology.org/go#GO:0003674" />
<go:association>
<go:evidence evidence_code="ISS">
<go:dbxref>
<go:database_symbol>fb</go:database_symbol>
<go:reference>fbrf0105495</go:reference>
</go:dbxref>
</go:evidence>
<go:gene_product>
<go:name>CG7217</go:name>
<go:dbxref>
<go:database_symbol>fb</go:database_symbol>
<go:reference>FBgn0038570</go:reference>
</go:dbxref>
</go:gene_product>
</go:association>
<go:association>
<go:evidence evidence_code="ISS">
<go:dbxref>
<go:database_symbol>fb</go:database_symbol>
<go:reference>fbrf0105495</go:reference>
</go:dbxref>
</go:evidence>
<go:gene_product>
<go:name>Jafrac1</go:name>
<go:dbxref>
<go:database_symbol>fb</go:database_symbol>
<go:reference>FBgn0040309</go:reference>
</go:dbxref>
</go:gene_product>
</go:association>
</go:term>
</rdf:RDF>
</go:go>
A 43. példából látható, hogy a
go:term kifejezés az alapvető elem. Egyes esetekre a GO saját
kifejezéseket definiált ahelyett, hogy az RDF Sémát használta volna. Például
a GO:0016209 kifejezésnek van egy ilyen eleme: <go:isa
rdf:resource="http://www.geneontology.org/go#GO:0003674" />. Ez a
teg a "GO:0016209 isa GO:0003674" összefüggést
reprezentálja, amelynek a jelentése itt: "Antioxidant is
a molecular function" (az antioxidáns egy molekuláris funkció).
Egy másik sajátos GO viszony a "része ~nak" (part of) reláció. Például a
GO:0003674-nek van egy ilyen eleme: <go:part-of
rdf:resource="http://www.geneontology.org/go#GO:0003673" />. Ennek
a jelentése: "Molecular function is part of the Gene Ontology" (a
molekuláris funkció része a gén-ontológiának).
Minden annotációt (címkézést, hozzáfűzött megjegyzést) valamilyen
forráshoz kell kapcsolni, mely lehet egy szakirodalmi hivatkozás, egy másik
adatbázis, vagy egy számítógépes elemzés. Az annotációnak jeleznie kell,
milyen bizonyíték található az idézett forrásban, mely alátámasztja az
asszociációt a génproduktum és a GO kifejezés között. Egy egyszerű
szabályozott szókészletet használnak a bizonyítékok rögzítésére. Néhány példa
a bizonyíték típusokra:
- ISS: ennek jelentése "inferred from sequence similarity [with
<database:sequence_id>]" ("következtetés a szekvencia hasonlósága
alapján) [egy <database:sequence_id> elemmel együtt]
- IDA: ennek jelentése "inferred from direct assay" (következtetés
közvetlen vizsgálatból)
- TAS: ennek jelentése "traceable author statement" (ellenőrizhető
szerzői kijelentés)
A go:dbxref elem ábrázolja valamely külső adatbázis egyik
kifejezését, a go:association pedig egy kifejezés asszociációját
egy génhez. A go:association elemben lehet mind
go:evidence elem (amelynek van egy go:dbxref
kereszthivatkozása az asszociációt indokoló bizonyítékra), mind pedig
go:gene_product elem, mely tartalmazza a gén szimbólumát és egy
gén hivatkozást (go:reference). Ezek az elemek is mutatják, hogy
a GO XML szintaxisa nem "tiszta" RDF/XML, hiszen más elemek beágyazása ezekbe
az elemekbe nem felel meg a váltakozó csomópont-él-csomópont-él
"csíkozásnak", ahogy ez az [RDF-SZINTAXIS]
dokumentum 2.1 és 2.2 szekciójában szerepel.
A GO több érdekes kérdésre is rávilágít. Először is megmutatja, hogy az
XML használati értéke az információcserében növelhető azáltal, hogy RDF
alapon strukturáljuk az XML kódot. Ez különösen igaz az olyan adatokra,
amelyek egy átfogó gráf- vagy hálóstruktúrát, nem pedig szigorú hierarchiát
alkotnak. A GO szintén egyik példája az olyan eseteknek, ahol az RDF-et
használó adatok nem szükségszerűen jelennek meg az Interneten (közvetlenül
használható formában), bár a fájlok, maguk, elérhetők a weben. Továbbá, a GO
adatstruktúrái példának tekinthetők arra a jelenségre is, hogy a felületen
"XML"-nek látszanak, de egy mélyebb elemzés kimutatja, hogy valójában RDF/XML
eszközöket használnak (még ha nem is "tiszta" RDF/XML formában). És végül, a
GO jól mutatja, hogy az RDF milyen szerepet játszhat az ontológiák
ábrázolásában. Ez a szerep egyre jelentősebb lesz, ahogy a gazdagabb RDF
alapú ontológianyelvek egyre szélesebb körben elterjednek (ilyen
ontológianyelv a DAML+OIL vagy az OWL, amelyek lényegét az 5.5 szekcióban tömören ismertettük). Ennek látható
jele az is, hogy a következő generációs GO projekt (Gene Ontology Next Generation) már az
ilyen, gazdagabb nyelvek segítségével kívánja ábrázolni a GO ontológiákat.
Az utóbbi években nagyszámú, olyan mobil készülék jelent meg a
forgalomban, amellyel böngészni lehet a webet. Ezek közül sok készülék nagyon
különböző képességekkel rendelkezik az input-output opciók és a
nyelvtámogatás szintje tekintetében. A mobil készülékek a hálózati
csatlakozási lehetőségeiket tekintve is elég széles skálán mozogatnak.
Ezeknek az új készülékeknek a használói a készülék képességeire és a hálózat
pillanatnyi állapotára való tekintet nélkül elvárják a használható minőségű
tartalomkijelzést. Hasonlóképpen elvárják azt is, hogy amikor egy alkalmazás
vagy egy webtartalom megjelenik a készüléken, akkor az vegye figyelembe a
felhasználó dinamikusan változó preferenciáit (pl. kapcsolja ki, vagy be a
hangot). A realitás azonban az, hogy a készülékek különbözősége, és egy olyan
szabványos módszer hiánya, amellyel közvetíteni lehetne a felhasználó
preferenciáit a kiszolgáló felé, oda vezet, hogy olyan tartalom is
megjelenik, amelyik vagy nem tárolható, vagy nem megjeleníthető a készüléken,
vagy esetleg sérti a felhasználó érdekeit. Sőt, az ilyen tartalom átvitele a
hálózaton keresztül az előfizető készülékére még túl hosszú időt is
igényelhet.
Egy olyan megoldás, mely ezeket a problémákat megszüntetné, az lehetne, ha
a felhasználó valahogy kódolhatná a saját vételi környezetét – a
készülék képességeit, a felhasználói preferenciáit, a hálózat jellemzőit stb.
– úgy, hogy a kiszolgáló felhasználhatná ezt a környezeti információt
a tartalomnak a készülék képességei és a felhasználó kívánságai szerinti
"konfekcionálására" (lásd [DIPRINC]-nél a vételi
környezet [delivery context] definícióját). A W3C Összetett
Képesség/Preferencia Profil című specifikációja (Composite
Capabilities/Preferences Profile specification [CC/PP]) segít megoldani ezt a problémát azáltal, hogy
definiál egy generikus keretet a vételi környezet leírására.
A CC/PP-keret egy viszonylag egyszerű szerkezetet definiál, mely a
komponensek és attribútum-érték párok kétszintű hierarchiájából áll. Egy-egy
komponenst használhatunk a vételi környezet egy-egy részének (mint.
pl. hálózati jellemzők, a készülék szoftverkonfigurációja, vagy a készülék
hardver jellemzői) specifikálására. Egy komponens egy vagy több
attribútumot tartalmazhat. Például egy olyan komponens, mely a
felhasználó preferenciáit kódolja, tartalmazhat egy attribútumot, mely azt
adja meg, hogy kívánatos-e a hang megjelenítése is.
A CC/PP az imént felvázolt struktúráit az RDF Séma segítségével definiálja
(a struktúra sémájának részleteit lásd a [CC/PP]-nél). A CC/PP-vel definiálhatjuk az egyes
komponenseket, és az ezek attribútumait leíró szókészletet, de a CC/PP, maga,
nem definiál előre ilyen szókészleteket. A szókészleteket más szervezetek
vagy alkalmazások definiálják (ahogy azt alább bemutatjuk). A CC/PP nem
definiál olyan protokollt sem, amely az ilyen szókészlet-példányok átvitelét
szabályozná.
A CC/PP szókészlet egy példányát profilnak nevezzük. A CC/PP
attribútumait RDF tulajdonságok formájában kódoljuk a profilban. A 44. példa egy olyan profilrészletet mutat be, amelyben
az a felhasználói preferencia van kódolva, hogy kívánatos a hang
kijelzése:
<ccpp:component>
<rdf:Description rdf:ID="UserPreferences">
<rdf:type rdf:resource="http://www.example.org/profiles/prefs/v1_0#UserPreferences"/>
<ex:AudioOutput>Yes</ex:AudioOutput>
<ex:Graphics>No</ex:Graphics>
<ex:Languages>
<rdf:Seq>
<rdf:li>en-cockney</rdf:li>
<rdf:li>en</rdf:li>
</rdf:Seq>
</ex:Languages>
</rdf:Description>
</ccpp:component>
Ebben az alkalmazásban több előnye is van az RDF használatának. Az egyik
ilyen, hogy egy CC/PP-vel kódolt profil olyan attribútumokat tartalmazhat,
amelyek különböző szervezetek által definiált sémákból származnak. Az RDF
használata az ilyen profilok készítésére nagyon is kézenfekvő, hiszen nehezen
elképzelhető, hogy egyetlen szervezet előállítana egy olyan
szupersémát, mely egyesített adatként tartalmazná az összes profilt.
Az RDF másik nagy előnye, hogy gráf alapú adatmodelljénél fogva megkönnyíti
bármilyen újabb attribútum (RDF tulajdonság) beépítését a profilba. Ez
különösen hasznos az olyan profiloknál, amelyek gyakran változó adatokat
tartalmaznak (mint pl. a helyszínnel kapcsolatos információk).
A Nyílt Mobil Szövetség (Open Mobile Alliance) definiált egy Felhasználói
Ügynök Profilt (User Agent Profile, UAProf, lásd: [UAPROF]) – egy CC/PP alapú keretet, mely
tartalmaz egy szókészletet a készülék képességeinek, a felhasználó oldali
ágens képességeinek, a hálózati jellemzőknek és más hasonló komponenseknek a
leírására, továbbá tartalmaz egy protokollt is a profilok átvitelére. Ez az
UAProf hat komponenst definiál, köztük pl. a
HardwarePlatform, a SoftwarePlatform, a
NetworkCharacteristics és a BrowserUA komponenst. Az
UAProf minden egyes komponens számára több attribútumot is definiál,
de ezek az attribútumok nem rögzítettek, azokat felül lehet írni, vagy ki
lehet egészíteni. A 45. példa az UAProf
"HardwarePlatform" komponensének egy részletét mutatja be:
<prf:component>
<rdf:Description rdf:ID="HardwarePlatform">
<rdf:type rdf:resource="http://www.openmobilealliance.org/profiles/UAPROF/ccppschema-20021113#HardwarePlatform"/>
<prf:ScreenSizeChar>15x6</prf:ScreenSizeChar>
<prf:BitsPerPixel>2</prf:BitsPerPixel>
<prf:ColorCapable>No</prf:ColorCapable>
<prf:BluetoothProfile>
<rdf:Bag>
<rdf:li>headset</rdf:li>
<rdf:li>dialup</rdf:li>
<rdf:li>lanaccess</rdf:li>
</rdf:Bag>
</prf:BluetoothProfile>
</rdf:Description>
</prf:component>
Az UAProf protokoll támogatja mind a statikus, mind a
dinamikus profilokat. A statikus profil egy URI
segítségével érhető el. Ennek több előnye is van: a kliensnek a kiszolgálóhoz
küldött lekérdezése csupán egy URI leadását igényli egy bőbeszédű XML
dokumentum helyett, s ezzel csökkenthető a rádióforgalom; a felhasználó
készülékén nem szükséges tárolni és/vagy előállítani a profilt; a készülék
oldali szoftver implementációja egyszerűbb lehet. A dinamikus
profilok előállítása menetközben történik, s ezért nem kapcsolódik hozzájuk
egy URI. Ez állhat egy részprofilból is, mely csupán a statikus profilhoz
viszonyított különbséget tartalmazza, de tartalmazhat olyan
egyedülálló adatot is, mely nem szerepel a kliens statikus profiljában. A
lekérdezés tetszőleges számú statikus és dinamikus profilt tartalmazhat, de
nem közömbös a profilok leadási sorrendje, mert a későbbiek felülírják a
korábbiakat a lekérdezésben. (Az UAProf protokollról, és ezen belül
a többszörös protokoll problémájának feloldásáról további információk
találhatók a [UAPROF] dokumentumban.)
Több más közösség is definiált CC/PP alapú szókészleteket (ilyen pl. a
3GPP TS 26.234 specifikációja [3GPP] és a WAP Fórum
"Multimedia Messaging Service Client Transactions Specification" [MMS-CTR] nevű szókészlete). A CC/PP használatának
eredményeképpen egy profil élvezheti az RDF elosztott jellegének előnyeit, és
magába olvaszthat különböző szókészletekből származó komponenseket. A 46. példa egy ilyen profilt mutat be:
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:prf="http://www.wapforum.org/profiles/UAPROF/ccppschema-20010330#"
xmlns:mms="http://www.wapforum.org/profiles/MMS/ccppschema-20010111#"
xmlns:pss="http://www.3gpp.org/profiles/PSS/ccppschema-YYYYMMDD#">
<rdf:Description rdf:ID="SomeDevice">
<prf:component>
<rdf:Description rdf:ID="Streaming">
<rdf:type rdf:resource="http://www.3gpp.org/profiles/PSS/ccppschema-PSS5#Streaming"/>
<pss:AudioChannels>Stereo</pss:AudioChannels>
<pss:VideoPreDecoderBufferSize>30720</pss:VideoPreDecoderBufferSize>
<pss:VideoInitialPostDecoderBufferingPeriod>0</pss:VideoInitialPostDecoderBufferingPeriod>
<pss:VideoDecodingByteRate>16000</pss:VideoDecodingByteRate>
</rdf:Description>
</prf:component>
<prf:component>
<rdf:Description rdf:ID="MmsCharacteristics">
<rdf:type rdf:resource="http://www.wapforum.org/profiles/MMS/ccppschema-20010111#Streaming"/>
<mms:MmsMaxMessageSize>2048</mms:MmsMaxMessageSize>
<mms:MmsMaxImageResolution>80x60</mms:MmsMaxImageResolution>
<mms:MmsVersion>2.0</mms:MmsVersion>
</rdf:Description>
</prf:component>
<prf:component>
<rdf:Description rdf:ID="PushCharacteristics">
<rdf:type rdf:resource="http://www.openmobilealliance.org/profiles/UAPROF/ccppschema-20010330#PushCharacteristics"/>
<prf:Push-MsgSize>1024</prf:Push-MsgSize>
<prf:Push-MaxPushReq>5</prf:Push-MaxPushReq>
<prf:Push-Accept>
<rdf:Bag>
<rdf:li>text/html</rdf:li>
<rdf:li>text/plain</rdf:li>
<rdf:li>image/gif</rdf:li>
</rdf:Bag>
</prf:Push-Accept>
</rdf:Description>
</prf:component>
</rdf:Description>
</rdf:RDF>
Egy vételi környezet definíciója, valamint a környezeten belüli adatok
fokozatosan alakulnak ki, és állandóan változnak. Ezért az RDF természetes
bővíthetősége, és ezáltal a dinamikusan változó szókészletek támogatása
megfelelő keretet biztosít a vételi környezet kódolására.
A. függelék: További részletek
az URI-ről (az Egységes Erőforrás-azonosítóról)
Megjegyzés: Ez a szekció csak egy rövid bevezetést kíván
adni az URI-khez. Ezek definitív specifikációját megtalálhatja az olvasó az
RFC 2396 – [URIS] dokumentumban, amely tartalmazza a részleteket is.
A téma további tárgyalását nyújtja a Naming and Addressing: URIs, URLs,
... [NAMEADDRESS] dokumentum.
Mint már a 2.1 szekcióban is fejtegettük, a
webnek van egy általános formátumú azonosítója, amelyet Egységes
Erőforrás-azonosítónak (Uniform Resource
Identifier-nek, röviden URI-nek) nevezünk, és amelyet arra használunk,
hogy tipikusan webes erőforrásokat azonosítunk és nevezünk meg vele. Szemben
az URL-ekkel, az URI-k nemcsak olyan erőforrásokat azonosíthatnak, amelyek
megtalálhatók a Web egy bizonyos helyén, vagy amelyek másfajta számítógépes
hozzáférési mechanizmusokat használnak. Különböző célokra, számos különböző
URI sémát (URI formát) definiáltak már. Alább felsorolunk néhányat
ezekből:
http: (Hypertext Transfer Protocol), weblapok letöltése
számáramailto: (például: mailto:em@w3.org), e-mail címek
megjelöléséreftp: (File Transfer Protocol), letölthető fájlokat tároló
webhelyek azonosításáraurn: (Uniform Resource Names), helytől független
erőforrások tartós azonosítására (pl: az
urn:isbn:0-520-02356-0 egy könyv rögzített azonosítója)
A létező URI sémák listája megtalálható a Címzési Sémák (Addressing Schemes
– [ADDRESS-SCHEMES]) dokumentumban.
Helyesebb gyakorlat előbb végignézni ezt a listát, és adoptálni belőle egy
létező sémát, ha szükségünk van egy specializált azonosítóra, semmint
megpróbálni egy újabbat kitalálni.
Egyetlen személy vagy szervezet sem ellenőrzi, hogy ki készít URI-ket, és
hogyan használják ezeket. Amíg egyes URI sémák, mint pl. az URL-ek
http:-je, egy olyan központi rendszertől függenek, mint a DNS
(Domain-név Szerver), addig más sémák, mint pl. a freenet:,
teljes mértékben decentralizáltak. Ez azt jelenti, hogy – ugyanúgy,
mint más nevek esetén – , senkinek sincs szüksége valamiféle hivatalos
intézményre, vagy ilyennek az engedélyére, hogy kreáljon egy URI-t valaminek
a számára. Bárki kreálhat olyan URI-t is, amellyel olyan dologra hivatkozik,
ami nem a tulajdona, mint ahogy a természetes nyelvekben is használhatunk
bármilyen nevet valaminek a megnevezésére, akkor is, ha az a valami nem a
miénk.
Azt is említettük a 2.1 szekcióban, hogy az
RDF URI hivatkozásokat [URIS] (rövidítve:
URIref-eket) használ az RDF kijelentések alanyainak, állítmányainak
és tárgyainak megnevezésére. Az URI hivatkozások olyan URI-k, amelyek végére
opcionálisan odailleszthetünk egy erőforrásrész-azonosítót is. Például a
http://www.example.org/index.html#section2 URI hivatkozás
tartalmazza a http://www.example.org/index.html URI-t, valamint
(egy "#" karakterrel elválasztva az URI-től) tartalmazza a
Section2 erőforrásrész-azonosítót. Az RDF URI hivatkozásai
alkalmazhatnak [UNICODE] karaktereket (lásd [RDF-FOGALMAK]), s ennek eredményeként az URI
hivatkozásokat sok nyelven meg lehet fogalmazni.
Az URI hivatkozások lehetnek abszolútak vagy relatívak.
Egy abszolút URIref a saját kontextusától függetlenül hivatkozik egy
erőforrásra, mint például ez az URI-ref:
http://www.example.org/index.html. A relatív URIref egy abszolút
URIref rövidített változata, ahol az URIref előtét-neve (prefixe) hiányzik, s
ezért egy olyan információra van szükség az abszolút hivatkozás
előállításához, mely azonosítja az URI-ref kontextusát (azaz, a dokumentumot,
amelyben ezt definiálták). Például, amikor az otherpage.html
relatív URIref megjelenik a http://www.example.org/index.html
erőforrásban (mert történetesen ebben a dokumentumban definiálták), akkor a
relatív URI hivatkozást úgy kell kibővíteni, hogy az abszolút változata
álljon elő: http://www.example.org/otherpage.html.
Egy URIref, az URI rész nélkül, mindig arra a dokumentumra hivatkozik,
amelyben éppen előfordul. Így tehát egy üres URIref a dokumentumon belül
egyenértékűnek tekintendő magának a dokumentumnak az URIref-jével. Egy olyan
URIref, amelyik csupán egy erőforrásrész-azonosítót tartalmaz, egyenértékűnek
tekintendő egy olyan URIref-fel, mely az adott dokumentum URI-jéből és a
végéhez csatolt erőforrásrész-azonosítóból áll. Ha a #section2
relatív azonosító megjelenne pl. a
http://www.example.org/index.html dokumentumban, akkor ez az
azonosító a http://www.example.org/index.html#section2 abszolút
URIref-nek felelne meg.
Az [RDF-FOGALMAK] dokumentuma megjegyzi,
hogy az RDF gráfok (az absztrakt modellek) nem használnak relatív URI
hivatkozásokat, vagyis az alanyt, az állítmányt és a tárgyat (valamint a
tipizált literálok adattípusait) az RDF kijelentésekben mindig a kontextustól
függetlenül kell azonosítani. Azonban egy specifikus RDF szintaxis,
mint pl. az RDF/XML, bizonyos esetekben, rövidítési célokból megengedheti
relatív URI hivatkozások használatát azok abszolút változata helyett. Az
RDF/XML valóban meg is engedi a relatív hivatkozásokat, s ezek használatát
könyvünk több példájában be is mutattuk. (A további részletekért érdemes
felkeresni az [RDF-SZINTAXIS] dokumentumot.)
Mind az RDF, mind a Web-böngészők URI hivatkozásokat használnak a dolgok
azonosítására. Az RDF és a böngészők azonban némileg eltérő módon
interpretálják az ilyen hivatkozásokat. Ugyanis, az RDF csak a
dolgok azonosítására használja az URI hivatkozásokat, míg a böngészők a
visszakeresésére is. A hatás tekintetében a különbség gyakran nem lényeges,
de vannak olyan esetek, amelyekben ez a megkülönböztetés szignifikáns. Az
egyik nyilvánvaló különbség az, hogy amikor egy URI hivatkozást használunk
egy böngészőben, akkor azt várjuk, hogy ez egy olyan erőforrást azonosít,
amelyik visszakereshető: azaz, valami ténylegesen található az URIref által
azonosított helyen. Ugyanakkor az RDF-ben egy URIref használható
olyan dolog azonosítására is (mint pl. egy személy), ami/aki nem
visszakereshető a weben. Néha az RDF-et azzal a konvencióval együtt
használjuk, hogy amikor egy URI hivatkozást kijelölünk egy RDF erőforrás
azonosítására, akkor egyúttal egy olyan weblapot is elhelyezünk az általa
azonosított webhelyen, amelyben leíró információt tárolunk az adott
erőforrásról úgy, hogy ez az URIref felhasználható egy Web-böngészőben ennek
a weblapnak az elérésére. Ez a konvenció hasznos lehet bizonyos körülmények
között, azonban ez nehézséget okoz, amikor meg kell különböztetnünk az
eredeti erőforrás identitását az őt leíró weblap identitásától (ahogy ezt a
problémát a 2.3 szekcióban már bővebben
tárgyaltuk). Egy ilyen konvenció azonban nem explicit része az RDF
definíciójának, hiszen az RDF, maga, nem feltételezi, hogy egy URIref olyan
valamit azonosít, ami visszakereshető.
Egy másik különbség abban áll, ahogyan az erőforrásrész-azonosítót
tartalmazó URI hivatkozásokat kezeli az RDF és a böngésző. Gyakran láthatunk
erőforrásrész-azonosítót olyan URL-ekben, amelyek HTML dokumentumokat
azonosítanak, és amelyekben ezek egy meghatározott részt jelölnek meg a
dokumentumon belül. A szokásos HTML használatban, ahol URI hivatkozásokat
használnak a megjelölt erőforrások visszakeresésére, az alábbi két URIref:
http://www.example.org/index.html
http://www.example.org/index.html#Section2
összefügg egymással (mindkettő ugyanarra a dokumentumra hivatkozik úgy,
hogy a második egy helyet azonosít az elsőn belül). Az RDF azonban, mint már
jeleztük, pusztán csak az erőforrások azonosításra használja az URI
hivatkozásokat, de nem a visszakeresésükre, és így nem is tételez fel
semmilyen konkrét összefüggést e két URIref között. Az RDF szempontjából ezek
szintaktikalag különböző URI hivatkozások, azaz teljesen független dolgokra
hivatkozhatnak. Ez nem jelenti azt, hogy a HTML által definiált tartalmazási
reláció nem létezhet közöttük, hanem csak azt, hogy az RDF nem
feltételezi, hogy létezik ilyen összefüggés, csak mert a két hivatkozás
URI része megegyezik.
Még tovább mélyítve ezt a témát, az RDF nem feltételezi, hogy bármilyen
összefüggés van az olyan URI hivatkozások között, amelyek ugyanazzal a
karakterlánccal kezdődnek, akár van bennük erőforrásrész-azonosító, akár
nincs. Például az RDF szempontjából az alábbi két URIref:
http://www.example.org/foo.html
http://www.example.org/bar.html
nem áll semmilyen konkrét összefüggésben egymással, annak ellenére sem,
hogy mindkettő a http://www.example.org/ karakterlánccal
kezdődik. Az RDF számára ez csupán két különböző erőforrás, minthogy az URI
hivatkozásuk különböző. (Ténylegesen, ez a két fájl lehet akár ugyanabban a
mappában is, de az RDF nem feltételezi ezt, és azt sem, hogy bármi más
összefüggés lenne közöttük.)
B. függelék: További részletek az
XML-ről (a Bővíthető Jelölőnyelvről)
Megjegyzés: ez a szekció csupán egy rövid bevezetést
kíván nyújtani az XML-hez. Az XML definitív specifikációját az [XML] dokumentum tartalmazza, mely a részletek
tekintetében további felvilágosítással szolgál.
Az XML-t, a Bővíthető Jelölőnyelvet (Extensible Markup
Language – [XML]) arra tervezték, hogy
bárkinek lehetővé tegyék saját dokumentumformátumok tervezését, majd pedig
ilyen formátumú dokumentumok írását. Ugyanúgy, mint a HTML dokumentumok
(weblapok), az XML dokumentumok is szöveget tartalmaznak. Ez a szöveg
elsősorban nyílt szövegrészekből és tegek formájában megadott
jelölésekből áll. Az ilyen jelölések lehetővé teszik a feldolgozó
programoknak, hogy értelmezzék a tartalom különböző darabjait, amelyeket
elemeknek hívunk. Mind az XML tartalom, mind pedig a tegek (ez
utóbbiak csak bizonyos kivételekkel) tartalmazhatnak [UNICODE] karaktereket, s ez lehetővé teszi, hogy sok
nyelven közvetlenül is leírhassuk az információinkat. A HTML esetében a
megengedett tegeket és ezek interpretációját a HTML specifikáció tartalmazza.
Ezzel szemben az XML lehetővé teszi a felhasználóknak, hogy (tegek és ezek
struktúrái formájában) olyan, saját jelölőnyelvet definiálhassanak, mely
alkalmazkodik a saját igényeikhez (a 3. fejezetben
leírt RDF/XML is egy ilyen jelölőnyelv). Például a következő egyszerű mondat:
I just got a pet dog ("Éppen az imént kaptam egy kiskutyát")
egyes részeihez (I és dog) XML alapú jelölőnyelv
segítségével csatoltunk géppel értelmezhető jelentést:
<sentence><person webid="http://example.com/#johnsmith">I</person>
just got a new pet <animal>dog</animal>.</sentence>
A tegek által határolt elemeket (<sentence>,
<person> stb.) azért vezettük be, hogy egy meghatározott
struktúrát alkossanak a mondaton belül. Ezek a tegek lehetővé teszik, hogy
egy program – amelyet úgy írtak meg, hogy értse ezeknek a jelentését,
valamint felismerje azt a struktúrát, amelyben megjelennek – helyesen
értelmezze ezt a mondatot. Ebben az elemek egyike az
<animal>dog</animal>. Ez tartalmaz egy
nyitóteget: <animal> (állat) az elem
tartalmát: dog (kutya) és egy, a nyitóteggel azonos
nevű záróteget (</animal>). Ez az
animal elem a person (személy) elemmel együtt bele
van ágyazva a sentence (mondat) elem tartalmába, annak
részeként. Ez a beágyazás jóval átláthatóbb lenne (és közelebb lenne a
tankönyvünkben használt strukturáltabb ábrázolásokhoz is), ha így írnánk
fel:
<sentence>
<person webid="http://example.com/#johnsmith">I</person>
just got a new pet
<animal>dog</animal>.
</sentence>
Lehetnek olyan esetek, amikor egy elemnek nincs tartalma. Ezt jelölhetjük
úgy, hogy nem írunk semmit az elem nyitó- és zárótegje közé (pl.
<animal></animal>), vagy jelölhetjük úgy is, hogy a
tegnek egy rövidített formáját használjuk, amelyet üres elem tegnek
nevezünk (pl. <animal/>).
Egyes esetekben a nyitóteg (vagy az üres elem teg) tartalmazhat minősítő
információt is a teg neve mellett. Ezt attribútumnak nevezzük.
Például a <person> elem nyitótegje a
webid="http://example.com/#johnsmith" attribútumot tartalmazza
(nyilván annak a konkrét személynek az azonosítóját, akire hivatkozik). Az
attribútum egy névből, egy egyenlőségjelből és egy értékből áll (ez utóbit
idézőjelek közé írjuk).
Ez a konkrét jelölőnyelv a "sentence", a "person" és az "animal" szavakat
használja tegnévként, amelyekkel megpróbálja átvinni az egyes elemek
specifikus jelentését vagy egy angolul beszélő személynek, aki olvassa, vagy
egy olyan programnak, amelyet kifejezetten úgy írtak meg, hogy értelmezni
tudja ezt a kis szókészletet. Azonban mégsem beszélhetünk itt beépített
jelentésről. Ugyanis, egy angolul nem tudó személynek, vagy egy olyan
programnak, amelyet nem úgy írtak meg, hogy értse ezt a jelölőnyelvet, semmit
sem mond pl. a <person> elem. Tekintsük példának a
következő XML részletet:
<dfgre><reghh bjhbw="http://example.com/#johnsmith">I</reghh>
just got a new pet <yudis>dog</yudis>.</dfgre>
Egy gép számára ez a részlet sem többet, sem kevesebbet nem mond annál,
amit az előbbi példa mondott. Most már azonban egy angolul beszélő számára
sem világos, hogy ez mit közöl, mivel a tegek itt nem angol nyelvű szavak. De
lehetnének ebben a mondatban akár ugyanazok az angol szavak is, mint az előző
példában; ha egy másik jelölőnyelvben egészen más jelentést tulajdonítanának
nekik, a mondat akkor is érthetetlen lenne a számunkra. Például a "sentence"
kifejezés egy másik jelölőnyelvben (mondjuk, egy börtön környezetében)
jelölhetné azt az időtartamot, amelyet egy bűnözőnek le kell ülnie (minthogy
a szó másik jelentése: "büntetés"). Ezért tehát további kisegítő
mechanizmusokra van szükségünk ahhoz, hogy egy XML szókészlet egyértelműségét
biztosan fenntarthassuk.
Hogy megelőzzük a félreértéseket, szükséges, hogy egyértelműen azonosítsuk
a jelölőelemeket. Ezt az XML névterek (XML Namespaces – [XML-NS]) segítségével valósíthatjuk meg. A
névtér egy olyan módszer, amellyel azonosíthatjuk a Web
(információterének) egy részét, a névtér neve pedig egy olyan minősítő név,
mely megjelöli a nevek egy meghatározott halmazát (a névtér elemeit). A
névteret úgy állítjuk elő egy XML jelölőnyelv számára, hogy hozzárendelünk
egy URI-t. Bárki kreálhat magának saját tegeket, ha ezeket a saját névterének
a nevével minősíti (prefixeli), hiszen ezeket így már egyértelműen meg lehet
különböztetni azoktól nevektől, amelyeket mások használnak, akkor is, ha
netán azokkal homonim nevek lennének (vagyis, azonos szavakat tartalmaznának,
de más jelentésben). Néha azt a konvenciót követik, hogy készítenek egy
weblapot, amelyben definiálják a jelölőnyelvet (illetve leírják a tegek
szándékolt jelentését), és ennek a weblapnak az URL-jét használják a nyelv
szókészletét átfogó névtérnek az azonosítására. Ez azonban csupán egy
konvenció, ugyanis sem az XML, sem az RDF nem tételezi fel, hogy a névtér-URI
egy visszakereshető webforrást azonosít. Az alábbi példa illusztrálja egy XML
névtér használatát:
<user:sentence xmlns:user="http://example.com/xml/documents/">
<user:person user:webid="http://example.com/#johnsmith">I</user:person>
just got a new pet <user:animal>dog</user:animal>.
</user:sentence>
Ebben a példában a
xmlns:user="http://example.com/xml/documents/" attribútum
deklarálja a névteret ehhez a kis XML részlethez. Ez az attribútum a
user prefixre képezi le a
http://example.com/xml/documents/ névtér-URI-t. Az XML tartalom
ezután már ilyen minősített nevet (qualified name vagy
QName) használhat tegként, mint pl. user:person. Egy
minősített név egy prefixszel (előtét-névvel) kezdődik, mely egy névteret
azonosít; ezt egy kettőspont karakter, majd pedig egy olyan helyi név követi,
mely egy XML teget vagy egy attribútumot nevez meg. Az az eljárás, hogy
névtér-URI-ket használunk a nevek egyes csoportjainak megkülönböztetésére,
valamint az a megoldás hogy a tegeket azoknak a névtereknek az URI-jével
minősítjük, ahonnan ezek a tegek származnak (mint ebben a példában is
tettük), biztosítja azt, hogy nem kell tartanunk az esetleges
név-ütközésektől. Ugyanis két teg, vagy két kifejezés, amelyet ugyanúgy
írunk, csak akkor számít azonosnak, ha a névtér-URI-jük is azonos.
Minden XML dokumentumnak "jól formáltnak" (well-formed) kell
lennie. Ez azt jelenti, hogy egy XML dokumentumnak ki kell elégítenie egy sor
szintaktikai feltételt: például, hogy minden nyitóteghez egy megfelelő
zárótegnek kell tartoznia, és az elemeket helyesen kell beágyazni más
elemekbe (az elemek pl. nem lapolhatják át egymást). A jól formáltság
komplett feltételrendszerét az [XML] specifikáció
definiálja.
A fentebb említett alkotóelemek mellett, egy XML dokumentum opcionálisan
tartalmazhat egy dokumentumtípus-deklarációt (document type
declaration), amelyben további korlátozásokat lehet definiálni a
dokumentum szerkezetére vonatkozóan, és amely támogatja előre definiált
kifejezések használatát a dokumentumon belül. A dokumentumtípus-deklaráció
(mely egy DOCTYPE teggel kezdődik) tartalmazza azokat a
deklarációkat – vagy az ilyen deklarációkra mutató hivatkozásokat
– amelyek egy nyelvtant definiálnak a dokumentum számára. Ezt a
nyelvtant dokumentumtípus-definíciónak (document type definition),
röviden DTD-nek hívjuk. A DTD-ben szereplő deklarációk ilyen dolgokat
specifikálnak, mint hogy milyen XML elemek és attribútumok jelenhetnek meg
egy olyan dokumentumban, mely megfelel ennek a DTD-nek, és hogy milyen
viszony áll fenn ezek között az elemek és attribútumok között (pl., hogy mely
elemeket ágyazhatunk be más elemekbe, vagy hogy milyen elemekben, milyen
attribútumok jelenhetnek meg), továbbá, hogy az egyes elemek kötelezőek-e,
vagy csak opcionálisak. A dokumentumtípus-deklaráció hivatkozhat olyan
deklarációk halmazára is, amelyek a dokumentumon kívül helyezkedhetnek el.
Ezeket külső részhalmazoknak (external subsets) nevezzük, és arra
szolgálnak, hogy lehetővé tegyék több dokumentum DTD-je számára a közös
deklarációk használatát. A dokumentumtípus-deklaráció azonban tartalmazhatja
a deklarációkat közvetlenül a dokumentumban is – ezeket belső
részhalmazoknak (internal subset) hívjuk, de magába építhet külső
és belső részhalmazokat is. Egy dokumentum teljes DTD-je e két részhalmaz
összességéből áll. A 47. példa egy
dokumentumtípus-deklarációval rendelkező, egyszerű XML dokumentumot mutat
be:
<?xml version="1.0"?>
<!DOCTYPE greeting SYSTEM "http://www.example.org/dtds/hello.dtd">
<greeting>Hello, world!</greeting>
Ebben az esetben a dokumentumnak csak egy külső DTD részhalmaza van,
amelynek a helyét a http://www.example.org/dtds/hello.dtd
rendszer-azonosító (system identifier) URIref jelöli meg.
Egy dokumentum akkor számít érvényes (valid) XML dokumentumnak,
ha rendelkezik egy dokumentumtípus-deklarációval, és a dokumentum megfelel
azoknak a korlátozásoknak, amelyek ebben a deklarációban szerepelnek.
Egy RDF/XML dokumentumnak azonban elég csak jól formált XML-nek kell
lennie; ezt nem szükséges érvényesség-ellenőrzésnek alávetni (validáltatni)
valamilyen XML DTD, vagy valamilyen XML séma alapján. Az [RDF-SZINTAXIS] nem is specifikál egy normatív
DTD-t, ami használható lenne egy tetszőleges RDF/XML kód validációjára (az [RDF-SZINTAXIS] dokumentum függeléke nyújt azonban
egy nem-normatív, példa jellegű sémát az RDF/XML számára). Ezért az XML DTD
nyelvtanok részletesebb tárgyalása már kívül esik a tankönyvünk tárgykörén. A
DTD nyelvtanokról, valamint az XML validációjáról további információk
találhatók az [XML] specifikációban, valamint az
XML-ről megjelent számos könyvben.
Van azonban egy olyan alkalmazása az XML dokumentumtípus-deklarációknak,
mely érvényes az RDF/XML-re is, és ez az XML entitások
deklarálása. Egy XML entitásdeklaráció lényegében egy nevet kapcsol egy
karakterlánchoz. Amikor ezt a nevet később az XML dokumentumban használjuk,
akkor az XML processzorok behelyettesítik azt a megfelelő karakterlánccal. Ez
lehetőséget teremt a hosszú karakterláncok (pl. az URI hivatkozások)
rövidítésére, és így, az ilyeneket tartalmazó XML dokumentumok ember általi
olvashatóságának a javítására. A dokumentumtípus-deklarációknak kizárólag XML
entitások deklarálására való használata teljesen legális, és hasznos lehet
akkor is, ha (mint pl. az RDF/XML-ben) a dokumentumot nem kívánjuk XML
validációnak alávetni.
RDF/XML használatakor az entitásokat általában magában a dokumentumban
deklaráljuk egy belső DTD részhalmaz megadásával. Ennek egyik oka az, hogy
mivel az RDF/XML-t nem szükséges validáltatni, így nem-validáló XML
processzort használhatunk, és az ilyen processzort így nem kell felkészíteni
külső DTD részhalmazok elemzésére. Például, ha elhelyezzük a 48. példában látható DTD-t egy RDF/XML dokumentum
elejére, akkor ez lehetővé teszi, hogy azokat az URI hivatkozásokat,
amelyeket pl. az rdf, az rdfs és az
xsd névterek megjelölésére használunk, ilyen nevekkel
rövidítsük, mint: &rdf; &rdfs; és
&xsd; ahogyan a példa is mutatja:
<?xml version='1.0'?>
<!DOCTYPE rdf:RDF [
<!ENTITY rdf "http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<!ENTITY rdfs "http://www.w3.org/2000/01/rdf-schema#">
<!ENTITY xsd "http://www.w3.org/2001/XMLSchema#">
]>
<rdf:RDF
xmlns:rdf = "&rdf;"
xmlns:rdfs = "&rdfs;"
xmlns:xsd = "&xsd;">
...RDF statements...
</rdf:RDF>